1.
Introduction ^
2.
Background and Related Work ^
3.
Research Motivation ^
- Retrieve the document(s) (and their specific parts) where the theme is generally about public health, while also talking about European standard
- Retrieve the documents and their parts where the general topic is about public health in relation to animal feed
- Retrieve the specific part(s) of a document that talks about European standards on animal feed in relation to public health.
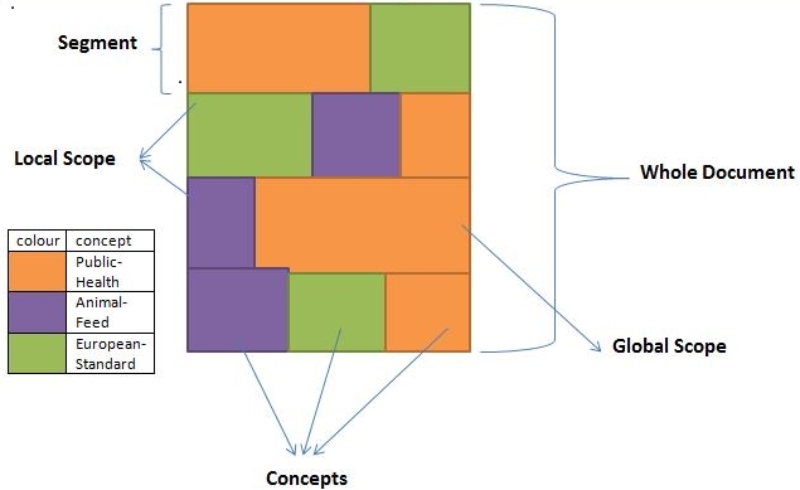
This makes information filtering very advanced, for instance if a document talks about Animal feed but not in the context of European standards then it becomes irrelevant for the third query above and it is not retrieved. Also, if for example we have two documents A and B, with A having concepts Public-Health (X), Animal-Feed (Y) and European-Standard (Z) while B contains only concepts Public-Health (X) and Animal-Feed (Y) without European-Standard. Then as a proof of concept, queries5 of the form «SELECT FROM corpus WHERE concept = X, Y AND NOT concept = Z» can make a distinction between these concept overlaps and retrieve only document A while leaving out document B, even though it contains two of the mentioned concepts.
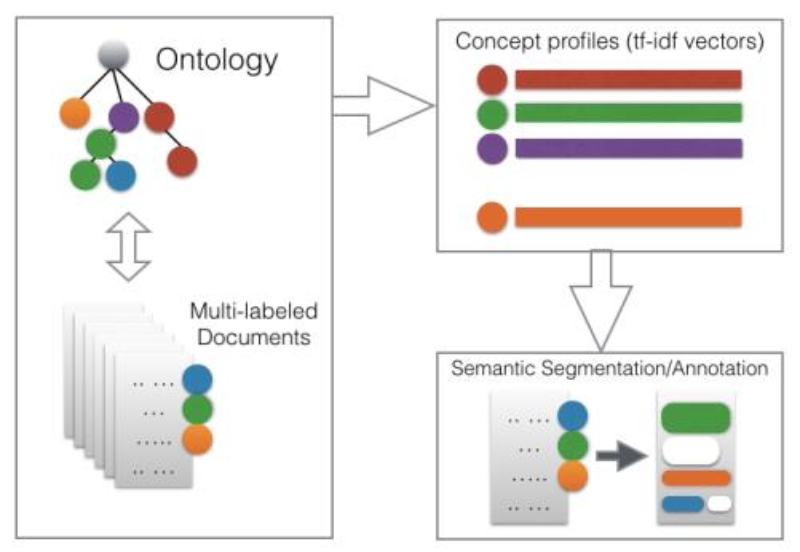
- Create concept profiles by looking at frequent and discriminant words calculated over texts-to-concepts occurrences (using TF-IDF).
- Parse the text segment, sentence by sentence, calculating the similarity of each sentence with the concept profiles. Taking ideas from existing research on text segmentation such as TextTiling [13] which was improved in [14] and topic modeling [15] as well as TextRank [20], we identify the following flags in the text: (a) when the text in a block starts talking about a concept, (b) when it stops talking about the concept, and (c) when it starts talking about a new concept. Reference [16] contains a detail review of text segmentation approaches for the reader’s interest.
- Perform concept association, which maps a contiguous text block to a semantic concept that literarily gives a summary of its content.
- Identify the global and local scopes of the concepts in a document by analyzing how the related concept block overlaps.
4.
Methodology ^
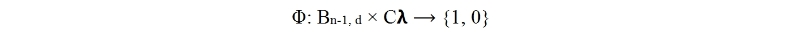
that describes the conceptual mapping of a text segment. Where Bn-1, d is a block or segment of text in a document d and n is a unique incremental number assigned as the identifier for each block. Cλ is a set of concepts according to a specified ontology. The goal is to find

Such that Cλi ≡ Bi,d, that is, we want to have a mapping of a block to a concept successfully such that each block is associated to its concept6. The equivalence relation above ensures that a concept is attached to one or more blocks of a document d. It is possible for text blocks to share same concept as well as a single block being labeled by more than one concept.
The first step is the creation of concept profiles, i.e., numeric vectors representing the contextual meaning of the concepts calculated through a TF-IDF weighting scheme over the concept-term matrix (which is built on the basis of the input multi-labeled document collection). This way, each concept Cp is associated to a vector vp where 0 < p <= |σ|. Then, considering each text ti as a sequence, Seqi = < s1, s2…..sk > of sentences s, the idea is to label each sentence with zero or one element belonging to the set of concepts σ.
This automatic segmentation/annotation of a text ti is done as follows:
- Parse the sequence of sentences Seqi, then
For each Sj in Seqi, calculate the cosine similarity between the frequency vector of Sj and each concept vector as below:
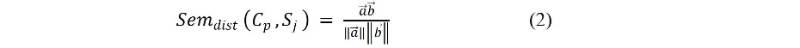
Where

Such that a represents the vector of concept Cp with b representing the vectors of Sj in the text block.
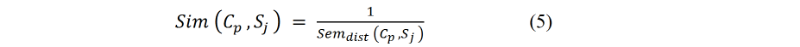
- If the similarity between a concept cp and a sentence sj is z times higher7 than the rest of concept-to-sentence similarities, then sj is associated to cp, otherwise the sentence is not associated to any concept. The parameter z is a predetermined threshold value strictly for decision making. While this value can be varied, it is set to 2 by default, making it possible for a sentence to be mapped to its most similar concept.
- Finally, semantically-contiguous sentences (i.e., sentences which are contiguous and associated to a single concept) will represent semantically-coherent segments, which are the final result of the in-text concept annotation task.
- In case the method returns an empty set of segments or an incomplete coverage of the concepts associated to the text ti, it restarts by step 1 with z = z/2.
4.1.
Concept Analysis ^

4.2.
Concept Zoning for Text Segmentation ^
4.3.
Concept-Document Mapping ^
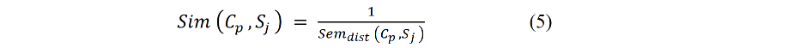
For each of the segment, the system iterates over all the term-document vectors of the expanded lexicon of each concept, measuring the distance. Similar vectors imply some level of relatedness between the concept and the segment and such segment is tagged with the concept.
5.
Evaluation ^
- Conceptual Tagging: This task measures the performance of the system in correctly labeling a text segment with a concept. EurLex documents are pre-classified with some concepts. We required a volunteer to identify and manually annotate portions of the text that talks about each concept classified for each document. We measured the performance of the system against annotations from human judgment and got an accuracy of 62%.
6.
Conclusion ^
7.
References ^
[1] EDRM, Electronic Discovery Reference model, http://www.edrm.net.
[2] The 2008 Socha-Gelbmann Electronic Survey Report (2008). http://www.sochaconsulting.com/2008survey.php.
[3] Popov, B., Kiryakov, A., Kirilov, A., Manov, D., Ognyanoff, D., & Goranov, M. (2003). KIM–semantic annotation platform. In The Semantic Web-ISWC 2003 (pp. 834–849). Springer Berlin Heidelberg.
[4] Kiyavitskaya, N., Zeni, N., Mich, L., Cordy, J. R., & Mylopoulos, J. (2006). Text mining through semi automatic semantic annotation. In Practical Aspects of Knowledge Management (pp. 143–154). Springer Berlin Heidelberg.
[5] Asooja, K., Bordea, G., Vulcu, G., O’Brien, L., Espinoza, A., Abi-Lahoud, E., & Butler, T. (2014). Semantic Annotation of Finance Regulatory Text using Multilabel Classification.
[6] Daelemans, W., & Morik, K. (eds.). (2008). Machine Learning and Knowledge Discovery in Databases: European Conference, Antwerp, Belgium, September 15–19, 2008, Proceedings (Vol. 5212). Springer.
[7] Buabuchachart, A., Metcalf, K., Charness, N., & Morgenstern, L. (2013). Classification of Regulatory Paragraphs by Discourse Structure, Reference Structure, and Regulation Type. In JURIX (pp. 59–62).
[8] Bikakis, N., Giannopoulos, G., Dalamagas, T., & Sellis, T. (2010). Integrating keywords and semantics on document annotation and search. In On the Move to Meaningful Internet Systems, OTM 2010 (pp. 921–938). Springer Berlin Heidelberg.
[9] Laclavík, M., Ciglan, M., Seleng, M., & Krajei, S. (2007). Ontea: Semi-automatic pattern based text annotation empowered with information retrieval methods. Tools for acquisition, organisation and presenting of information and knowledge: Proceedings in Informatics and Information Technologies, Kosice, Vydavatelstvo STU, Bratislava, part, 2 (pp. 119–129).
[10] Laclavik, M., Seleng, M., Gatial, E., Balogh, Z., & Hluchy, L. (2007). Ontology based text annotation-OnTeA. Frontiers in Artificial Intelligence and Applications (pp. 154, 311).
[11] Handschuh, S., & Staab, S. (2002). Authoring and annotation of web pages in CREAM. In Proceedings of the 11th international conference on World Wide Web (pp. 462–473). ACM.
[12] Dill, S., Eiron, N., Gibson, D., Gruhl, D., Guha, R., Jhingran, A., & Zien, J. Y. (2003). A case for automated large-scale semantic annotation. Web Semantics: Science, Services and Agents on the World Wide Web (pp. 115–132).
[13] Hearst, M. A. (1993). TextTiling: A quantitative approach to discourse segmentation. Technical report, University of California, Berkeley, Sequoia.
[14] Hearst, M. A. (1997). TextTiling: Segmenting text into multi-paragraph subtopic passages. In Computational linguistics 23, no. 1 (1997): 33–64.
[15] Riedl, M. & Biemann C. (2012). Text segmentation with topic models. In Journal for Language Technology and Computational Linguistics 27, no. 1 (2012): 47–69.
[16] Lloret, E. (2009). Topic Detection and Segmentation in Automatic Text Summarization. In Focus Journal.
[17] Clark, S. (2014). Vector space models of lexical meaning (to appear). In Handbook of Contemporary Semantics. Wiley-Blackwell, Oxford.
[18] Turney, P. D. & Pantel, P. (2010). From Frequency to Meaning: Vector Space Models of Semantics. In Journal of Artificial Intelligence Research 37 (pp. 141–188).
[19] Pantel P., Lin D. (2002). Discovering word senses from text. In Proc 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 613–619). Edmoton, Canada.
[20] Mihalcea, R., & Tarau, P. (2004). TextRank: Bringing order into texts. Association for Computational Linguistics.
[21] Hartigan, J. A., & Wong, M. A. (1979). Algorithm AS 136: A k-means clustering algorithm. In Applied statistics (1979): 100–108.
[22] Kanungo, T., Mount, D. M., Netanyahu, N. S., Piatko, C. D., Silverman, R. & Wu, A. Y. (2002). An efficient k-means clustering algorithm: Analysis and implementation. In Pattern Analysis and Machine Intelligence, IEEE Transactions on 24, no. 7 (2002): 881–892.
- 1 Eurovoc is available at http://eurovoc.europa.eu.
- 2 Wordnet is Available at https://wordnet.princeton.edu/.
- 3 Throughout the paper, we interchangeably use the words segment and block to mean the same thing. Also, concept and class are used interchangeably.
- 4 We take idea of zoning from the work of Teufel, S. (1999). Argumentative Zoning: Information Extraction from Scientific Text, which divides scientific papers into different sections called zones.
- 5 The querying methodology is just a proof of concept and not implemented in this work.
- 6 i signifies an iterative number, incrementing over the sets of concepts and blocks in a document d.
- 7 Unique parameter of the method
- 8 Take for instance public-health which can be dissolved into public and health.
- 9 Available at http://eur-lex.europa.eu/content/welcome/about.html.





