1.
Motivation ^
Ein Beispiel aus dem österreichischen Mietrechtsgesetz (MRG) zeigt die beschriebenen Schwierigkeiten auf: «§ 6. (1) Unterläßt der Vermieter durchzuführende Erhaltungs- oder Verbesserungsarbeiten, so hat ihm das Gericht (die Gemeinde, § 39) auf Antrag die Vornahme der Arbeiten binnen angemessener, ein Jahr nicht übersteigender Frist aufzutragen. Sind darunter Arbeiten, die nach § 3 Abs. 3 Z 2 lit. a bis c vorweg durchzuführen sind, so ist die Durchführung dieser Arbeiten vorweg aufzutragen; hinsichtlich solcher Arbeiten gilt Abs. 4 nicht. Zur Antragstellung sind berechtigt
- die Gemeinde, in der das Haus gelegen ist, im eigenen Wirkungsbereich und jeder Hauptmieter des Hauses hinsichtlich der im § 3 Abs. 2 Z 1 bis 4 und 6 genannten Erhaltungsarbeiten,
- die Mehrheit der Hauptmieter – berechnet nach der Anzahl der Mietgegenstände – des Hauses hinsichtlich der im § 3 Abs. 2 Z 5 genannten Erhaltungsarbeiten und der nützlichen Verbesserungen nach Maßgabe des § 4 Abs. 1 und 2 [...]».
2.
Grundlagen ^
2.1.
Syntax und Semantik in der Modellierung ^
Eine Modellierungsmethode ist nach Karagiannis und Kühn [2002] in zwei Komponenten geteilt: die Modellierungstechnik und den Mechanismen und Algorithmen. Dabei beinhaltet die Modellierungstechnik eine Modellierungssprache, bestehend aus der Notation, Syntax und Semantik, und eine Vorgehensweise. Diese Komponenten und deren Beziehungen zueinander sind in Abbildung 1 dargestellt.
![Abbildung 1: Komponenten von Modellierungsmethoden [Karagiannis/Kühn 2002]](/magnoliaAuthor/.imaging/stk/jusletterit/zoom/dam/publicationsystem/articles/Jusletter-IT/2017/IRIS/eine-modellierungsme_adfd1de762/images/393330377Bild6.png/jcr:content/393330377Bild6.png.jpg.jpg)
2.2.
Algorithmen zur automatischen Generierung von Modellen ^
2.3.
Das österreichische Rechtsinformationssystem ^
3.1.
Metamodell der Methode ^
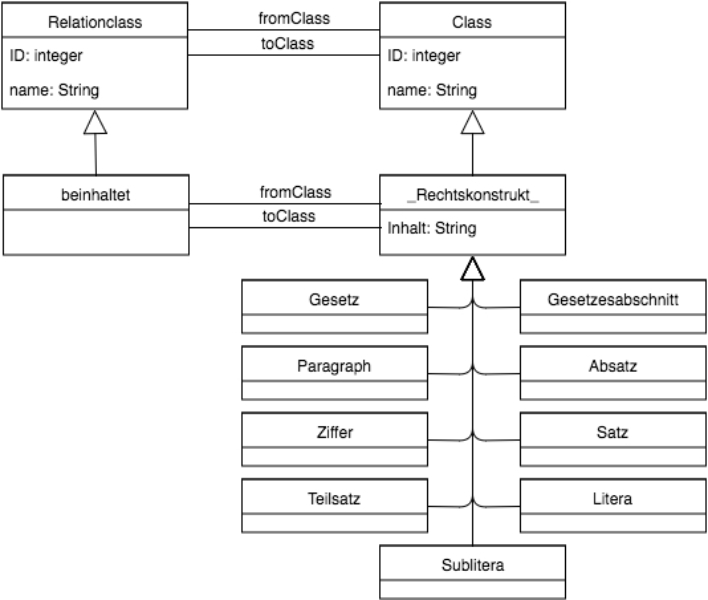
Eine semi-formale Herangehensweise ermöglicht es, die Syntax der Modellierungssprache durch ein Metamodell und dessen Semantik in natürlicher Sprache zu definieren. Das Metamodell enthält die in einem Modell möglichen Elemente und ihre Relationen zueinander und ist in Abbildung 2 dargestellt.
3.2.
RIS-XML als Ausgangsformat ^
3.3.
Konzepte zur Satzgrenzenerkennung ^
Im Zuge der Analyse wurde zur Ermittlung der notwendigen regulären Ausdrücke für das österreichische Recht ein Beispielgesetz herangezogen. Dabei handelt es sich um das Mietrechtsgesetz (MRG). Die Analyse ergab zehn Satzmuster, welche in der folgenden Tabelle enthalten sind.
| Nr. | Muster | Regulärer Ausdruck | Anzahl |
| 1 | kleiner Buchstabe[.] (incl. ß) | [a-zß][.] | 235 |
| 2 | kleiner Buchstabe[.] Leerzeichen großer Buchstabe (incl. Umlaute) | [a-zß][.] [A-ZÜÖÄ] | 214 |
| 3 | Zahl[.] | [1-9][.] | 8 |
| 4 | kleiner Buchstabe[:] (incl. ß) | [a-zß][:] | 6 |
| 5 | Zahl[.] Leerzeichen großer Buchstabe | [1-9][.] [A-ZÜÖÄ] | 4 |
| 6 | kleiner Buchstabe[.] Leerzeichen [§] | [a-zß][.] [§] | 4 |
| 7 | großer Buchstabe[.] Leerzeichen großer Buchstabe | [A-ZÜÖÄ][.] [A-ZÜÖÄ] | 3 |
| 8 | großer Buchstabe[)][.] | [A-ZÜÖÄ][)][.] | 2 |
| 9 | großer Buchstabe[.] | [A-ZÜÖÄ][.] | 2 |
| 10 | [)][.] Leerzeichen großer Buchstabe | [)][.] [A-ZÜÖÄ] | 1 |
| ~479 |
Tabelle 1: Ergebnisse der Satzmusteranalyse zur Identifikation von Satzgrenzen für das MRG
4.1.
Implementierung der Modellierungsmethode ^
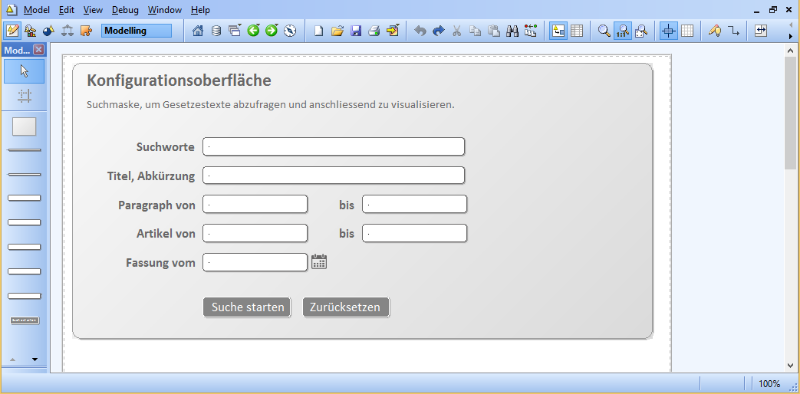
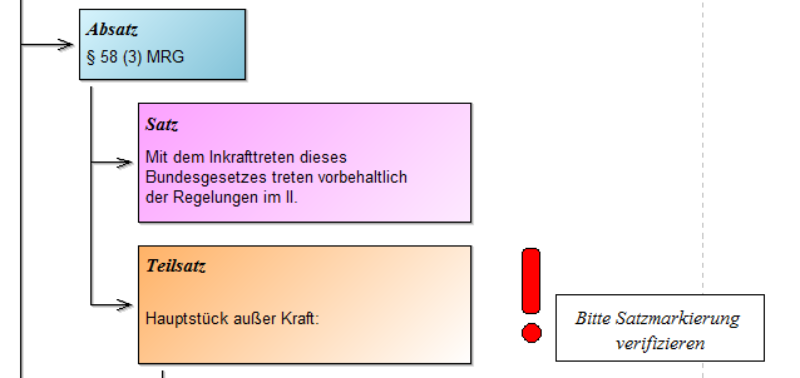
Beim Ausführen einer Suche erhält der Benutzer eine Liste von Gesetzen angezeigt, welche sich dann automatisch mit einem Klick im Editor visualisieren lassen. Auf Basis der vorgestellten regulären Ausdrücke wurde eine automatisierte Satzmustererkennung entwickelt, die sich um die Markierung der Sätze im RIS-XML kümmert. Die automatische Generierung der Modelle erfolgt in ADOxx über den Aufruf einer jar-Datei aus ADOScript. Diese ausführbare Datei bekommt als Argument das RISXML und führt die Transformation mit Hilfe eines eigens in der Programmiersprache Java entwickelten Programms aus.
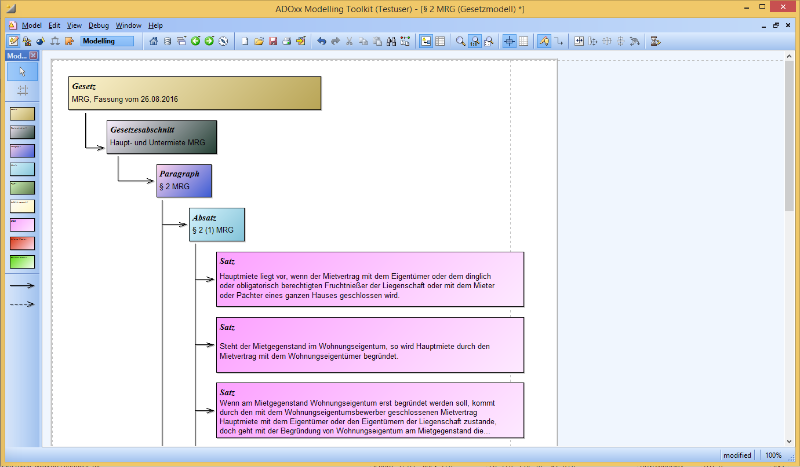
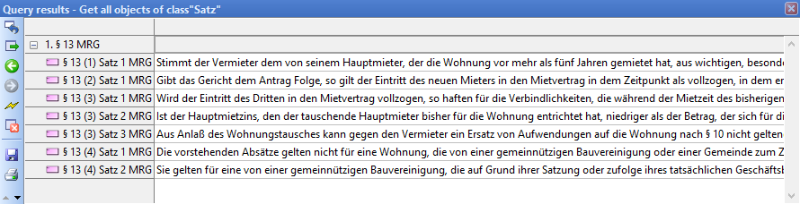
In der Abbildung ist zu sehen, dass jeder Satz im ersten Absatz des § 2 MRG als separates Modellelement dargestellt ist. Von daher sind nun auch Abfragen im Gesetzesmodell nach Sätzen möglich. Eine solche Abfrage nach Sätzen im Gesetzesmodell für § 13 MRG ergab folgendes Ergebnis:
4.2.
Evaluation ^
Für die Evaluation dienen die Ergebnisse der manuellen und automatisierten Analyse. Dabei wurde die manuelle sowie automatische Auszeichnung der Bestandteile des Gesetzes miteinander verglichen. Die folgende Tabelle zeigt eine quantitative Evaluation.
| Anzahl Paragraphen | 79 |
| Anzahl an manuell identifizierten Sätzen | ~ 479 |
| Anzahl an manuell identifizierten Teilsätzen | ~ 261 |
| Anzahl an manuell identifizierten Fragmenten | ~ 18 |
| Anzahl richtig erkannter Paragraphen | 69 |
| Satzmuster | 13 |
| Regeln | 10 |
| Bekannte Sonderfälle | 4 |
Tabelle 2: Quantitative Evaluation des MRG
Die korrekte Abdeckung und Erkennung der automatischen Satzmustererkennung lag dabei bei 87%. Der restliche Teil beinhaltete fehlerhafte Satzmarkierungen wie
- Teilsätze, die mit einem großen Buchstaben beginnen und einem Satzpunkt enden, Publicationsystem: Abschnitt Text und Bild [Rz 39]
- Abkürzungen, die nicht als solche identifiziert werden, beispielsweise «Nr. 1» oder «II. Hauptstück», Publicationsystem: Abschnitt Text und Bild [Rz 40]
- und Datumsangaben, wie 30. November.
5.
Conclusio und Ausblick ^
5.1.
Danksagung ^
6.
Literatur ^
Bork, Domenik/Fill, Hans-Georg, Formal Aspects of Enterprise Modeling Methods: A Comparison Framework. In: Sprague, Ralph H. Jr. (Hrsg.), Proceedings of the 2014 47th Hawaii International Conference on System Science, IEEE/CPS, Los Alamitos/Washington/Tokyo 2014, S. 3400–3409.
Bundeskanzleramt der Republik Österreich (BKA), Handbuch der Rechtssetzungstechnik: Teil 1: Legistische Richtlinien 1990, Wien 1990. https://www.bka.gv.at/DocView.axd?CobId=1656.
Bundeskanzleramt der Republik Österreich (BKA), RIS – Allgemeine Informationen, https://www.ris.bka.gv.at/UI/Info.aspx.
Bundeskanzleramt der Republik Österreich (BKA), RIS – Open Government Data. https://www.ris.bka.gv.at/UI/Ogd.aspx.
Enser, Gerhard/Quirchmayer, Gerald/Traunmüller, Roland, Wilfert, Norbert, Der Einsatz von Expertensystemtechniken zur Unterstützung der Arbeit mit Rechtsinformationssystemen. In: Paul, Manfred (Hrsg.), Proceedings der 19. GI-Jahrestagung, Springer Verlag, Berlin/Heidelberg 1989, Band II, Springer, S. 125–140.
Falleri, Jean-Rémy/Huchard, Marianne/Lafourcade, Mathieu/Nebut, Clémentine, Metamodel Matching for Automatic Model Transformation Generation. In: Czarnecki, Krzysztof/Ober, Ileana/Bruel, Jean-Michel/Uhl, Axel/Völter, Markus (Hrsg.), Model Driven Engineering Languages and Systems – 11th International Conference, MoDELS 2008, Toulouse, France, 28 September–3 October 2008, Proceedings, Springer Verlag, Berlin/Heidelberg 2008, S. 326–340.
Fill, Hans-Georg/Haiden, Katharina, Visuelle Modellierung für rechtsberatende Berufe am Beispiel der gesetzlichen Erbfolge. In: Schweighofer, Erich/Hötzendorfer, Walter/Kummer, Franz/Borges, Georg, Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016, OCG – Oesterreichische Computer Gesellschaft, Wien 2016, S. 349–356.
Fill, Hans-Georg/Karagiannis, Dimitris: On the Conceptualisation of Modelling Methods Using the ADOxx Meta Modelling Platform. In: Enterprise Modelling and Information Systems Architectures – An International Journal 2013, Vol. 8, Issue 1, S. 4–25.
Karagiannis, Dimitris/Kühn, Harald, Metamodeling Platforms. In: Bauknecht, Kurt/Tjoa, A Min/Quirchmayr, Gerald (Hrsg.), Third International Conference, EC-Web 2002 Aix-en-Provence, Springer Verlag, Berlin-Heidelberg 2002, S. 182.
Koller, Daphne/Friedman, Nir, Probabilistic Graphical Models: Principles and Techniques. In: MIT Press 2011, S. 237–238.
Merkl, Dieter/Schweighofer, Erich/Winiwarter, Werner, CONCAT – Connotation Analysis of Thesauri Based on the Interpretation of Context Meaning. In: Karagiannis, Dimitris (Hrsg.), 5th International Conference on Database and Expert Systems Applications, Springer Verlag, London 1994, S. 329–338.
Schweighofer, Erich, Rechtsinformation und Wissensrepräsentation, Automatische Textanalyse im Völker- und Europarecht, Springer Verlag, Wien 1999.
Stöger, Helga/Weichsel, Helmut, Das Redesign des Rechtsinformationssystems – Datenerfassung und Abfrage. In: Schweighofer, Erich/Geist, Anton/Heindl, Gisela (Hrsg.), 10 Jahre IRIS: Bilanz und Ausblick – Tagungsband des 10. Internationalen Rechtsinformatik Symposions IRIS 2007, Boorberg, Stuttgart 2007, S. 231–237.
Weichsel, Helmut, Rechtsinformationssystem (RIS) – ein Rück- und Ausblick. In: Schweighofer, Erich/Handstanger, Meinrad/Hoffmann, Harald/Kummer, Franz/Primosch, Edmund/Schefbeck, Günther/Withalm, Gloria (Hrsg.), Zeichen und Zauber des Rechts – Festschrift für Friedrich Lachmayer, Editions Weblaw, Bern 2014, S. 185–198.
Winiwarter, Werner/Schweighofer, Erich, Legal Expert System KONTERM – Automatic Representation of Document Structure and Contents. In: Marik, Vladimir/Lazansky, Jiri/Wagner, Roland (Hrsg.), 4th International Conference on Database and Expert Systems Applications, Springer Verlag, Berlin-Heidelberg 1993, S. 486–497.





