1.
Motivation ^
The typical result when creating a legal visualization is either an image or a set of images that represents one or more aspects of a legal episode. The process of creating the visualization is thereby not always made explicit but often depends on implicit assumptions and considerations of the creator. This may not only hinder other people from interpreting the visualization correctly, it also presents a considerable barrier for the semantic processing of the visualization by machines. However, as the knowledge about these assumptions and considerations is available at the time of creation it seems worthwhile to make use of it by passing it on to machines. Immediate benefits that could be gained through machine based semantic processing are functionalities such as the search for similar legal episodes, the automatic suggestion of graphical enhancements of the visualization or the automated check of the compliance of the depicted episode with legal regulations. In the following it will be discussed how the knowledge contained in a legal visualization can be made explicit using different syntaxes. It will then be investigated which semantic interpretations can thus be made by machines working on these syntaxes. The remainder of the paper is structured as follows: In section 2 we briefly outline some fundamental considerations for the presented approach. Section 3 describes the characteristics and realization of the polysyntactic view that allows us to explore the range of semantic interpretations in this context in section 4. The paper is concluded in section 5.
2.
Foundations ^
The creation of legal visualizations can be performed using a number of different methods and tools. These include artistic painting techniques as apparent by the visualizations contained in the Sachsenspiegel as well as metaphoric-based construction techniques, e.g. as for example used by [Lachmayer, 2008]. In most cases today legal visualizations are created using software, such as painting programs, presentation software or modeling tools [e.g. Heindl and Kahlig, 2008; Lachmayer, 2008]. The shift towards using information technology for creating legal visualizations not only leads to benefits such as the simplified exchange of images between different parties or the reproduction of an unlimited number of copies of the visualization. It also entails the consideration to which degree machines can actively support the actual creation of the visualization by aiding the user during the creation process as well as analyzing the visualization after it has been created. Thereby, the support can be accomplished on two levels: Either relating to the form of the visualization, i.e. its externally visible properties, or to the content of the visualization, i.e. its associated meaning. An example for a support on the form level could be a design suggestion to improve the perception of the visualization, e.g. by proposing a particular coloring scheme for a visual object that fits well with the remaining objects in terms of visibility. An example that focuses on the content of the visualization could be to give a suggestion for the next step in the creation process by understanding what the user wants to express, relating it to other existing visualizations and thus deriving a possible extension. However, as can already be seen from these simple examples, the differentiation between the form and the content of a visualization is not as clear cut as one might expect. A design suggestion for a particular color thus not only needs to take into account the pure graphical context of the particular object but may also need to take into account possible consequences of the suggestion in regard to the content that might be altered in a way not intended by the user. It might for example have been the intention of the user to highlight a specific feature in the visualization although or exactly because this violates a design rule from the viewpoint of visual perception. When investigating this further it immediately becomes apparent that a multitude of factors may actually influence a creator’s decision for or against a certain visual design. A human user may either implicitly or explicitly refer to his or her own experience and knowledge during the creation process, which are not a-priori known to a machine. In order to enable the machine to conduct correct or at least useful processing this knowledge needs to be made available in a machine understandable format.
This directly leads to the question to which extent machines can interpret legal visualizations at all and which prerequisites have to be met to enable them to do so. The interpretation of human knowledge by machines has been studied in computer science and artificial intelligence for a long time. One of the first works in this area that had a great impact on subsequent approaches was the work by Tarski in the 1930-ies. He developed a mathematical theory for semantic definitions that allows making human intentions more precise and assigning them a correct form [cf. Tarski, 1936, pp. 268]. In order to achieve this he restricted his theory to formalized languages, i.e. artificially constructed languages where the meaning of each term is unambiguously defined by its form. Based on axioms and inference rules it is then possible to transform statements in such a formalized language to other statements that are classified as provable statements. Tarski successfully applied his theory and greatly influenced computer science by it. But he also remarked that if one wants to treat the semantics of colloquial language by using exact methods he would have to precisely specify its structure, eliminate the ambiguities of its terms and split it into a sequence of languages with an ever increasing quantity where each language is related to its previous one in the same way as every formal language is related to its meta language [Tarski, 1936, p.393].
When translating these findings to visual languages that describe the composition of visualizations, we can – to a certain extent – apply similar principles. Although some basic elements in visual languages may carry a meaning that cannot be eliminated in the same way as it can be done with mathematical symbols1 , it seems possible to reduce them to simple graphical primitives with very little semantic information. By assigning precisely specified meanings to these primitives we can then act in the same way as it has been described for formalized languages and define axioms and inference rules that work on these semantic definitions. This approach seems to work just as fine for legal visualizations as it does for formalized languages. But, there are two serious limitations: The first concerns the availability of graphical symbols that allow for an unambiguous definition of their meaning. Although we can imagine creating a very large symbol set where each symbol is uniquely defined, the effort required to create and to work with this single language may in certain cases correspond to designing and learning a sign language as complex as Chinese. Even though recent developments such as crowd sourcing and ant intelligence approaches2 may be able to realize the design of such a language, the effort required for its use would contrast the original intention of using legal visualizations to actually ease the understanding of legal episodes. The second limitation is related to the concern that Tarski mentioned for colloquial language: If someone wants to treat the semantics of a single visualization as exactly as in the case of formal languages, one would have to define a similar sequence of formal languages as Tarski described for colloquial language. To balance the effort for semantically describing legal visualizations and the benefits received by it, it thus seems that we need to find a second best solution3 .
Two solutions seem to be possible: The first is to deviate from the requirement of defining visual objects unambiguously using graphical primitives. By adding natural language descriptions for example – as it is often done for legal visualizations – one can easily make any visual object clearly separable from each other, thus reducing the amount of unique symbols. However, this happens at the cost of having to deal again with colloquial language. The second solution concerns the limitation of the number of formal semantic descriptions that are defined for the visualization. If we decide not to reduce every element in a visualization to an unambiguous element but just the ones that may bring about the largest benefit in terms of machine support, we could greatly reduce the effort of formalization. Again, a side effect of this solution is that it does not allow reaching the condition of an unambiguous definition of each element by its form.
Furthermore, it seems important to develop a solution that is not only capable of generating a benefit based on the formalization, but also one where the formalization can be accomplished by users who have little or no training in formal mathematical methods. Even though this is not a strict requirement it may be necessary to take this into account at an early stage of the development process.
3.
Characteristics and Realization of a Polysyntactic View ^
Based on the above observations we will in the following present some considerations on how to formally specify parts of the semantics in legal visualizations. The aim of the approach is to provide benefit to the creator and potential users of the visualization by allowing for the processing of the explicated semantic information by machines. Due to the limitations shown in the previous section it is not aimed for a complete formalization of the semantics, although the method should theoretically permit it.
The basic notion of the approach is that there are several factors that influence the outcome of the process of creating legal visualizations and that need to be formally described in order to achieve an exact semantic definition that is machine processable. This includes for example aspects such as the underlying legal episode and its context, the choice of graphical primitives, the colors, the relation of graphical primitives, the relations between the graphical primitives and parts of the legal episode, the intended audience of the visualization or even the personal style of the creator. Factors can be characterized on the one hand by their inner structure and rules and on the other hand by their relations to each other. The inner structure of the factor «choice of graphical primitives» may for example define which graphical primitives are available, how they are composed themselves and which rules need to be obeyed when combining them with other graphical primitives. Similar considerations can be made for a factor such as «underlying legal episode» where the primitive elements of the legal episode need to be defined and how these elements may be combined in order to describe the concrete legal episode used for the visualization. This characterization of the factors by their inner structure and rules on this structure are denoted asfactor syntax (f-syntax) . These factor syntaxes then have to be related to each other as there exist multiple dependencies between them. The composition of these different factor syntaxes is denoted as thepolysyntactic stage (see figure 1). It represents a formal definition of the semantics contained in the resulting legal visualization. To exactly define all semantics contained in a legal visualization, the factor syntaxes and the mappings between them would have to be extended in such a way that every aspect in the visualization that carries a meaning is represented either by a single element of one of the factor syntaxes or a mapping between different factor syntaxes.
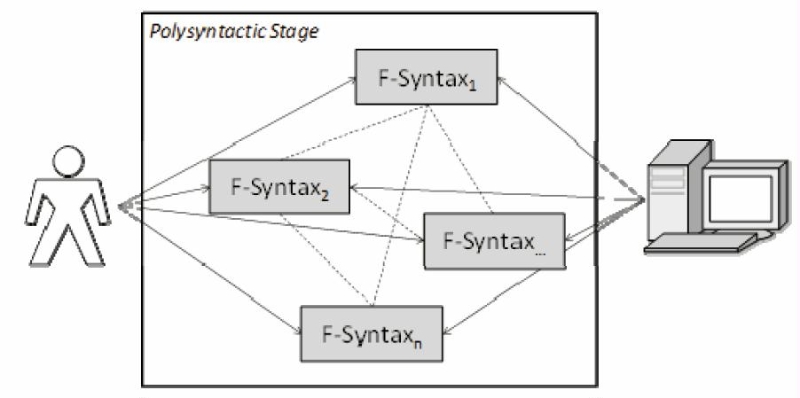
Figure 1: Illustration of the Polysyntactic Stage and its Factor Syntaxes
To enable the processing by machines, the factor syntaxes themselves as well as the mappings between them have to be unambiguously described in one or more formal meta languages. Although the meta languages for the different syntaxes may be different it greatly eases the practical handling if one common meta language can be found. Furthermore, the re-use and exchange of the factor syntaxes between different parties is also better supported by a common meta language.
For illustrating these concepts consider the following example (see figure 2 for an outline of the idea): A legal visualization that explains relationships between different types of courts is taken as a basis. To express that the ellipse shown in the right upper corner of the visualization stands for the concept «court», the graphical primitive «ellipse» in one factor syntax is related to the primitive «court» in a factor syntax for the legal episode. In the same way there may be relations between the «ellipse» and the element «red» included in a color scheme factor syntax and a relation between «red» and the element «general public» from an intended audience factor syntax. The coloring may have been used in this example to differentiate elements in the visualization that are accessible by the general public and elements that are only accessible by legal experts. The semantics attached to the graphical element «ellipse» can thus be partly made explicit. There may still be additional semantic aspects that have not been expressed so far, e.g. about the remaining graphical elements in the visualization. However, a first benefit can already be gained by this partial explication: A machine can now use this information to identify for example the graphical primitive as «ellipse» due to its membership in the graphical primitive factor syntax and resolve its role in the legal episode as «court» due to the mapping to the legal episode factor syntax.
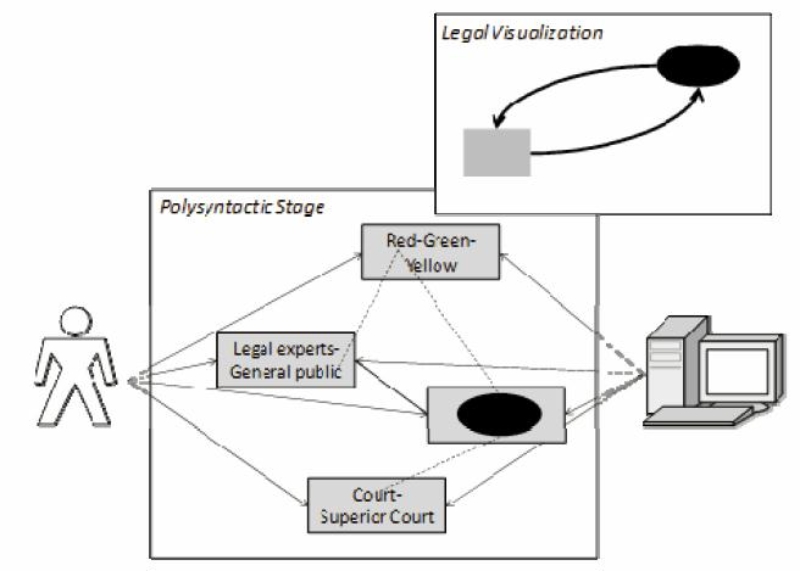
Figure 2: Example for Using the Polysyntactic Stage
Additional processing benefits can be gained by exchanging all or some of the factor syntaxes with other parties. These shall be denoted asdistributed factor syntaxes . By referring to a factor syntax that has been used in another polysyntactic stage it becomes possible to use these references to identify for example common features and similarities in different legal visualizations (see figure 3).
The alert reader will at this point recognize a close relationship to the approach of semantic web [Berners-Lee et al., 2001] where similar concepts for exchanging semantic information have been discussed. It seems however necessary to remark that there is an important difference to the approach presented here. Whereas semantic web approaches strive towards powerful logics that can be used to describe complex properties of objects in order to make machines comprehend semantic documents and data, the approach presented here relies to a large part on human interaction. Even though machines can partially support the discovery of unknown relationships and make suggestions for the design of the visualization, it is being still relied on the human user to make the decision for or against a solution discovered or proposed by the machine. Otherwise we would come back to the problem of complexity for formalizing colloquial language, which would not only require us to handle an immense number of factor syntaxes and the relations between them but would also make it necessary to use a much stricter formal mathematical approach than can be expected to be suitable for an average user.
However, when it comes to realizing the described approach using concrete technology we can reuse several of the concepts that underlie semantic web. In addition, for semantic web there has recently been a relaxation in terms of complexity by promoting the idea of a «web of linked data». In particular, four principles have been named in regard to technology that shall be used for linking data on the web [Berners-Lee, 2009], which can be directly used for our approach here:
2. The use of HTTP URIs so that people can look up those names
3. The provision of useful information using the RDF* and SPARQL standards
4. The inclusion of links to other URIs so that one can discover more things
In addition, the choice of a meta language to describe the factor syntaxes can also be made as proposed for semantic web. Therefore, XML and Unicode as the most basic constituents are chosen. XML is today the most common meta language for syntax descriptions for which parsers exist in almost every computer programming language. Additionally, several standards have been proposed to map different XML documents, e.g. the XLink / XPointer standards4 . Depending on the requirements for a particular scenario, the XML syntax may also be mapped to other syntactic descriptions such as logical calculi that are able to provide procedures of logical inference for the contained information – as for example discussed in the area of XML based ontology languages such as RDF or OWL. Last but not least XML also seems well suited to be applied in the area of legal visualization: Several proposals have been made in the area of legal informatics made in the last years to encode legal information in XML [cf. Biagioli et al., 2007].
With the approach of semantic visualization [Fill, 2006] a formal language for the syntactic description of visual objects including their static and dynamic properties has been developed that can be directly integrated in the approach presented here. Similar attempts can be found in industry where major vendors such as Microsoft make use of XML to describe their graphical representations, e.g. as apparent by the PPTX or the XAML formats used in current versions of MS Office and Windows.
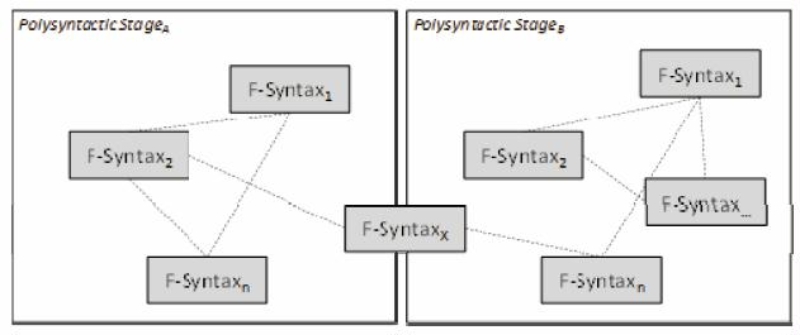
Figure 3: Distributed Factor Syntaxes
Another option for the realization of distributed factor syntaxes are technologies such as No-SQL databases that have also recently been discussed in scientific literature [Ghosh, 2010]. They rely on the JSON syntax format and aim for the creation of a data storage that is closer to the application scenarios than traditional relational database management systems.
4.
Range of Semantic Interpretations ^
Based on the described approach of differentiating and mapping between a number of factor syntaxes, it can now be investigated which semantic interpretations can be inferred. One basic assumption of the approach is that semantics are expressed to a large degree by the mapping between the different syntaxes. One could even imagine that this is a way how human interpretation may work: By relating concepts that are perceived through a stimulus of our senses to existing syntactic structures, i.e. experiences – of whatever complexity – it is possible to interpret a given situation based on our previous mappings between experiences. The essential questions thereby are not only how the information is actually stored but also how the mappings are characterized and what are the fundamental algorithms working on the syntaxes and mappings. In reference to the research in the area of artificial neural networks, one important property of such mappings seems to be their adaptability to new situations and stimuli as well as the specification of their strength. What seems not so clear is whether mappings need to carry a particular meaning or if this meaning is not enforced through the insertion of an additional syntactic element and its mappings in between. By using the latter view it would not be required to assign any meaning to the mappings, thereby simplifying their structure. Another aspect, which is regarded to be of primary importance, is the assignment of temporal information to both the syntactic structures and the mappings. Through the addition of timestamps for the creation, modification, and deletion of elements and rules of the syntaxes and the mappings, it becomes possible to exactly trace the evolution of the semantic definitions over time and reconstruct previous semantic definitions. It would further permit to determine the timeliness of the semantic information.
In the most basic case of the mappings and under the assumption of using a common meta language, a generic algorithm that interacts with a user can discover the relations between the different syntaxes and identify semantic composition patterns, i.e. sets of elements of the factor syntaxes and the mappings between them. These patterns can then be compared to each other, purely on a syntactic basis. Depending on the chosen size of the patterns, it would be possible to receive results in varying semantic depth. Consider again the example from above where the «ellipse» is mapped to «court» and «general public». The algorithm could either regard just the mappings between «ellipse» and «court» or thus try to find these elements and mappings in other polysyntactic stages. By extending the pattern to the «general public» element and its mapping it could perform an even more focused search. Note, that the comparisons made so far only contain syntactic matching. The decision which pattern to choose in a specific context still depends on the human interacting with the algorithm.
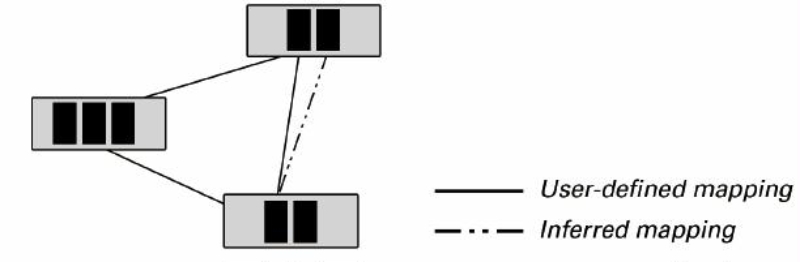
Figure 4: Addition of Mapping Information through Inferencing
It can however also be useful to harness the possibilities of formal, logic based ontology syntaxes to add further machine processing capabilities. Consider the following example: a rectangle in a visual object syntax is mapped to an ontology syntax element «Activity». Furthermore, there exists an inference algorithm for the ontology syntax that is able to infer that mappings to the «Activity» class are also valid if they are made to the class «Action», possibly because of a synonymy axiom that can be understood by the algorithm. So it can automatically update the mapping definitions and add the mapping between rectangle and «Action». Thus, existing inference algorithms have to be extended in a way that they not only work in their «syntax world» but are able to inform the rest of the involved syntaxes about their findings. At the same time the creators and users of the legal visualization are not required to deal with formal mathematical logic but can just make use of their power by mapping their syntaxes to the more formal syntaxes.
5.
Conclusion and Outlook ^
In this paper an approach has been presented to make the semantics contained in legal visualizations explicit. For this purposes a polysyntactic view was taken that assumes that the semantics can be exactly described by setting up a number of factor syntaxes and mappings between them. It has been discussed which semantic interpretations can be made based on these structures. The underlying assumption of the approach has been that the «syntactization» of human semantics is a necessary prerequisite to enable machines to process the visualizations and offer support to the creators and users of the legal visualization.
Several aspects in this work remain to be investigated in more detail. To provide a solid basis for the approach one of the next steps will be to provide a mathematical description that is formal enough to be implemented using information technology. This will allow analyzing the approach in greater depth and testing it using concrete legal visualizations. Furthermore, the temporal properties and the mechanisms for updating and adding mapping information through inference as mentioned in section 4 need to be analyzed in more detail and incorporated into the overall approach.
6.
References ^
Berners-Lee, Tim, Linked Data.www.w3.org/DesignIssues/LinkedData.html last accessed 14. July 2010. (2009).
Berners-Lee, Tim, Hendler, James, Lassila, Ora, The Semantic Web. Scientific American, May 2001. (2001).
Biagioli, Carlo, Francesconi, Enrico, Sartor, Giovanni, Proceedings of the V Legislative XML Workshop. European Press Academic Publishing. (2007).
Fill, Hans-Georg, Visualization for Semantic Information Systems. Gabler (2006).
Ghosh, Debasish, Multi-paradigm Data Storage for Enterprise Applications. IEEE Software, pre-print. (2010).
Heindl, Peter, Kahlig Wolfgang, Mietrecht strukturiert (für Österreich). Manz Verlag (2008).
Lachmayer, Friedrich, Staat – Bundesverwaltung – Gesellschaft.www.legalvisualization.com/ last accessed 14. July 2010. (2008).
Tarski, Alfred, Der Wahrheitsbegriff in den formalisierten Sprachen (in German). In: Studia Philosophica I, 261-405.www.ifispan.waw.pl/studialogica/s-p-f/volumina_i-iv/I-07-Tarski-small.pdf last accessed 14 . July 2010 (1936).
Hans-Georg Fill, University of Vienna, DKE / Stanford University, BMIR, 1210 Vienna, Bruenner Strasse 72,hans-georg.fill@univie.ac.at
- 1 And even these may not be completely meaning-free, just consider AΩ.
- 2 Crowd sourcing and ant intelligence approaches refer to the use of aggregate human intelligence through internet based technologies. They can potentially involve every user of the internet who is willing to participate and can thus provide an enormous pool of human resources for solving complex problems – see also [Auer and Ives, 2006].
- 3 The theory of the second best is a concept from economics where it has been used to describe a situation where one optimality condition cannot be satisfied and it is possible that the next best solution requires deviating from other already satisfied optimality conditions.
- 4 Seewww.w3.org/TR/xlink/ last accessed 14. July 2010 andwww.w3.org/TR/xptr-xpointer/ last accessed 14. July 2010





