1.
Die Sprache des Rechts ^
«Der Gesetzgeber soll denken wie ein Philosoph, aber reden wie ein Bauer», lautet die klassische Forderung an die Legislative, die in Deutschland zumeist entweder Rudolf von Ihering oder Gustav Radbruch, in der Schweiz in der Regel Eugen Huber zugeschrieben wird; in Österreich werden keine eigenen urheberrechtlichen Ansprüche erhoben, die Aussage aber wird nicht minder häufig zitiert. Der Gesetzgeber also soll: denken und reden. Das Denken des Gesetzgebers, das sich in der Dialektik des vorparlamentarischen und des parlamentarischen Diskurses manifestiert, ist ein Thema für sich; hier soll uns das Reden des Gesetzgebers interessieren.
Die supranationale Rechtsetzung der Europäischen Union hat dieses Problem neu dimensioniert. Europäische Rechtsnormen werden in der Regel in einer Arbeitssprache – allenfalls parallel in einer zweiten – konzipiert und verhandelt, aber in allen Amtssprachen kundgemacht und gelten als in ihnen verbindlich1. Somit stellt sich ganz unmittelbar, und mit größter praktischer Relevanz, die Frage nach der Möglichkeit äquivalenter Sprachtransformationen, also die Frage: Kann gewährleistet werden, dass die Bedeutung einer textuellen Aussage bei ihrer Übersetzung von einer Sprache in eine andere (analog aber natürlich auch schon bei ihrer Übersetzung von einer Formulierung in eine andere innerhalb ein und derselben Sprache) erhalten bleibt? Was aber ist die «Bedeutung»? Schon bei der Unbestimmtheit des Bedeutungsbegriffs setzt Quine an, wenn er die These von der Unbestimmtheit der Übersetzung entwickelt. Kann aber der Bedeutungsbegriff immerhin noch empirisch gefasst werden – Quine bezieht ihn bei Beobachtungsbegriffen auf die jeweils ausgelösten Reize, also auf die Sinneseindrücke, bei theoretischen Begriffen auf die jeweiligen empirischen Konsequenzen –, so scheitert der Versuch, der Übersetzung Bestimmtheit zu verleihen, an der oft wahrnehmbaren Mehrzahl möglicher empirischer Äquivalenzen: Begriffe und ihre Ausdrücke in einer Sprache stehen zumeist nicht in eindeutigen Beziehungen zu einander, und für Begriffe in unterschiedlichen Sprachen gilt das umso mehr. Mehr noch: Begriffe und ihre Ausdrücke sind eingebettet in eine komplexe, überdies von stetem Wandel des Sprachgebrauchs beeinflusste Bedeutungslandschaft; die geradezu universelle Polysemie wird noch unterfüttert durch zumindest konnotative Divergenz in den verschiedenen, einander überlagernden Lekten, von den Regiolekten über die Soziolekte bis hin zu Idiolekten.
Die Rechtssprache kann in mehrfacher Hinsicht als ein Soziolekt aufgefasst werden: Zum einen ist sie die Sprache einer am Recht geschulten sozialen Gruppe und reproduziert sich insofern selbstreferentiell mit der Tendenz, sich von anderen Soziolekten oder dem empirisch nur schwer fassbaren Konstrukt der «Alltagssprache» zu entfernen, wenn dieser Tendenz nicht proaktiv rechtspolitisch entgegengewirkt wird; die «plain language»-Bewegung in der angelsächsischen Welt ist der wirkmächtigste derartige Versuch in der jüngeren Vergangenheit2. In der Regel redet der Gesetzgeber nicht wie ein Bauer, sondern wie ein Jurist.
Zum anderen ist die Rechtssprache gebunden an ein makrosoziales System: Seit der frühen Neuzeit ist das der Territorial-, unter dem fortwirkenden Einfluss des 19. Jahrhunderts auch heute noch primär der Nationalstaat. Selbst Staaten, in denen, aus der linguistischen Ferne betrachtet, die «gleiche Sprache» gesprochen wird – und die sich unter Umständen sogar ganz bewusst um konvergente Sprachfortbildung bemühen mögen, wie dies Deutschland, Österreich und die Schweiz vermittels ihrer Rechtschreibkommissionen getan haben –, haben ganz unterschiedliche Rechtssprachen ausgebildet, was auch gar nicht überraschen kann, spiegeln diese doch die je unterschiedlichen normativen Konzepte wider, die ihrerseits wiederum die je unterschiedlichen Interessenkonstellationen reflektieren, welche in die getroffenen legislativen Entscheidungen eingeflossen sind. Der durch gemeinsame Wurzeln, beispielsweise im römischen Recht, vermittelte Zusammenhalt ist durch immer dynamischer verlaufende Rechtsentwicklung im 20. Jahrhundert – Carl Schmitt hat schon vor der Jahrhundertmitte von den «steigenden Motorisierungen der Gesetzgebungsmaschine» gesprochen (Schmitt 1943, 30) – weiter zurückgedrängt worden.
So lassen sich beispielsweise heute zumindest sieben deutsche Rechtssprachen nachweisen: die deutsche, die österreichische und die schweizerische, dann und darüber hinaus aber auch noch die liechtensteinische, die italienische (oder Südtiroler), die luxemburgische und die belgische. Inwieweit regionale Untergliederungen, wie beispielsweise Bundesländer bzw. Kantone, jeweils noch feinere rechtssprachliche Differenzierungen ausgebildet haben, bleibt vorläufig außer Betracht. Je nach zwischenstaatlicher Konstellation können die nationalen Rechtssprachen zu einander in divergenter oder konvergenter Entwicklung begriffen sein: Die liechtensteinische Rechtssprache beispielsweise war im 19. Jahrhundert durch die Rezeption österreichischen Rechts, beispielsweise des ABGB, geprägt, erfuhr jedoch nach dem Ersten Weltkrieg eine Umorientierung in Richtung auf die schweizerische, insbesondere seit damit begonnen wurde, das liechtensteinische Privatrecht in enger Anlehnung an das schweizerische Zivilgesetzbuch neu zu kodifizieren3.
Eine noch größere Vielfalt weisen naturgemäß die englischen, französischen, spanischen oder arabischen Rechtssprachen auf. Angesichts solcher Vielfältigkeit nimmt es nicht wunder, dass schon äquivalente Transformationen zwischen Rechtstexten, die jeweils einem solchen Kreis der ein und derselben «Hintergrundsprache» angehörenden Rechtssprachen zuzurechnen sind, auf oft nahezu unüberwindliche Schwierigkeiten stoßen. Nicht minder heikel erscheinen äquivalente Transformationen von Rechtstexten in «alltagssprachliche» Texte derselben nationalen Sprache: Selbst in jenen seltenen Fällen, in denen sich die Rechtssprache injektiv auf die Alltagssprache abbilden lässt, mag der entsprechende alltagssprachliche Begriff anders konnotiert sein als der rechtssprachliche («Studiengebühren» vs. «Studienbeiträge» aus der österreichischen Alltags- bzw. Rechtssprache gibt ein anschauliches Beispiel). Viel häufiger aber ist eine äquivalente Transformation aus der Rechts- in die Alltagssprache nur über Umschreibungen möglich, weil die Alltagssprache nicht über «maßgeschneiderte» Begriffe verfügt, um die normativen Konzepte auszudrücken.
Und nun kommt noch das «Mehrebenensystem» hinzu, wie es sich in Europa als die Überlagerung verschiedener normativer Systeme manifestiert, die zueinander teilweise im Verhältnis der Verdrängung, teilweise der Koexistenz, teilweise aber auch der Koevolution stehen. Eine kohärente «europäische» Rechtssprache hat sich noch gar nicht herausgebildet, vollzieht sich doch die europäische Rechtsetzung unter sprachmedialer Vermittlung durch Fragmente konzeptuell so unterschiedlicher Rechtssprachen wie insbesondere der englischen und der französischen4. Es entstehen rechtssprachliche schwimmende Inseln, die den breiten Strom des europäischen normativen Prozesses hinuntertreiben. Dieser Strom fließt naturgemäß nicht in einem regulierten Bett, sondern verzweigt sich nach jeder Engstelle – mit dieser Metapher könnte ein bestimmter europäischer Rechtsetzungsvorgang beschrieben werden – in ein Gewirr von Nebenarmen: mitgliedstaatlichen Rechtsetzungsprozessen, mit welchen umsetzungsbedürftige europäische Rechtsakte in nationales Recht transformiert (oder nicht umsetzungsbedürftige zumindest gelegentlich, beispielsweise durch Erlassung nationaler Organisationsvorschriften, begleitet) werden; für solche Transformationen ist substantielle Äquivalenz – bei vordefinierten Spielräumen für mögliche Divergenz – vorgeschrieben, was die nationale Umsetzung europäischer Rechtsakte zu einer rechtspolitisch schwierigen Gratwanderung zwischen Konzeptualisierung und Formulierung macht.
Liegen die europäischen Rechtsakte auch in grundsätzlich gleichermaßen authentischen Sprachfassungen in allen Amtssprachen vor, so belegt die praktische Erfahrung die Schwierigkeit, wenn nicht die Unmöglichkeit vollständiger äquivalenter Transformation von Rechtstexten. Der deklaratorische Anspruch des EuGH zielt daher auf einen Vergleich aller Sprachfassungen, um aus deren semantischer Schnittmenge so etwas wie den Telos des Rechtsaktes ableiten zu können5. Eingelöst werden kann dieser Anspruch naturgemäß kaum, weder praktisch (angesichts der sich durch einen solchen Vergleich ja nur potenzierenden Problematik sprachlicher Transformation) noch theoretisch (würde darin doch so etwas wie ein stochastisches Modell normativer Interpretationsrichtigkeit vorausgesetzt sein, dem es zumindest bisher an einer überzeugenden Begründung mangelt).
Aus dieser Erfahrung hat der EuGH, wenn auch uneingestanden, die im Prinzip gleiche Schlussfolgerung gezogen wie, eingestanden, der altösterreichische Reichsgesetzgeber, der vor einem analogen Problem gestanden ist: der Veröffentlichung der Reichsgesetze in den (damals acht) Sprachfassungen des Reichsgesetzblattes und der sich aus inäquivalenten sprachlichen Transformationen ergebenden Aporie, aus welcher nur durch Bevorzugung der «Produktionssprache» des jeweiligen Rechtsaktes – und das war im alten Österreich die deutsche, der durch § 2 des Reichsgesetzblattgesetzes, RGBl. Nr. 113/1869, der Authentizitätsvorrang zuerkannt war – ausgebrochen werden konnte. Der Rekurs auf die «Produktionssprache», in welcher der Rechtsakt ursprünglich konzipiert und gutteils auch der rechtspolitische Diskurs über den zu erlassenden Rechtsakt geführt worden ist, gewährleistet am ehesten die Rückbindung an den in ihm zum Ausdruck gebrachten rechtspolitischen Willen und damit die ihm innewohnende politische Legitimation. In der europäischen Rechtsetzung ist das heute in der Regel die englische oder die französische Sprache; dabei tritt in der Verfahrenspraxis des EuGH aufgrund seiner eigenen Arbeitssprache eine gewisse Präferenz für die französische Version zutage6. Die Lehre, nach dem Grundsatz, dass nicht sein könne, was nicht sein dürfe, leugnet freilich solche Präferenzen überwiegend7.
Die praktische Schwierigkeit, die substantielle normative Äquivalenz nicht nur an unterschiedlichen Sprachfassungen desselben europäischen Rechtsaktes, sondern umso mehr an nationalen Umsetzungsakten zu erkennen, ist gewiss nicht die einzige, aber eine Motivation gewesen, die den EuGH in der Ausbildung seiner «richtliniennahe» Umsetzung fordernden Judikatur geleitet hat.8 «Richtliniennah» ist sehr unmittelbar sprachgebunden zu verstehen: Am «richtliniennächsten» in diesem Sinn ist ein «copy and paste»-Verfahren, welches sprachliche Transformation durch sprachlichen Transfer ersetzt. Im Blick aber auf die zuvor festgestellte Unbestimmtheit bereits der sprachlichen Transformation des europäischen Rechtsaktes aus der «Produktionssprache» in die jeweilige nationale Amtssprache gewährleistet freilich nicht einmal dieses Verfahren die sichere normative Äquivalenz, sodass die Referenz auf die produktionssprachliche Fassung des europäischen Rechtsaktes im nationalen Umsetzungsprozess jedenfalls nicht unterbleiben darf.
Mehr noch als im nationalen Rechtsetzungsverfahren gewinnen im europäischen, und in der Transformation seiner Ergebnisse, datenbankgestützte Hilfsmittel an Bedeutung, welche die vom individuellen Intellekt nicht mehr beherrschbare terminologische Fülle auffangen, erschließen und für die sprachliche Transformation aufbereiten sollen9. Solche Terminologiedatenbanken, ihnen voran die von den Übersetzungsdiensten der EU entwickelte und verwendete Datenbank IATE (Inter–Active Terminology for Europe), entstehen durch annotierende Termextraktion aus den Texten und wirken durch ihre Verfügbarkeit auf den Prozess der Textproduktion zurück. Mögen sie heute auch noch recht flache Strukturen aufweisen und so die Komplexität semantischer Beziehungen nur sehr unzureichend abbilden, so bildet doch allein die Menge gesammelter Information einen wichtigen Grundstock, auf welchem künftige Ontologien des europäischen Rechtssystems aufsetzen können. Freilich stellt sich gerade diese Informationsmenge als Problem für sich dar: die in Datenbanken extrahierten Terminologien erweisen sich heute in der Praxis als ebenso wenig intellektuell beherrschbar wie die Textkorpora selbst. Und so muss auch auf der Metaebene der Terminologiedatenbanken noch ein weiteres Mal der Schritt zur Automatisierung, nunmehr zur automationsunterstützten Wartung der terminologischen Datenbestände, gesetzt werten. Diesen Schritt unternimmt das in enger Kooperation mit den europäischen Übersetzungsdiensten initiierte und durchgeführte Projekt LISE.
2.
Das Projekt LISE ^
Das Projekt Legal Language Interoperability Services (LISE) wird im Rahmen des ICT PSP Programms finanziert und hat zum Ziel, die Qualität von bereits bestehenden terminologischen Ressourcen auf unterschiedlichen Ebnen zu verbessern und eine Hilfestellung bei inter–institutioneller kollaborativer Terminologiearbeit zu bieten. Das Projekt wird von einem Konsortium von akademischen und institutionellen Partnern sowie privaten Unternehmen unter der Leitung des Zentrums für Translationswissenschaft der Universität Wien durchgeführt10. Kern des Projekts ist eine online Plattform, über die TerminologInnen und TerminologiekoordinatorInnen im öffentlichen und privaten Bereich eine internetbasierte Schnittstelle für die gemeinsam abgestimmte Terminologiearbeit zur Verfügung gestellt wird und Tools, um gezielt die Qualität ihrer Terminologiesammlungen zu verbessen. Die Forschung zu realen Workflow-Abläufen in der Terminologieerstellung und -verwaltung sowie die Erstellung von Best Practices im Bereich der Rechts– und Verwaltungsterminologie unterstützen die Toolentwicklung und stellen den zweiten Kernbereich des Forschungsprojektes dar11. Das LISE Projekt geht davon aus, dass ab einer bestimmten Menge von terminologischen Einträgen die Datenbestände nicht mehr überschaubar sind und nicht mehr alleine durch intellektuelle Arbeitsschritte manuell effizient gepflegt und aktualisiert werden können. Erschwerend kommt hinzu, dass viele verschiedene Personen über lange Zeiträume hinweg, oft Jahrzehnt an einer Ressource arbeiten, was zu einer mangelnden Einheitlichkeit führen kann: nicht alle Sprachen und Fachbereiche sind gleichmäßig abgedeckt; Doubletten und Einträge mit Rechtschreibfehlern treten auf. So banal es im Zeitalter von Rechtschreibkorrekturprogrammen klingen mag, es fehlt in vielen Terminologieverwaltungssystemen eine integrierte Rechtschreibkorrektur.
2.1.
Das LISE Terminologie-Service ^
Das workflowbasierte und -orientierte LISE Terminologie-Service besteht aus den folgenden Komponenten: den drei Tools Cleanup, Fillup, Omeo, die von ESTeam entwickelt und im Rahmen von LISE für terminologische Daten angepasst wurden, und einer kollaborativen Plattform für die interinstitutionelle Zusammenarbeit12. Die Ausgangsbasis, um das LISE Terminologie-Service anzuwenden bzw. zu testen, ist eine bereits bestehende terminologische Ressource. Die Daten werden exportiert (TBX, aber auch andere Formate können vom LISE Terminologie-Service verarbeitet werden) und dann analysiert. Die möglichen Fehler und Lücken mit den passenden Korrekturvorschlägen werden in den einzelnen Tools mit dezidierten Benutzeroberflächen den TerminologInnen präsentiert. Diese haben nun die Möglichkeit, die Vorschläge anzunehmen oder abzulehnen. Auf der Plattform kann zu schwierigen oder strittigen Fällen eine Diskussion eröffnet werden, die am Ende in eine Abstimmung münden kann. Diese Resultate können die BenutzerInnen wiederum in Ihre Entscheidung in den einzelnen Tools einfließen lassen (siehe Abbildung 1).
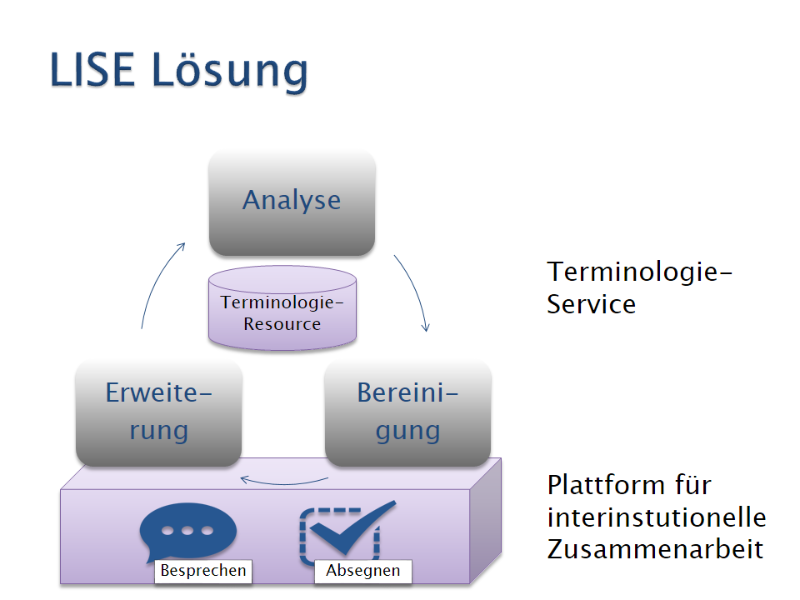
Abbildung 1: Das LISE Terminologie–Service
2.1.1.
Der Fall IATE ^
2.1.2.
Die LISE Komponenten ^
Im Folgenden werden die einzelnen Komponenten des LISE Terminologieservices näher beschrieben und erörtert.
2.1.2.1.
Cleanup Tool ^
Das Cleanup Tool spürt potentielle formale Fehler in terminologischen Datenbeständen auf und schlägt den BenutzerInnen Korrekturmöglichkeiten vor. Dieses Tool kann auch bei Rechtschreibreformen wirksam eingesetzt werden, um den gesamten Datenbestand zu aktualisieren13. In Cleanup (siehe Abbildung 2) werden unterschiedliche Fehlerkategorien angezeigt: Rechtschreibfehler (Misspelling, Canonisation) werden mit Hilfe von externen Wörterbüchern oder durch das Abgleichen mit dem gesamten Datenbestand ermittelt. Die Fehlerkategorie Language sammelt mögliche falsche Sprachzuweisungen, z.B. wird ein Englisches Wort, das als Deutsch klassifiziert wird, erkannt. Unter Equivalent werden innerhalb eines Eintrages gleich oder ähnlich lautende Termini hervorgehoben, z.B. old-age insurance und old age insurance, einmal mit und einmal ohne Bindestrich. Hier liegt es an den TerminologieexpertInnen zu entscheiden, ob diese Benennungen beide behalten werden sollen oder nicht, was stark von der Ausrichtung und vom Zweck der terminologischen Datenbank abhängt, v.a. ob sie übersetzungsorientiert oder normungsorientiert ist. IATE sammelt ursprünglich getrennte terminologische Datenbestände (Eurodicautom, Euterpe, TIS, u.a.) und ist daher eine besonders geeignete Fallstudie geeignet, da es beim Zusammenführen der Daten zu Dubletten gekommen ist. Im ausgewählten Teilbereich fanden sich 1324 potentielle Dubletten (Einträge), 5247 mögliche Rechtschreibfehler und 1497 potentielle falsche Sprachklassifikationen. Weiters hat die Analyse ergeben, dass sehr viele Einträge nur ein oder zwei Sprachen enthalten. Besonders hier zeigt sich das Potential für das Fillup Tool, das im Folgenden genauer beschrieben wird.

Abbildung 2: Cleanup Benutzeroberfläche – Schreibfehler im Wort Management
2.1.2.2.
Omeo Tool ^

Abbildung 3: Beispiel für ein Omeo Cluster
Für das Gruppieren werden u.a. Synonym-Suche und weitere linguistische Kriterien herangezogen14. Die Gruppierungen werden den BenutzerInnen im Omeo Interface präsentiert, sodass sie manuell angenommen oder abgelehnt werden können. Auf Basis der neuen Gruppierungen werden die Einträge beim Reimportieren der Daten in die ursprüngliche Datenbank zusammengeführt.
2.1.2.3.
Fillup Tool ^
Beim Fillup geht es darum, eine oder mehrere neue Sprachen zu einer bestehenden Datensammlung hinzuzufügen. Dies ist nützlich wenn z.B. neue Länder der EU beitreten. Es können auch bestehende unvollständige Einträge mit zusätzlichen Sprachen aufgefüllt werden. In IATE, einer eigentlich mehrsprachigen Datenbank, sind nur sehr wenige Einträge in allen Amtssprachen verfügbar und viele Einträge nur ein- oder zweisprachig. Fillup kann mit Hilfe von Translation Memorys oder anderen parallelen Textdaten Formulierungsvorschläge für bestehende Einträge in noch fehlenden Sprachen machen. Vor allem für kleine Sprachen, wie z.B. Maltesisch, oder eben für Beitrittskandidaten, die schnell einen Datenstock aufbauen wollen, hat Fillup Potential. Auch hier bleibt die endgültige Validierung den TerminologInnen überlassen.
2.1.2.4.
Kollaborative Plattform ^
Sehr oft sind viele unterschiedliche Personen, Abteilungen oder sogar Institutionen an der Erstellung bzw. Validierung von terminologischen Einträgen beteiligt. Nicht selten sind auch Fachexperten für die Revision miteingebunden. Diese Zusammenarbeit birgt etliche Schwierigkeiten, da es nicht immer möglich ist, sich persönlich zu treffen und ein E-Mail-Austausch die terminologische Arbeitsweise nicht optimal unterstützt. In diesem Fall kann die kollaborative Plattform Abhilfe schaffen: Sie ist webbasiert und sehr leicht zu handhaben. Jede Nutzerin bzw. jeder Nutzer kann einen Beitrag posten oder eine Diskussion eröffnen, die dann auch in einer Abstimmung münden kann. Die Informationen können auf der Plattform gebündelt werden; somit sind Entscheidungenprozesse leichter verfolgbar und automatisch gespeichert. Es können auch direkte Links zu den diskutierten terminologischen Einträgen gesetzt werden.
3.
Zusammenfassung und Ausblick ^
Der vorliegende Beitrag hat die Komplexität und die besonderen Merkmale der Rechts- und Verwaltungssprache, insbesondere die Sprache der Rechtssetzung aufgezeigt. Diese Komplexität vervielfältigt sich, wenn man die Rechtssprache nicht nur auf einer Ebene d.h. in diesem Fall in einem Nationalstaat betrachtet, sondern sich mehrsprachig kundgemachte Rechtssetzung, wie dies z.B. innerhalb der Europäischen Union der Fall ist, zuwendet. In diesem Kontext gewinnen datenbankgestützte Hilfsmittel, welche die vom individuellen Intellekt nicht mehr beherrschbare terminologische Fülle erschließen und für die sprachliche Transformation aufbereiten sollen, immer mehr an Bedeutung. Der vorliegende Beitrag hat aber auch aufgezeigt, dass diese terminologischen Ressourcen, wenn sie eine bestimmte Größe erreichen, wie dies etwas bei IATE der Fall ist, nicht mehr manuell gepflegt und aktualisiert werden können und dass darunter zumeist die Qualität der terminologischen Einträge leidet. Hier setzt das LISE Projekt an um durch semi-automatische Verfahren und Best Practices die Qualität in bereits bestehenden terminologischen Ressourcen zu verbessern. Im LISE Projekt wird die komplexe Rechts- und Verwaltungsterminologie für die Fallstudie herangezogen, die erarbeiteten Verfahren und Tools sind aber auch auf andere Fachbereiche und Terminologiesammlungen anwendbar.
4.
Literatur ^
Personenbeschreibungen
Günther Schefbeck
Leiter der Abteilung „Parlamentarische Dokumentation, Archiv und Statistik“ der Parlamentsdirektion, 1017 Wien-Parlament, Österreich
Guenther.Schefbeck@parlament.gv.at
Tanja Wissiki
Wissenschaftliche Mitarbeiterin, Zentrum für Translationswissenschaft, Universität Wien; 1190 Wien, Österreich: Tanja.Wissik@univie.ac.at
Elena Chuocchetti
Researcher, Europäische Akademie Bozen; 39100 Bozen, Italien; Elena.Chiocchetti@eurac.edu
Michael Wetzel
Senior Product Manager, ESTeam AB; 54522 Töreboda, Schweden; Michael@esteam.se
Günther Schefbeck, Leiter der Abteilung «Parlamentarische Dokumentation, Archiv und Statistik» der Parlamentsdirektion.
Tanja Wissik, Wissenschaftliche Mitarbeiterin, Zentrum für Translationswissenschaft, Universität Wien.
Elena Chiocchetti, Researcher, Europäische Akademie Bozen.
Michael Wetzel, Senior Product Manager, ESTeam AB.
- 1 vgl. EuGH, Rs 283/81, Entscheidungsgrund 18
- 2 vgl. Plain Writing Act of 2010, H.R. 946, Publ.L. 111—274
- 3 vgl. Kleinwaechter 1923
- 4 vgl. Burr/Müller 2004, Kjær 2007
- 5 vgl. EuGH Rs C–188/03
- 6 vgl. Colneric 2005
- 7 so etwa Stotz in Riesenhuber [Hg.] 2006, 538; a.A. Riesenhuber/Grundmann 2001, 529f.
- 8 vgl. Bast (2009) 504f
- 9 vgl. grundsätzlich Budin 1996
- 10 siehe http://www.lise-termservices.eu
- 11 vgl. Wissik 2012; Chiocchetti/Wissik 2012; Wetzel/Chiocchetti/Wissik 2012; Lusicky/Wissik 2012
- 12 vgl. Chiocchetti/Wissik 2012, Wetzel/Chiocchetti/Wissik 2012, Wetzel 2012, Lusicky/Wissik 2012
- 13 vgl. Chiocchetti/Ralli 2012
- 14 vgl. Chiocchetti/Wissik 2012a; Chiocchetti/Wissik 2012b; Wetzel/Chiocchetti/Wissik 2012; Lusicky/Wissik 2012





