1.
Introduction ^
2.
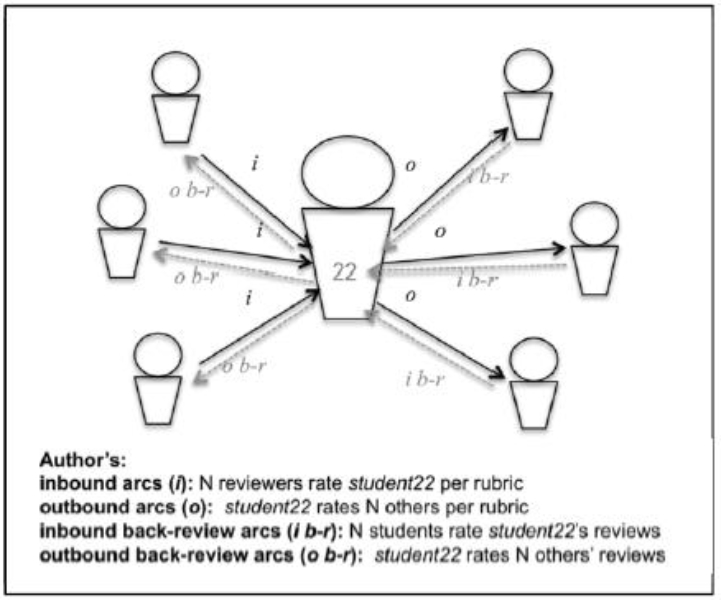
Peer review as social network discussion ^
3.
Problem-specific legal-concept review criteria ^

- Smith v. Barry for breach of the nondisclosure/noncompetition agreement (nda),
- Smith v. Barry and VG for trade-secret misappropriation (tsm),
- Jack v. Smith for misappropriating the I-phone-based instrument-controller interface idea (idea1),
- Barry v. Smith for misappropriating Barry’s idea for the design of a Jimi-Hydrox-related look with flames for winning (idea2),
- Estate of Jimi Hydrox v. Smith for violating right-of-publicity (rop),
as well as unfair competition, and passing off (federal Lanham Act s. 1125(a)).
Students needed to address some general issues across IP claims (e.g., the extent and nature of the alleged infringer’s use of the ideas or information required for misappropriation or infringement, the degree of similarity required between the claimant’s and alleged infringer’s ideas and information.) Since the instructor included factual weaknesses as well as strengths for each claim, the problem is ill-defined, that is, there is no one right answer but competing reasonable arguments can be made. In the instructor’s view, given the course materials and problem, students should make arguments for and against each of the five claims citing cases as shown in Table 1.


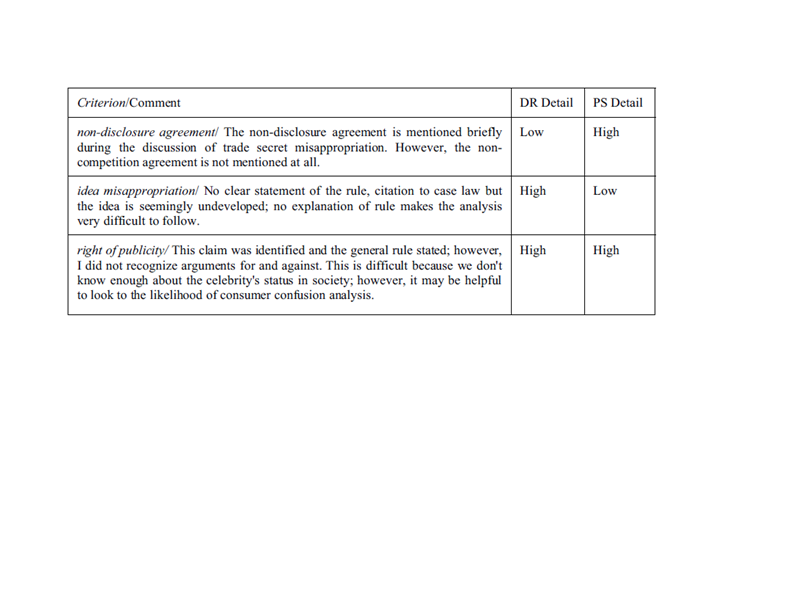
We also examined the peer comments elicited by the two rubrics for any differences. In a preliminary categorization of a sample of PS comments, we focused on the level of detail in the discussion of DR aspects and, separately, PS aspects. (Table 2) We observed that problem-specific rubric criteria can elicit comments that are high or low in either PS or DR detail. This justifies to some extent our motivation for exploring the different rubrics. Although the comments are always made (and delivered) in the context of some rubric criterion, even our preliminary investigation shows that a problem-specific prompt is no guarantee that a comment will mention problem-specific aspects. We will analyze comments more systematically, perhaps in terms of the depth and breadth of a comment’s discussion of PS / DR aspects. Given that a trade-secret misappropriation claim rests on multiple factors, identifying a factor, tying it to facts and making an argument could be construed as an indicator of depth, whereas mentioning multiple relevant factors could indicate breadth.
4.
Application of hierarchical Bayesian modelling ^
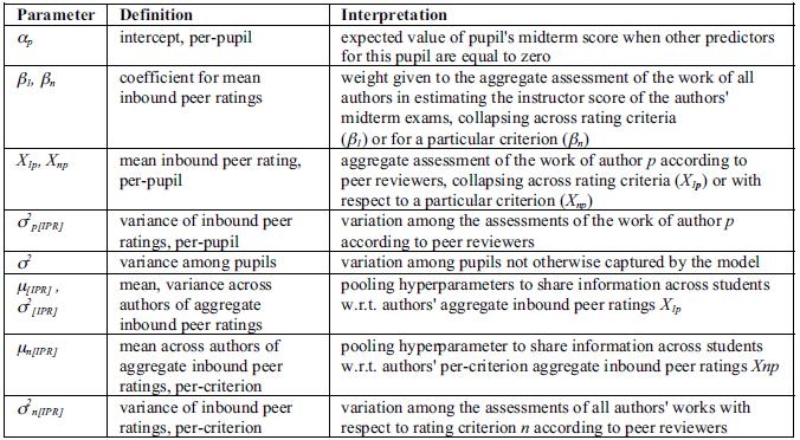

A comparison of more formal descriptions of the models, Table 4, illustrates these differences. Both models treat the response variable (the instructor-assigned midterm exam score) Yp as normally distributed, with mean µp, the per-pupil knowledge estimate, and overall variance estimate σ2 (Table 4, row 2). In the terminology of hierarchical modeling [8], model 5.1a is a «no pooling» regression because it does not pool (i.e., share) information across pupils. Each pupil is described via an individual intercept αp, an overall (between pupils) variance σ2, and an individual mean peer rating X1p with weight β1 (Table 4, row 2). A pupil’s inbound peer ratings are treated as normally distributed according to the pupil’s individual mean X1p and individual ratings variance σ2p[IPR]. Lacking strong prior beliefs, the individual pupil means X1p, are treated as normally distributed with «uninformative» priors (i.e., to avoid biasing the model): a mean of 0 and a variance of 1000.
In Model 5.2a, by contrast, information is shared (partially pooled) across pupils; what the model learns about one student informs the estimates of other students’ parameters. All individual pupil intercepts αp are deemed not independent, but drawn from a common distribution that is estimated from and constrains the estimates of the individual students’ intercepts.
Model 5.2a also differs by incorporating information on the distinct criteria of the inbound peer ratings (IPRs). Each observed IPR is modeled as normally distributed with mean Xnp that corresponds to the average of the ratings received by author p for rating criterion n and a variance for this criterion σ2n[IPR] that is shared across all pupils. (Table 4, row 3). The explanatory variable matrix X is altered to include one column per rating criterion, and the lone regression coefficient β1 is replaced by regression coefficients βn for each rating criterion n (i.e., 4 domain-relevant criteria and 5 problem-specific criteria.) Within each criterion, individual pupils’ mean inbound peer ratings Xnp are pooled by stipulating a shared «uninformative» prior distribution across students. Peer ratings from each criterion are centered about that criterion’s respective mean. Due to fewer observed ratings per pupil per criterion, per-dimension variances σ2n[IPR] were fitted.
A third model, 5.1b, adds partial pooling for intercepts αp and for the pupils individual means of inbound ratings X1p, but does not distinguish rating criteria.
5.
Discussion ^
We found that the hierarchical statistical analysis generated pedagogical information useful for instructors. The βn regression coefficients represent the importance of each criterion for estimating the instructor’s score of the average inbound peer rating (Q2). Two of the five problem-specific criteria, idea2 and rop, contributed to estimating the instructor’s score for at least 95% of the students, and a third, tsm, contributed for at least 80% of the students. (Table 5) By distinguishing among the rating criteria, model 5.2a improved the fit for the data (i.e., reduced DIC) for the PS criteria.

Consistency in signs of the βn coefficients provides a built-in sanity check for the model. A negative βn (as for the conclusion and writing DR criteria, Table 5) implies implausibly that high performance on, say, justifying a conclusion corresponds to a reduction in the instructor’s score. Such sign inconsistency may be due to collinearity (redundancy) of rating dimensions. The fact that the βn for problem-specific criteria (Table 5 bottom) were all positive is a good sign that the criteria are mutually independent and linearly additive (Q1).
Narrow credible intervals on the βn showed that the model is confident in estimating coefficients for four of the five PS criteria (i.e., all but idea1) (Q1). The wide credible interval for idea1 may indicate a lot of noise in how reviewers applied that criterion. Among the four domain-relevant criteria, estimates are confident for argument and issue but not for conclusion or writing. The combination of low confidence and negative signs for the conclusion and writing dimensions likely reflects high pairwise correlation between the mean inbound peer ratings for the DR criteria (Q1). Such correlation may cause instability and interactions among βn coefficients (even though it may not affect overall model fit). We found pairwise correlations between mean inbound peer ratings among all pairs of the DR rating dimensions, indicating that the dimensions may provide redundant information to authors; such correlations can also be computed over the Bayesian estimates of Xnp (Q1).
Knowing that some rubric criteria are problematic may suggest to the instructor that they need to be omitted or redefined. In addition, a criterion may not be adequately anchored; e.g., low σ2n[IPR] may indicate a criterion with too coarse a scale.
Model 5.2a can also show which concepts challenged which students by examining Xnp, the assessment of the work of author p on criterion n aggregated across peer reviewers. Positive skew in the distribution of Xnp is a sign that concept challenges many students. Students whose Xnp estimates are lower likely find the concept more challenging than students with higher Xnp estimates (Q4). As a validity measure of the aggregated peer ratings, non-Bayesian (i.e., classical) means of the ratings on the n=28 papers in the problem-specific condition correlated significantly with the ratings by a trained rater for each of the problem-specific criteria except idea2 [9]; this correlation could also be computed with respect to Xnp (Q3). Intuitively, idea2 may have challenged students because it was a claim against the main IP claimant, it is weak, and it is the second instance of a claim of misappropriation of ideas; test-taker «common sense» may have mislead students who may not have expected to encounter two instances of a claim in the same test question.
6.
Conclusions ^
This work points to new applications for AI in a legal educational context. The problem in Figure 2 challenges any current AI and Law program. Although Table 1 mentions trade secret factors and ownership of employee-generated information [1; 4], it is unlikely that any current program could drive intelligent tutoring for such problems.
AI can still play a role, however. Bayesian models of computer-supported peerreview yield pedagogically useful information about student learning and about grading schema. This suggests that there may be opportunities for further research in legal education to clarify links among content, instruction and assessment without the burden of having to develop strong domain models. Additionally, Bayesian models could be combined with other AI techniques to assist instructors. Since the models estimate lots of parameters, an intelligent user interface could manage these outputs. In related work, we are developing a «teacher-side dashboard» to provide teachers a comprehensible global overview of aggregated peer review information while allowing them to drill down to efficiently retrieve detailed assignment information for any particular student, who, according to the statistical analysis, is struggling with particular concepts. We are also developing Machine Learning (ML) tools to automatically process free-text feedback in peer reviews, as well as first and revised drafts of author papers, to detect pedagogically useful information for teachers such as (1) the types of changes peers comment on and authors implement as a result of feedback or (2) the presence of recurring comments across reviewers.
Additionally, authors could use argument diagramming [3; 11] to prepare or summarize arguments applying problem-specific criteria to legal problems, and students could review each other’s diagrams. Argument diagramming help systems [3], equipped with argument schema and critical questions [11], would help students to construct and review their diagrams; model-generated argument diagrams could serve as examples. AI techniques such as ML and Natural Language Processing could help reviewers improve their feedback so that it targets specific problems and suggests solutions [15]. The Bayesian models would then analyze student data from both the argument diagramming and subsequent argument writing exercises.
Intriguingly, CSPR in legal education may even help develop larger-scale AI and Law models. An instructor who creates an exam problem defines an answer key that relates broad legal concepts (e.g., right of publicity) to component concepts (e.g., is the right descendible) and ultimately to generic facts. These relations amount to a rubric (even more problem-specific than the PS rubric) on which to base a review interface. Across multiple peer review exercises, this relational information can link diverse legal concepts and generic facts in an ontology. Since the labor costs of creating ontologies are high, crowdsourcing by students and instructors could enable new applications in legal education and AI and Law.
7.
References ^
[1] Aleven, V. (2003) Using background knowledge in case-based legal reasoning: a computational model and an intelligent learning environment. Artif Intell 150:183–238.
[2] Andrade, H. (2000). Using rubrics to promote thinking and learning. Educational Leadership, 57(5),13.
[3] Ashley, K. (2009) Teaching a process model of legal argument with hypotheticals. Artificial Intelligence and Law.17:4:321–370.
[4] Ashley, K. and S. Brüninghaus (2006) «Computer Models for Legal Prediction.» Jurimetrics 46, 309–352.
[5] Carr, C. (2003) Using computer supported argument visualization to teach legal argumentation. In: Visualizing argumentation, 75–96. Springer, London.
[6] Centina, F., Routen, T., Hartmann, A. and Hegarty, C. (1995) Statutor: Too Intelligent by Half? Legal Knowledge Based Systems, Jurix ’95: Telecommunication and AI & Law:121–131.
[7] Cho, K., Schunn, C.D. (2007) Scaffolded writing and rewriting in the discipline: A web-based reciprocal peer review system. Computers and Education. 48.
[8] Gelman, A., Hill, J.: Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press (2006).
[9] Goldin, I. M. (2011, April 29). A Focus on Content: The Use of Rubrics in Peer Review to Guide Students and Instructors (PhD Dissertation). University of Pittsburgh, Pittsburgh, PA. http://etd.library.pitt.edu/ETD/available/etd-07142011-004329/
[10] Goldin, I.M., Ashley, K.D. (2010): Eliciting informative feedback in peer review: importance of problem-specific scaffolding. 10th International Conference on Intelligent Tutoring Systems. Pittsburgh.
[11] Gordon, T. F., Prakken, H., & Walton, D. (2007). The Carneades model of argument and burden of proof. Artificial Intelligence, 171(10–15), 875–896.
[12] Kruschke, J. K. (2010). What to believe: Bayesian methods for data analysis. Trends in Cognitive Sciences, 14(7), 293–300.
[13] Muntjewerff, A.J. (2009). ICT in Legal Education. In: German Law Journal (GLJ). Special Issue, Vol. 10, No. 06, pp. 359–406.
[14] Topping, K. J. (1998). Peer assessment between students in colleges and universities. Review of Educational Research, 68 (3), 249_76.
[15] Xiong, W., Litman, D., & Schunn, C. D. (2010). Assessing Reviewers’ Performance Based on Mining Problem Localization in Peer-Review Data. In 3rd Int’l Conf. on Educational Data Mining. Pittsburgh.
Kevin Ashley, University of Pittsburgh School of Law, Learning Research and Development Center, University of Pittsburgh Intelligent Systems Program and corresponding Author.
Ilya Goldin, University of Pittsburgh Intelligent Systems Program.
This article is republished with permission of IOS Press, the authors, and JURIX, Legal Knowledge and Information Systems from: Kathie M. Atkinson (ed.), Legal Knowledge Systems and Information Systems, JURIX 2011: The Twenty-Fourth Annual Conference, IOS Press, Amsterdam et al.





