1.
Introduction ^

2.
Task Description ^
Relevant provisions are encoded into a scheme consisting of a citation and nine attributes. It has been developed and used before the application of NLP/ML methods was considered. This is similar to provision «arguments» as used by [1], but different in that we do not distinguish different provision types and are only concerned with provisions regulating actions among agents of interest. However, the prescription attribute (see below) allows distinctions between «may», «must», etc. commandments, thereby representing more than one regulatory type of provision. Also, our work is distinct from [1] in that our semantic extraction is a classification task as opposed to an XML text markup.
- Acting agent – Who is acting? Represented as ten available slots, each consisting of primary (31 codes), secondary (ten codes) and «footnote» code (20 codes).
- Prescription – How is the action prescribed? (Must (not), can, etc.) Represented as one slot with five codes.
- Action – Which action is being taken? Represented as three slots (82 codes).
- Goal – What goal is the action supposed to achieve? Represented as five slots (143 codes)
- Purpose – For what purpose is the action being taken? Represented as four slots (four codes).
- Emergency type – Which types of emergencies are covered by the provision? Represented as seven slots (19 codes).
- Partner agent – Towards whom is the action taken? Represented as 15 available slots, each consisting of primary, secondary and «footnote» code.
- Timeframe – In what timeframe can/must the action be taken? Represented as two slots (150 codes, to be reduced to six in future work).
- Condition – Under what condition does the action need to be taken, e.g. during a declared emergency? Represented as three slots (172 codes).
3.
Our Framework ^
3.1.
Preprocessing ^
3.2.
Chunk Dataset ^
3.3.
Machine Learning Environment ^
To train the classifiers to predict the desired labels, supervised learning methods are applied. In a nutshell, ML classifiers provide methods to produce a mathematical function mapping a vector of input features onto an output label. The task is to represent each part of a provision as a finite set of features and a target label (i.e. the code assigned to an attribute). The majority of these feature-target pairs become so-called «training examples» which are used to compute an optimum mapping function, which can then be evaluated on the remaining testing examples.
3.4.
Bag-of-Words and TFIDF ^
During testing and training, each chunk is translated into a feature vector by means of a bag-of-words representation, i.e. the occurrence of each word becomes a feature, where the word is isolated from its context and lemmatized using the WordNet lemmatizer [4]. Stopwords («to», «for», etc.) and punctuation are removed before the translation.
We used a TFIDF representation (Term Frequency / Inverse Document Frequency), where a word’s feature value becomes a numerical measure of the relative importance of word i in chunk j. An advantage of using TFIDF values in the feature vector is that one can reduce the number of features by removing all terms whose maximum TFIDF value does not exceed some static threshold, i.e. the term is simply not informative enough. Finally, chunk size has been added as an additional feature to the vector.
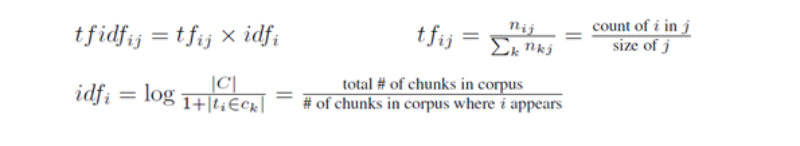
3.5.
Code Ranking ^
The first attempted prediction target is that of relevance, i.e. a binary decision about whether a chunk is relevant or not, where «relevant» means that it is worth coding, i.e. adding information pertinent for the public health analysis purposes. The training provisions are chunked and translated into a feature vector. If the chunk’s citation is found in the reference coding sheet (i.e. it had been coded by the human before), then the target attribute is 1 and 0 otherwise. A trained model is evaluated by having it predict the target attribute of a given feature vector from the validation data.
4.1.
Experiment Setup ^
Baselines The first baseline we use is that of the most frequent code (MFC). It is a simple predictor which determines the single most frequent code for a given attribute from the training data and predicts it for all the validation data. For relevance prediction, this is equivalent to predicting all chunks as irrelevant (Irr.), as only a small portion of the overall set of chunks in the working dataset is relevant (1342 / 6010). The second, more sophisticated baseline is a keyword enhanced version of the first (MFC+). As it would have been too big an endeavour to manually gather keywords for all labels of all attributes, we have used the terms of the small dictionary used in the manual coding process. It lists action types, purposes, timeframes, etc. The terms are lemmatized and used as signal terms (ST) for their respective codes with the most frequent code being the fallback mechanism in case none of the terms fire. Similarly, for relevance prediction, we have manually gathered a number of signal terms (e.g. «emergency», «flood», etc.) which flag a relevant chunk. Characteristics and peculiarities of these baselines will be addressed in light of the results further below in the discussion section.
4.2.
Evaluation Metrics ^
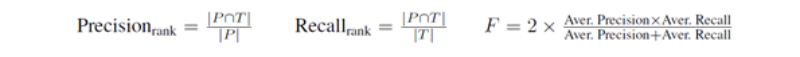
4.3.
Results ^

4.4.
Discussion ^
5.
Relationship to Prior Work ^
In the last decade, a growing body of AI&Law research has focused on the automatic classification and analysis of statutory texts using ML techniques. Some of these studies focused on relatively coarse classifications. For example, [9] employed SVMs to categorize legal documents as belonging to one of ten major types («Administrative Law», «Private Law», «Computer Science Law», etc.) achieving 85% accuracy. [11] achieved 63% accuracy with SVMs classifying statutory texts in terms of six abstract categories. [10] achieved 50% precision in a massively multiple label classification problem assigning directory codes and subject matters (e.g., intellectual property law, internal market, industrial and commercial property) using a perceptron-based approach.
Francesconi, et al., applied SVMs to categorize multi-sentence statutory texts in terms of regulatory functions (e.g., as a definition, prohibition, duty, etc.) with accuracies as high as 93% [1,8,6]. They used an NLP approach to extract typical features associated with each function achieving 83% precision and 74% recall. For example, the provision, «A controller intending to process personal data falling within the scope of application of this Act shall have to notify the Guarantor thereof,» is classified as «duty» with the features: Bearer (of the duty) = «controller», Action = «notification», Counterpart = «Guarantor», and Object = «process personal data». Once mapped into conceptual indices (i.e., legal thesauri, dictionaries, or ontologies), the extracted information could enable the retrieval of statutory texts responsive to conceptual queries, e.g. «Return all provisions that impose upon controllers duties regarding privacy protection of personal data.» [7]
6.
Conclusions ^
7.
Acknowledgements ^
8.
References ^
[1] Biagioli, C., Francesconi, E., Passerini, A., Montemagni, S. and Soria, C., Automatic semantics extraction in law documents, ICAIL 2005 Proceedings, 133–140, ACM Press (2005).
[2] de Maat, E., Krabben, K. andWinkels, R., Machine Learning versus Knowledge Based Classification of Legal Texts, Jurix 2010 Proceedings, pp. 87–96, R.G.F. Windkels (Ed.), IOS Press (2010).
[3] Dimitriadou, E., Hornik, K., Leisch, F., Meyer, D. andWeingessel, A. (2011). e1071: Misc Functions of the Dept. of Statistics, TU Wien. R package ver. 1.5-26. http://CRAN.R-project.org/package=e1071.
[4] Fellbaum, C. (1998, ed.), WordNet: An Electronic Lexical Database. Cambridge, MA: MIT Press.
[5] Bird, S., Loper, E., and Klein, E., (2009). Natural Language Processing with Python. O’Reilly Media.
[6] Francesconi, E., An Approach to Legal Rules Modelling and Automatic Learning. JURIX 2009 Proceedings (G. Governatori, Ed.), 59–68, IOS Press (2009).
[7] Francesconi, E., Montemagni, S., Peters,W., and Tiscornia, D., Integrating a Bottom-Up and Top-Down Methodology for Building Semantic Resources for the Multilingual Legal Domain. In Semantic Processing of Legal Texts. LNAI 6036, pp. 95–121. Springer: Berlin (2010).
[8] Francesconi, E. and Passerini, A., Automatic Classification of Provisions in Legislative Texts, Artificial Intelligence and Law 15:1–17 (2007).
[9] Francesconi, E. and Peruginelli, G., Integrated access to legal literature through automated semantic classification. Artificial Intelligence and Law 17:31–49 (2008).
[10] Mencía, E. and Fürnkranz, J., Efficient Multilabel Classification Algorithms for Large-Scale Problems in the Legal Domain. In Semantic Processing of Legal Texts. LNAI 6036, pp. 192–215. Springer (2010).
[11] Opsomer, R., De Meyer, G., Cornelis, C., Van Eetvelde, G., Exploiting Properties of Legislative Texts to Improve Classification Accuracy, Proc. Jurix 2009 (G. Governatori, ed.), 136–145, IOS Press (2009).
[12] Therneau, T. M. and Atkinson, B., R port by Ripley, B.,(2011). rpart: Recursive Partitioning. R package version 3.1–49. http://CRAN.R-project.org/package=rpart.
[13] R Development Core Team (2011). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0, URL http://www.R-project.org/.
Matthias Grabmair, Intelligent Systems Program, University of Pittsburgh, USA.
Kevin D. Ashley, Intelligent Systems Program, School of Law, University of Pittsburgh, USA.
Rebecca Hwa, Intelligent Systems Program, Department of Computer Science, University of Pittsburgh, USA.
Patricia M. Sweeney, Graduate School of Public Health, University of Pittsburgh, USA.
This article is republished with permission of IOS Press, the authors, and JURIX, Legal Knowledge and Information Systems from: Kathie M. Atkinson (ed.), Legal Knowledge Systems and Information Systems, JURIX 2011: The Twenty-Fourth Annual Conference, IOS Press, Amsterdam et al.





