1.
Introduction ^
2.
Problem Statement ^
This paper aims to unveil implicit and explicit network structures in legal texts, more specifically German law texts. Network structures can be found throughout the legal system and legislation and are essential for the understanding of norms (articles). This approach narrows the broad network perspective to two basic network structures, namely the network structure induced by explicit references within law texts and that induced by semantic relatedness of norms. Within this work we will show both structures by automatically determining them using algorithms for text mining (see Section 4). This works investigates the BGB in its consolidated version from 30. April 2014 in German language. It would essentially also be possible to expand the network analysis to a larger dataset or to include court judgments, but to show and compare the two evolving network structures, the BGB with more than 2000 norms and over 150 000 words is sufficient. Moreover, the BGB is strongly hierarchically structured into 5 books and several levels of subchapters.
| #norms | #words | #nouns | #unique nouns | Ø words per norm | Ø nouns per norm |
| 2382 | 153662 | 50517 | 3920 | 64,5 | 21,2 |
3.
Related Work ^
4.
Reference Structure in Legal Texts ^


5.
Case Study: BGB ^

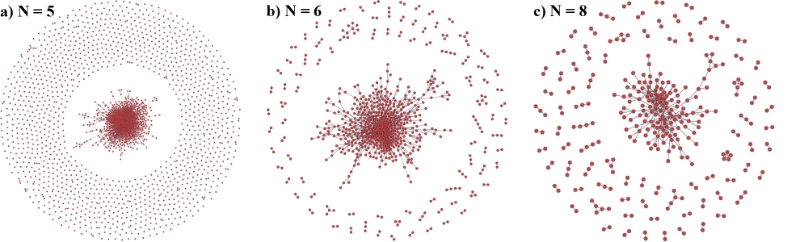
As expected, the number of isolated norms increases with a larger threshold N, while the number of edges (and hence also the degree of nodes and the number of connected norms) drops. The size of the largest connected component drops with larger threshold values N, too.
| N | CN | IN | LC | TE | MO | CE | P |
| 0 | 2382 | 0 | 2382 | 2835771 | 2381 | 2984 | 0.1 |
| 1 | 2379 | 3 | 2379 | 586726 | 1706 | 2255 | 0.4 |
| 2 | 2312 | 70 | 2312 | 143516 | 952 | 1473 | 1 |
| 3 | 2073 | 309 | 2064 | 36396 | 516 | 926 | 2.5 |
| 4 | 1597 | 785 | 1530 | 10650 | 274 | 584 | 5.5 |
| 5 | 1099 | 1283 | 972 | 3862 | 151 | 370 | 9.6 |
| 6 | 747 | 1635 | 524 | 1596 | 80 | 238 | 15 |
| 7 | 501 | 1881 | 280 | 792 | 49 | 157 | 20 |
| 8 | 331 | 2051 | 140 | 387 | 30 | 89 | 23 |
| 9 | 213 | 2169 | 77 | 209 | 19 | 58 | 28 |
| 10 | 140 | 2242 | 52 | 123 | 13 | 46 | 37 |
| 11 | 107 | 2275 | 35 | 81 | 8 | 33 | 41 |
| 12 | 77 | 2305 | 22 | 55 | 7 | 19 | 35 |

6.
Limitations and Future Work ^
7.
Summary ^
8.
References ^
Adedjouma, Morayo/Sabetzadeh, Mehrdad/Briand, Lionel C., Automated detection and resolution of legal cross references: Approach and a study of Luxembourg’s legislation. In: Requirements Engineering Conference (RE), 2014 IEEE 22nd International, 2014, p. 63–72.
Agnoloni, Tommaso/Pagallo, Ugo, The case law of the Italian constitutional court, its power laws, and the web of scholarly opinions. In: Katie Atkinson und Ted Sichelman (Hg.): the 15th International Conference, San Diego, California 2014, p. 151–155.
Atkinson, Katie, ICAIL 2015: Proceedings of the 15th International Conference on Artificial Intelligence and Law (2015). New York, NY, USA, 2015.
Bommarito II, Michael J./Katz, Daniel M., A mathematical approach to the study of the United States Code. In: Physica A: Statistical Mechanics and its Applications 389 (19), 2010, p. 4195–4200.
Bommarito II, Michael J./Katz, Daniel/Zelner, Jon, Law as a seamless web? comparison of various network representations of the United States Supreme Court corpus (1791-2005). In: Proceedings of the 12th International Conference on Artificial Intelligence and Law. Barcelona, Spain 2009, p. 234–235.
Hoekstra, Rinke, Legal Knowledge and Information Systems: JURIX 2014: The Twenty-Seventh Annual Conference: IOS Press (Frontiers in artificial intelligence and applications), 2014.
Merkl, Dieter/Schweighofer, Erich, En route to data mining in legal text corpora: Clustering, neural computation, and international treaties. In: Database and Expert Systems Applications, 1997. Proceedings., Eighth International Workshop on. IEEE, 1997, p. 465–470.
Lu, Qiang/Conrad, Jack G./Al-Kofahi, Khalid/Keenan, William, Legal document clustering with built-in topic segmentation. In: Proceedings of the 20th ACM international conference on Information and knowledge management. ACM, 2011, p. 383–392.
Salton, Gerard M/Wong, Andrew/Yang, Chungshu, A vector space model for automatic indexing. Commun. ACM 18, 1975, p. 613-620, 1975.
Schweighofer, Erich/Merkl, Dieter, A learning technique for legal document analysis. In: Proceedings of the 7th International Conference on Artificial Intelligence and Law, Oslo, Norway, 1999, p. 156–163.
Waltl, Bernhard/Matthes, Florian, Towards Measures of Complexity: Applying Structural and Linguistic Metrics to German Laws. In: Jurix 2014: Legal Knowledge and Information Systems, 2014.
Winkels, Radboud/Boer, Alexander/Vredebregt, Bart/van Someren, Alexander, Towards a Legal Recommender System. In: Frontiers in Artificial Intelligence, Volume 271: Legal Knowledge and Information Systems, 2014, p. 169–178.
- 1 Neo Technologies, Neo4j System Properties. http://db-engines.com/de/system/Neo4j (accessed on 7 November 2015), 2015.
- 2 German Civil Code BGB, http://www.gesetze-im-internet.de/englisch_bgb/englisch_bgb.html, accessed on 24 November 2015.
- 3 Apache UIMA, https://uima.apache.org/, accessed on 24 November 2015.
- 4 Apache UIMA Ruta, https://uima.apache.org/ruta.html, accessed on 24 November 2015.
- 5 Pattern.de POS-Tagger, http://www.clips.ua.ac.be/pages/pattern-de, accessed on 4 December 2015.
- 6 NLTK 3.0 Documentation, Snowball Stemmer, http://www.nltk.org/api/nltk.stem.html, accessed on 4 December 2015.





