1.
Ausgangssituation ^
Diverse Rückmeldungen aus der Verwaltungspraxis an die Autorin deuten hingegen darauf hin, dass BPMN für die fachliche Modellierung als zu kompliziert empfunden wird3. Dies rückt einen eigentlich selbstverständlichen Aspekt von Notationen in den Vordergrund, der insbesondere im Zusammenhang mit der oben angedeuteten Zielsetzung steht, unterschiedliche Prozesslösungen leicht vergleichen zu können: Prozessmodellierungsnotationen dienen nicht nur der Fixierung von Prozessen und als Voraussetzung oder Unterstützung, für diese Prozesse IT-Lösungen zu generieren. Sie sollen ebenso ein schnelles menschliches Erfassen der Prozesse ermöglichen und als Beschreibungshilfe zu den Prozessen oder als Verständigungsbasis für Gespräche, Vergleiche und Analysen zu den aufgezeichneten Prozessen dienen. Sie haben daher eine nicht unwesentliche sprachliche Komponente. Abstraktionen sollen hier Verständnis erleichtern, nicht erschweren!
Bei der Wahl einer Notation sind diverse Aspekte zu beachten. Eine gute Notation muss ausdrucksstark genug für die damit beabsichtigten Ziele sein und sollte leicht erlernbar, leicht verständlich bzw. schnell erfassbar sowie möglichst weit verbreitet sein.
2.
Zusammenhang zu Formalen Sprachen ^
So ist die Menge {P, müde, Ist P müde?} in diesem Sinne nach dem ersten Vorgehen eine formale Sprache. Ein sukzessiver Vergleich mit den Elementen der Menge gibt Gewissheit, ob eine gegebene Zeichenkette der Sprache angehört. «A» und «P ist müde.» etwa gehören nicht zu dieser Sprache, «müde» sowie, «Ist P müde?» schon. Entlang der zweiten Möglichkeit könnte das Alphabet {0,1} lauten und die Grammatik besagen, dass die 0 zugelassen ist und ansonsten jede Folge von Zeichen aus den Binärziffern, die nicht mit 0 beginnt. Dann wären 0 sowie 10010010 zulässige Zeichenfolgen dieser Sprache, nicht jedoch 001.
Etwas exakter lässt sich eine formale Sprache wie folgt definieren. Man benötigt eine endliche Menge Σ an Zeichen, die in der Sprache vorkommen dürfen, das Terminalalphabet. Im Beispiel wäre Σ = {0,1}. Darüber hinaus wird eine weitere endliche Menge V benötigt, das Nichtterminalalphabet. Die hierin enthaltenen Zeichen symbolisieren Variablen für Worte, die aus Zeichen des Alphabets Σ gebildet werden können. Darüber hinaus dürfen sie auch für das leere Wort stehen. Um Verwechslungen zu verhindern, müssen Zeichen aus dem Terminalalphabet von denen des Nichtterminalalphabets abweichen: Σ ∩ V = ∅. Ferner gibt es ein Startsymbol S ∈ V und eine endliche Regelmenge P, die Produktionen. Diese lassen sich als Mengen von Tupeln, links das Startwort, rechts das Zielwort ebenso in Mengenschreibweise definieren. Hierauf wird an dieser Stelle verzichtet. «Die einzige Forderung ist, dass das Wort auf der linken Seite einer Regel mindestens ein Nichtterminal enthält» [Asterroth & Bayer (2002) ,197]. Die von einer solchen Grammatik erzeugte Sprache besteht aus allen Wörtern, die sich aus dem Startsymbol durch Anwenden der Regeln ableiten lassen.
Folgende Ausführungen zum obigen Beispiel verdeutlichen das Vorgehen. So ist hier Σ = {0,1}. Es sei V = {S, A, B}. Die Regelmenge {(S, 0), (S, 1A), (A , ε), (A, B), (A, AB), (B,0), (B,1) } erzeugt die gewünschten Binärzahlen, wobei mit ε das leere Wort gemeint ist. In Tabelle 1 sind die Regeln in einer etwas leichter lesbaren Form dargestellt. Der senkrechte Strich deutet eine Alternative an.

Tabelle 1: Produktionen zum Beispiel Dualzahlen ohne führende Nullen
Durch Anwenden der Regeln wird deutlich, dass sich die gewünschten Dualzahlen ableiten lassen. Sà0 führt direkt zu 0. Sà1Aà1e liefert die 1. Weiter führt Sà1Aà1ABà1A0 bzw. zu 1A1. Es lässt sich also jede Dualzahl bilden, die mit 1 beginnt und mit 0 oder 1 endet, denn der Mittelteil A kann wieder zu 0 bzw. 1 aufgelöst werden und dies durch die AB-Regel beliebig oft5.
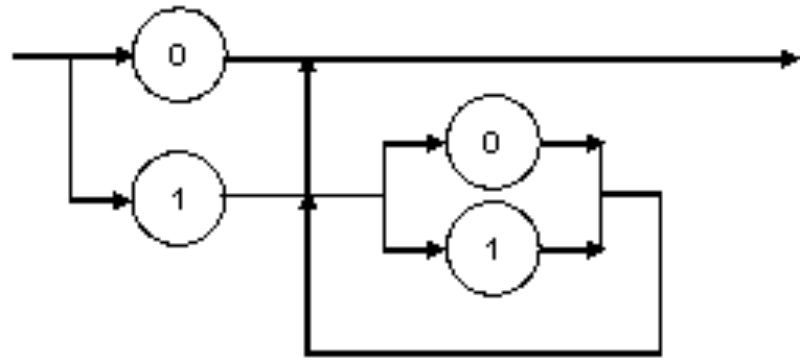
Abbildung 1: Syntaxdiagramm Dualzahl ohne führende Nullen (eigene Abbildung)
Der Theoretischen Informatik haben wir eine Klassifizierung der formalen Sprachen zu verdanken. Sprachen, zu denen man eine Regelmenge finden kann, bei denen auf der linken Seite nur Nichtterminalsymbole stehen – das war in dem gewählten Beispiel der Dualzahlbildung der Fall – heißen regulär. Sie lassen sich stets auch in Form eines Syntaxdiagramms darstellen [vgl. Asteroth & Baier, Seite 257 ff.] und eine Überprüfung, ob ein Wort einer solchen Sprache angehört ist recht effizient möglich. Auch Notationen mit ihrem Symbolvorrat und den dazu gehörigen Verwendungsregelkönnen als formale Sprachen verstanden werden.6 Hierauf basieren auch die von etlichen Modellierungstools vorgesehenen Möglichkeiten, syntaktische Fehler in den Modellierungen zu entdecken.
3.
Transfers zwischen verschiedenen Abstraktions- und Sprachstufen ^
In diesem Fall sollte im Vordergrund stehen, für den jeweiligen Anwendungszweck eine möglichst anschauliche Darstellung zu ermöglichen. Andererseits würde man danach trachten, dennoch formale Korrektheitsüberprüfungen zu ermöglichen, etwa indem man intern unsichtbare Umwandlungen des Modells in besser überprüfbare Anordnungen vornehmen ließe.7 Wiederum andere Anforderungen würden entstehen, wenn man zugleich eine automatische Workflowgenerierung des Prozesses im Sinn hat. Hier muss dann ein Transfer des Modells in einen Programmcode erfolgen.
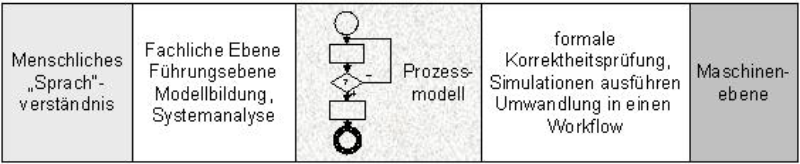
Abbildung 2: Ebenen, die mit einem Prozessmodell erreicht werden sollen (eigene Abbildung)
4.
Schlussfolgerungen ^
5.
Literatur ^
Asteroth, Alexander; Baier, Christel, Theoretische Informatik. Eine Einführung in die Berechenbarkeit, Komplexität und formale Sprachen mit 101 Beispielen, Pearson Studium, München, 1-12, 193 -424 (2002).
Deutscher Bundestag, Drucksache 17/11473. 17. Wahlperiode. Gesetzentwurf der Bundesregierung. Entwurf eines Gesetzes zur Förderung der elektronischen Verwaltung sowie zur Änderung weiterer Vorschriften. In: Bundesminsiterium des Innern (Hersg.) http://www.bmi.bund.de/SharedDocs/Downloads/DE/Gesetzestexte/Entwuerfe/ Entwurf_EGovG.pdf?__blob=publication File aufgerufen 30.12.2012 (2012).
Hofstadter, Douglas R., Gödel, Escher, Bach, ein Endloses Geflochtenes Band, Klett-Cotta, Stuttgart (1985).
Freund, Jakob; Rücker, Bernd, Praxishandbuch BPMN 2.0, Hanser, München, Wien (2009).
Rechenberg, Peter, Was ist Informatik. Eine allgemeinverständliche Einführung, Hanser, München, Wien, 180-185 u. 254-256 (2000).
Dagmar Lück-Schneider, Professorin für Verwaltungsinformatik, Hochschule für Wirtschaft und Recht Berlin, Fachbereich Allgemeine Verwaltung.
- 1 Im Folgenden wird nur noch von Notationen gesprochen. Nähere Erläuterungen folgen in Abschnitt 2.
- 2 Business Process Modeling Notation.
- 3 Dem müsste man sicherlich noch näher empirisch nachgehen. Am Ende des Beitrags wird eine Hypothese aufgestellt, warum BPMN in den Fachgebieten als schwierig erlebt wird.
- 4 Der Aspekt institutionsübergreifender Lösungsentwicklung wird weiter unten noch aufgegriffen.
- 5 Bei Asterroth und Bayer, Seite 210 findet man die entsprechenden Regeln für natürliche Dezimalzahlen ohne führende Nullen.
- 6 Für eine Aussage darüber, welchen der in der Theoretischen Informatik behandelten Klassen sie zuzuordnen wären, müssten entsprechend Einzelnachweise geführt werden.
- 7 Hier haben die in der Theoretischen Informatik weiterhin betriebenen Äquivalenzbetrachtungen von Sprachen ihre Berechtigung!





