1.
Introduction ^
[1]
Legal informatics seeks to leverage computer and communication technologies to enhance the practice of law. As such, it encompasses a broad area, including legal research, legal education, business development for law firms, case and practice management, and other related fields.
[2]
Legal informatics has already changed the practice of law in a number of ways. Many legal documents are now electronic, law offices are going completely digital, document search is primarily conducted through a computer, and the Internet has become a marketplace for law firms.
[3]
Taking all this for granted, what new directions are possible, given the ever-increasing power and storage capacity of computer systems, the increased sophistication of statistical models and algorithms, and our understanding of how the workplace is changing? For example, the impact of market factors, such as the recent economic downturn, has led to customers pushing back on ‘billable hours’ and the passing on of research costs. One has to believe that this will lead to a demand for greater efficiency and functionality in computer-based search and collaboration tools.
2.
The Role of Search ^
[4]
Electronic search was once the province of librarians and is now the kingdom of everyone, so that document collections containing millions of disparate items can now be stored, indexed and retrieved in a basic fashion relatively cheaply. Keyword indexing and retrieval has developed over the last three decades into a well-understood science that has also seen some innovation [see e.g., Robertson & Zaragoza, 2009]. However, it’s been argued that this approach has been taken to a point of diminishing returns, and that more semantics is required [see e.g., Schweighofer & Haneder, 2002].
[5]
The effectiveness of keyword-based retrieval is limited by the degree of term overlap between queries and relevant documents, which remains a limiting factor for two primary reasons. The first is synonymy and the fact that relevant documents may use different words than the query. The second is polysemy and the fact that it is impossible to include all the disambiguating context in a short query.
[6]
More recent methods have concentrated upon (i) the creation and use of document meta-data, and (ii) the collection and modeling of user behavior. The former has become primarily associated with the Semantic Web initiative [Berners-Lee, Hendler & Lassila, 2001], although this is but one approach to the problem. The latter is more often associated with Web search engines, which attempt to leverage user click-throughs and link structure.
[7]
Looking at meta-data more closely, we discern two main lines of research. One seeks to normalize the descriptive terms and labels that appear in documents, thereby building an unambiguous and shared vocabulary that mirrors the conceptual structure of some domain [see e.g., Fensel et al., 2001]. The other takes such terms and labels as are available and uses them to generate classification, recommendations and other value-added services automatically [Al-Kofahi, Jackson, etc al., 2007].
[8]
Looking at user data more closely, we also see two lines of research. One can be described as a bottom-up aggregation of data for modeling and prediction of user interests, wants and needs, whether by collaborative filtering or some other technology [Herlocker, Konstan, Borchers & John Riedl, 1999]. The other, more top-down approach, seeks to classify users to personas that tend to be both domain and role specific, thereby allowing for a personalized experience [see e.g., Mulder, 2006].
[9]
This chapter describes one approach to legal search that attempts to pull some of these strands of work together. We call this approach ‘expert search,’ because it leverages the knowledge of human domain experts, in this case that of editors and searchers. Some of this expert knowledge can be represented explicitly, but some important aspects are tacit, and therefore only revealed through an analysis of behavior.
3.
Leveraging Meta-Data and User Data in Expert Search ^
[10]
For many years, the Westlaw legal portal provided various links, classifications, synopses and other annotations to aid in the browsing and reading of cases, statutes and other materials. These meta-data, some of which predate the Semantic Web by half a century or more, feature proprietary taxonomies and summary materials. At the time of writing, there is no universally agreed upon standard for representing, classifying, or otherwise organizing primary or secondary law documents.
[11]
Legal researchers have often utilized these taxonomies and editorial enhancements to inform and guide their legal research. However, until recently, such meta-data were not used to inform the search algorithms in any interesting fashion. In other words, the expertise of our in-house editors improved the navigational experience of Westlaw users, but really did nothing to make documents more findable through the normal query process. One reason for this lack was the fact that law librarians and legal researchers are rather suspicious of anything that involves semantic or statistical inference, especially if they cannot understand its inner workings.
[12]
Boolean queries may be rather literal and pedestrian, but you always know exactly why you got the result you did. Even where the results are unanticipated, or just plain disappointing, it is easy to perform a post-hoc analysis of why things turned out that way. It is much harder to explain why a particular document ranks high in a search result when the ranking takes into account a number of weighted factors in addition to keyword matching, such as citation count, classification, and the like, even though such factors are highly predictive of utility.
[13]
Behind every query, there is an information need that can only be inferred. The paradox of information retrieval is that the further one departs from the literal processing of query terms, in order to improve precision and recall, the more difficult it is to justify or explain the final ranking of results. Furthermore, utility is not a uniform concept in search; it appears to involve, at the very least, both relevance and importance. Relevance involves evidence that is at least partly textual, that is to say, coincidence of subject matter. Importance is largely non-textual, involving such evidence as who wrote the document, who or how many people have read it, what other documents cite it, and so on.
[14]
However, folding non-textual elements into a search ranking runs the risk of making the search result harder to understand. Web searches that are to a large extent popularity based have proved to be intelligible to the majority of users, whose queries are rarely more than two terms long. It’s noticeable that the longer and more complex a Web query is, the less understandable the results tend to be. (Consequently, Google increased the number of lines in its snippets for queries with more than three words in March 2009.) There is also the question of whether a popular page is a relevant or an important page in all domains or circumstances. On the open Web, it is likely that this is true for entertainment-based pages, but it may be less true for other kinds of inquiry.
[15]
One approach to utility is to attempt to leverage the expertise of editors and power users in order to augment judgments of relevance and importance respectively. Meta data generated by editors, possibly with some automatic assistance, can mediate relevance across different vocabularies and query wordings, addressing the synonymy problem mentioned earlier. Editorial value addition can be treated as a knowledge source by the search engine, so long as it can extract useful information from summaries, classifications, links and the like. Not many of these additions were intended to be read by a machine, so some programmatic interpretation is often necessary, using techniques from natural language processing [see e.g., Jackson & Moulinier, 2007]. At the same time, user page views, print actions, link following and history checking behaviors are another, orthogonal knowledge source that can convey importance and relatedness. (For some recent proposals concerning the analysis of post-click activity on the Web, see [Zhong et al., 2010].) We are already familiar with such mechanisms from the consumer space, e.g., recommendations based on data to the effect that people who bought this product also bought that product, people who looked at this product subsequently bought that product, and so on. Query log mining coupled with session-based analysis can identify what documents are ultimately consumed after a series of related queries and which documents are typically consumed together.
[16]
Legal documents are not consumer products, so there are some subtleties in how search results should be assembled and reranked based on these knowledge sources. Straightforward collaborative filtering and other popularity-based metrics are not directly applicable, given the varying ages of documents, the diversity of jurisdictions, and court seniority in the appellate chain. Nevertheless, harnessing the expertise of editors and users has clear benefits. Improving relevance by mediating across vocabularies and wordings typically improves recall, while gauging importance through aggregated user behavior typically improves precision in the top ranks.
[17]
We argue that a combination of editorial and content technology processes creates anexplanatory model for understanding the relationship between topics and documents, i.e., a framework for determining the relevance and importance of any given document with respect to a topic. This is crucial because legal documents, such as cases, often deal with multiple disparate topics, but are not equally authoritative on each such topic. We deal with this complexity in a person-machine system in which editors read new cases and write a summary for each point of law; these ‘headnotes’ are then codified by assigning them topical classifications (in our Key Number system) with some automatic assist. Similarly, a computer-assisted citator then determines for which of these topics a document is cited, i.e., which topics ‘dominate’ in the document.
[18]
The Key Number system is essentially a codification of topics in the legal domain. The granuality of the classification does not always coincide with how attorneys conceptualize legal issues, nor do all attorneys conceptualize the scope of legal issues in a consistent manner. But its structure of over 100,000 nodes does provide a backbone for organizing US case law across jurisdictional lines, and it has become ade facto (albeit proprietary) standard.
[19]
Additionally, as a legal issue become more popular (in other words, more litigated), its representation in the key number system may become more detailed and differentiated. The net effect is that cases are often cited for more than one key number, and a small subset of all key numbers attracts the vast majority of such citations. This finding is supported by a retrospective citation analysis of millions of case law documents on Westlaw.
[20]
To illustrate, consider the caseBurger King vs. Rudzewicz (471 U.S. 462), a 1985 decision from the United States Supreme Court. This is one of the seminal decisions on ‘long-arm’ jurisdiction statutes; it has 27 headnotes that have been classified to 14 unique key numbers. As of September 2010, the case has been cited about 39,000 times, of which about 17,000 citations are assigned a key number. The top 3 key numbers account for 14,917 citations, or about 87%.1 Figure 1 aggregates this behavior for all appellate level cases in the United States as of August 2010.
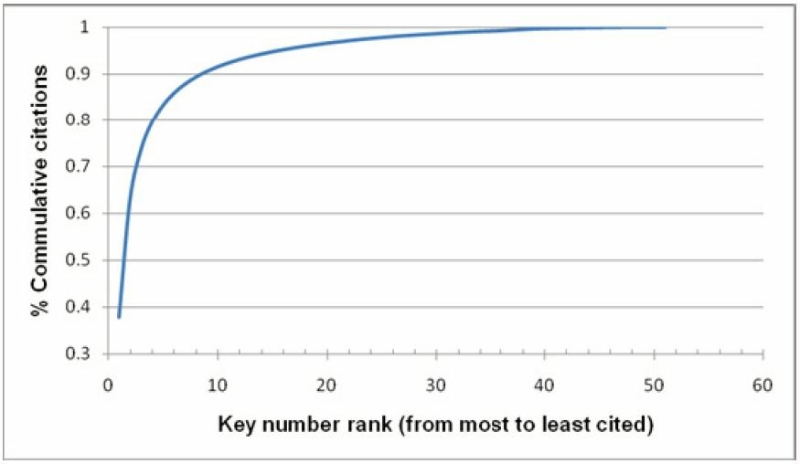
Figure 1. Power law distribution of the dominant topic for appellate cases in the United States
[21]
Experienced legal researchers are intuitively aware of both the multifarious nature of case law and the power law distribution of legal topics among cases. They know that there is a ‘thick neck’ of legal topics that are heavily litigated, as well as a ‘long tail’ of topics that are litigated much less frequently. After years of running Boolean queries and winnowing the results, using navigational tools such as KeyCite and the Key Number System, they can conceive of a search engine that does some of this work for them, by weighing some of the same information.
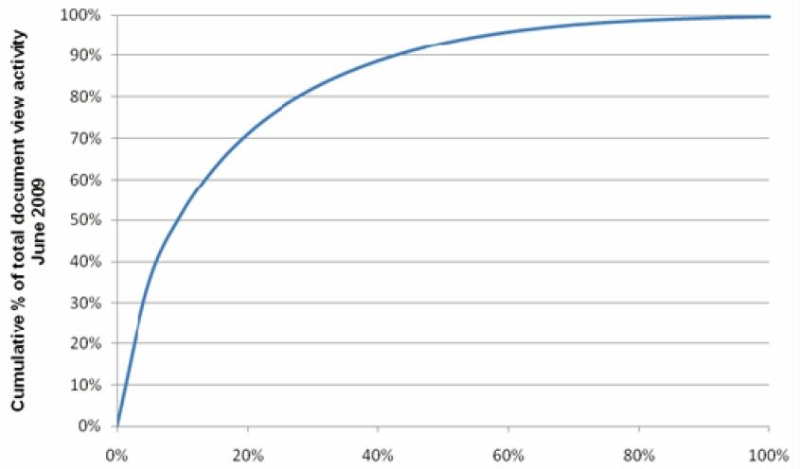
Figure 2. Power users of Westlaw dominate click-through statistics in a typical month
[22]
The notion of an explanatory model for understanding legal documents may also extend into the domain of user behavior. Figure 2 shows that for the month of June 2009, 20% of Westlaw users generated 70% of the clicks. This typical power law distribution provides a rationale for believing that reranking algorithms based on these data will tend to reflect the judgments of the most active searchers.2 As such, result lists should be mostly in accord with the intuitions of legal researchers, even if we are not able to explain exactly how the final rankings were derived. As with popularity based searching of the kind practiced by Google and other sites, users tend not to question search rankings that are consonant with the dominant explanatory model, which for the Web is that sites that have many incoming links or visits beat sites that do not. Similarly, cases that are highly read or highly cited are cases that users expect to see ranked high in the results list of a legal search, assuming that they are also textually relevant to the query. In some ways, our job is easier than that of more general search engines, since our users do not display the demographic diversity with the concomitant disparity in behaviors and expectations that have been observed with Web searching [see e.g., Weber & Castillo, 2010].
4.
Search and Findability ^
[23]
A typical legal search scenario can be described as follows. Given an information need, a researcher must first distill such information need into a (typically) short query, which is then executed against a search engine. The researcher must then inspect the returned results, identify relevant documents, formulate additional queries based on what she learned from relevant documents and repeat the process until she is confident that her research has identified important decisions.
[24]
This plain search scenario presents a number of challenges. First, the information need is often under-defined. For example, the researcher may have a factual situation that lends itself to multiple legal principles and the researcher may not be aware of all of them. Furthermore, these principles may be expressed differently in different document types, such as cases, statutes, and law reviews. Second, distilling what is often a complex information need into a short query is necessarily problematical. A certain amount of ‘mind reading’ on the part of the search engine is required, preferably guided by patterns of aggregated user behavior. Finally, providing the user with a list of documents to inspect and determine their relevancy in a sequential manner is cumbersome, and the user is often left without any practical means to know when they have found everything that is relevant and important.
[25]
WestlawNext was designed to address at least some of these problems. Important system components include document recommendations, navigation, faceted classification, research organization tools, and collaboration tools. We briefly discuss their main features.
[26]
Document recommendation is a useful tool in addressing the findability problem. WestlawNext provides two forms of document recommendations. The first is document-centric. It involves segmenting documents into topics and automatically generating a set of recommendations for each topic. The second is task-centric. WestlawNext allows users to organize their research into a folder or directory structure. The system analyzes the content of a folder, which typically represents a user task, and then recommends additional documents. The relevancy threshold is set rather high to avoid a spamming effect.
[27]
WestlawNext provides users with significant navigation and faceted classification capabilities. Users can navigate to a topic and refine their information need in terms of the taxonomy. They can also use facets to filter search results and home in on relevant documents.
[28]
A document summarization system was used to generate document snippets for WestlawNext [Schilder & Molina-Salgado, 2006]. User studies have shown that query-based summaries have a significant impact on the ability of researchers to discern the relevancy of documents without the need to read the actual document [White, Ruthven et al., 2002].
[29]
In terms of productivity tools, the system allows users organize their sessions and results into topical or task-oriented directories as well as annotate the results at the document and directory level. Other tools include collaboration features, which allow multiple researchers to share the found documents associated with a legal matter.
[30]
Lastly, the search engine produces a portfolio of results, which includes cases, statutes, regulations, analytical material, and administrative decisions. This is not simply a global or federated search of multiple databases containing different document types. Rather, each content type has its own search engine, employing a total of thirteen different algorithms. We found this diversity to be necessary for optimal results because the underlying documents, as well as their meta-data and usage patterns, differ significantly from collection to collection.
[31]
In designing the search engines, our challenge was how to build a representation and retrieval framework that is able to utilize the various data and meta-data components. To this end, we adopted a supervised machine learning approach. We designed a large number of feature functions to represent and capture the various data and meta-data attributes in a consistent manner.
[32]
Domain experts manually generated training/testing data in the form of 405 research reports that collectively contained more than 100,000 document relevance judgments. Each report consisted of an issue statement, one or more queries, and a portfolio of results (cases, statutes, regulations, analytical articles, etc). The results were graded using a 5-point scale (A through F, where A is highly relevant and F is irrelevant).
[33]
The 100,000 documents were used to train and test a ranker support vector machine [Joachims, 2002] using a 10-fold cross validation set up. The learner was configured to minimize the cost of pair-wise inversions3 , where the cost of an inversion is determined by the document labels. Thus ranking a ‘B’ document before an ‘A’ document is less costly than inverting an ‘A’ and an ‘F’ document.
[34]
System performance was measured per content type using such metrics as precision, recall, and NDCG, i.e., Normalized Discounted Cumulative Gain [Järvelin & Kekäläinen, 2002]. Several user studies were also conducted to provide additional metrics and practical insights, some of them by independent agencies. These studies included asking users to compare two sets of results, rate their overall satisfaction with the results, and estimate productivity gains (in terms of time to complete research task). We found that NDCG at top 5 and top 10 correlated well with user studies, thereby giving us confidence in both our approach and our evaluation methodology.
5.
Summary ^
[35]
The role of artificial intelligence in our approach to legal search is two-fold.
[36]
Firstly, natural language processing algorithms have to interpret document meta-data supplied by editors. Some of these meta-data, such as headnote text and other summary material, have not been produced for machine consumption but are provided as a guide to human readers. Other meta-data, such as taxonomic classifications or annotation with reserved vocabulary terms, are more machine-readable. Since legal cases are rarely about just one topic, it is usually necessary to infer which aspect of a document is responsive to a query as part of inferring the underlying information need. Meta-data can be extremely useful in this regard, e.g., by analyzing the pattern of annotations found among the high-scoring documents brought back by an initial search, in a manner analogous to blind relevance feedback [Al-Kofahi, Tyrrell et al., 2001].
[37]
Secondly, the data mining of user behavior has to feed machine learning algorithms that optimize search outcomes based on aggregate click-throughs and other user actions. These statistics are eminently machine-readable, but need to be coordinated with other clues to user intent, such as query logs and session data. The knowledge that drives human judgments of relevance is difficult to represent explicitly, but its effects can be modeled mathematically, so long as data is available in sufficient quantity. This aspect of expertise is really quite different from that of editors, and it is also expressed differently. Unlike the codification performed by editors, user decisions draw upon tacit knowledge [Virtanen, 2009] which is hard to codify or capture explicitly. Searchers may have difficulty defining relevance in the abstract, but they know a relevant document when they see one in a result list. These relative judgments can be used to improve search results, e.g., using ranking support vector machines as outlined above.
[38]
In this chapter, we have tried to strike the right balance between human and artificial intelligence in the context of legal search. Various commercial claims to the contrary, it is not yet possible to solve the findability problem by automation alone. This is not merely a matter of natural language processing; there is also a need for domain knowledge, not all of which may be represented explicitly.
[39]
As we have written elsewhere [Jackson, Al-Kofahi, et al., 2003], even understanding the outcomes of simple cases requires inference that is not easy to accommodate in a general reasoning program. Understanding the direct history of a case, and determining whether or not a case is still ‘good law’ for a given issue, is a difficult task that requires human intervention. Even more difficult is the evaluation of ‘indirect history’, i.e., the comments that a judge makes about cases not in the appellate chain of the instant case and which may affect their precedential value in a particular jurisdiction.
[40]
One could attempt to build formal semantic models for each of these major tasks pertaining to each major area of the law, but this would appear to be a formidable, and possibly endless, undertaking. We feel that our investments in editorial value addition and user data mining are probably the best means of factoring the human element into legal search, while still harnessing the tirelessness and attention to detail that characterize the operation of machines. Having programs that explore the whole web of document meta-data and apply judicious ranking based on aggregated customer behavior allows us to manage the recall-precision trade-off more effectively than algorithmic methods alone.
[41]
Advances in data mining algorithms and infrastructure have made the large-scale analysis of meta-data, query logs and user data possible, while the falling cost of CPU and storage makes it feasible economically. We employed distributed processing frameworks such as Hadoop [White, 2009] to exploit the data parallelism inherent in both ‘extract-transform-load’ and user modeling tasks to break up large computations into jobs that can be run in very manageable timeframes that would have required a supercomputer only a decade ago. Meanwhile, the increased reliance of legal professionals and other knowledge workers upon online resources has provided both plentiful supplies of user data and an acceptance that such data will be harnessed to improve everyone’s search experience.
6.
References ^
Al-Kofahi, Khalid, Jackson, Peter ,Elberti, Charles, Keenan, William, A document recommendation system blending retrieval and categorization technologies. In Proceedings of the AAAI Workshop on Recommender Systems in e-Commerce, pp. 9-16 (2007).
Al-Kofahi, Khalid, Tyrrell, Alex, Vachher, Arun, Travers, Tim, Jackson, Peter, Combining Multiple Classifiers for Text Categorization, In Proceedings of the Tenth International Conference on Information and Knowledge Management, pp. 97-104 (2001).
Fensel, Dieter, van Harmelen, Frank, Horrocks, Ian, McGuiness, Deborah, Patel-Schneider, Peter, OIL: An Ontology Infrastructure for the Semantic Web. IEEE: Intelligent Systems, Vol. 16, No. 2, pp. 38-45 (2001).
Herlocker, Jonathan, Konstan, Joseph, Borchers, Al, Riedl, John, An algorithmic framework for performing collaborative filtering. In Proceedings of the 1999 Conference on Research and Development in Information Retrieval, pp. 230-237 (1999).
Jackson, Peter, Al-Kofahi, Khalid, Tyrell, Alex, Vachher, Arun, Information Extraction from Case Law and Retrieval of Prior Cases. Artificial Intelligence, vol. 150, pp. 239-290 (2003).
Jackson, Peter, Moulinier, Isabelle, Natural Language Processing for Online Applications, Second Edition, John Benjamins (2007).
Järvelin, Kalervo, Kekäläinen, Jaana, Cumulated gain-based evaluation of IR techniques, ACM Transactions on Information Systems (TOIS), vol. 20, no. 4, pp. 422-446 (2002).
Joachims, Thorsten, Optimizing Search Engines Using Clickthrough Data, Proceedings of the ACM Conference on Knowledge Discovery and Data Mining (KDD), pp. 133-142 (2002).
Mulder, Steve, Yaar, Ziv, The User Is Always Right: A Practical Guide to Creating and Using Personas for the Web, Ch. 3, New Riders Press (2006).
Robertson, Stephen, Zarazoga, Hugo, The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval, Vol. 3, No. 4, pp. 333-389 (2009).
Schilder, Frank, Molina-Salgado, Hugo, Evaluating a summarizer for legal text with a large text collection. In the Proceedings of the 3rd Midwestern Computational Linguistics Colloquium (MCLC) 2006, Urbana-Champaign, IL, USA (2006).
Schweighofer, Erich, Haneder, Gottfried, Improvement of Vector Representation of Legal Documents with Legal Ontologies. In Proceedings of The 5th BIS, Poznan University of Economics Press: Poznan, PL (2002).
Virtanen, Ilkka, The Problem of Tacit Knowledge – Is it Possible to Externalize Tacit Knowledge? In Frontiers in Artificial Intelligence and Applications, vol. 190, pp. 321-330 (2009).
Weber, Ingmar, Castillo, Carlos, The Demographics of Web Search, In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 523-530 (2010).
White, Ryen, Ruthven, Ian, Jose, Joemon, Finding relevant documents using top ranking sentences: an evaluation of two alternative schemes. In Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, pp. 57-64 (2002).
White, Tom, Hadoop: The Definitive Guide. O’Reilly Media.
Zhong, Feimin, Wang, Dong, Wang, Gang, Chen, Weizhu, Zhang, Yuchen, Chen, Zheng, Wang, Haixun, Incorporating Post-Click Behaviors Into a Click Model, In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 355-362 (2010).
Peter Jackson, Chief Scientist, Thomson Reuters, Corporate Research & Devel-opment
Khalid Al-Kofahi, Vice President of Research, Thomson Reuters, Corporate Research & Development, 610 Opperman Drive, Saint Paul, MN 55123, USA
Peter.Jackson@ThomsonReuters.Com ;http://www.jacksonpeter.com
Al-Kofahi, Khalid, Tyrrell, Alex, Vachher, Arun, Travers, Tim, Jackson, Peter, Combining Multiple Classifiers for Text Categorization, In Proceedings of the Tenth International Conference on Information and Knowledge Management, pp. 97-104 (2001).
Fensel, Dieter, van Harmelen, Frank, Horrocks, Ian, McGuiness, Deborah, Patel-Schneider, Peter, OIL: An Ontology Infrastructure for the Semantic Web. IEEE: Intelligent Systems, Vol. 16, No. 2, pp. 38-45 (2001).
Herlocker, Jonathan, Konstan, Joseph, Borchers, Al, Riedl, John, An algorithmic framework for performing collaborative filtering. In Proceedings of the 1999 Conference on Research and Development in Information Retrieval, pp. 230-237 (1999).
Jackson, Peter, Al-Kofahi, Khalid, Tyrell, Alex, Vachher, Arun, Information Extraction from Case Law and Retrieval of Prior Cases. Artificial Intelligence, vol. 150, pp. 239-290 (2003).
Jackson, Peter, Moulinier, Isabelle, Natural Language Processing for Online Applications, Second Edition, John Benjamins (2007).
Järvelin, Kalervo, Kekäläinen, Jaana, Cumulated gain-based evaluation of IR techniques, ACM Transactions on Information Systems (TOIS), vol. 20, no. 4, pp. 422-446 (2002).
Joachims, Thorsten, Optimizing Search Engines Using Clickthrough Data, Proceedings of the ACM Conference on Knowledge Discovery and Data Mining (KDD), pp. 133-142 (2002).
Mulder, Steve, Yaar, Ziv, The User Is Always Right: A Practical Guide to Creating and Using Personas for the Web, Ch. 3, New Riders Press (2006).
Robertson, Stephen, Zarazoga, Hugo, The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval, Vol. 3, No. 4, pp. 333-389 (2009).
Schilder, Frank, Molina-Salgado, Hugo, Evaluating a summarizer for legal text with a large text collection. In the Proceedings of the 3rd Midwestern Computational Linguistics Colloquium (MCLC) 2006, Urbana-Champaign, IL, USA (2006).
Schweighofer, Erich, Haneder, Gottfried, Improvement of Vector Representation of Legal Documents with Legal Ontologies. In Proceedings of The 5th BIS, Poznan University of Economics Press: Poznan, PL (2002).
Virtanen, Ilkka, The Problem of Tacit Knowledge – Is it Possible to Externalize Tacit Knowledge? In Frontiers in Artificial Intelligence and Applications, vol. 190, pp. 321-330 (2009).
Weber, Ingmar, Castillo, Carlos, The Demographics of Web Search, In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 523-530 (2010).
White, Ryen, Ruthven, Ian, Jose, Joemon, Finding relevant documents using top ranking sentences: an evaluation of two alternative schemes. In Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, pp. 57-64 (2002).
White, Tom, Hadoop: The Definitive Guide. O’Reilly Media.
Zhong, Feimin, Wang, Dong, Wang, Gang, Chen, Weizhu, Zhang, Yuchen, Chen, Zheng, Wang, Haixun, Incorporating Post-Click Behaviors Into a Click Model, In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 355-362 (2010).
Peter Jackson, Chief Scientist, Thomson Reuters, Corporate Research & Devel-opment
Khalid Al-Kofahi, Vice President of Research, Thomson Reuters, Corporate Research & Development, 610 Opperman Drive, Saint Paul, MN 55123, USA
Peter.Jackson@ThomsonReuters.Com ;http://www.jacksonpeter.com
- 1 For example, the top Key Number in this case is «170B K 76.5» which has the title «Federal Courts / Venue / In General / Actions Against Non-Resident; ‹Long-Arm› Jurisdiction in General / Contacts with forum state.» This Key Number accounts for 8,648 of the 17,000 citations.
- 2 We excluded law students from the click model because they are still learning their trade and their class assignments might skew the statistics.
- 3 An inversion is a deviation from the ideal ranking, which consists of all ‘A’ documents first, followed by ‘B’ documents, and so on.





