1.
Introduction ^
1.1.
Translation Service ^
We have chosen Moses (http://www.statmt.org/moses/manual/manual.pdf) as the baseline tool for our work. It is a state-of-the-art SMT tool, which has gained tremendous momentum over the last few years within the MT community and is used in small and large scale projects all over the world.
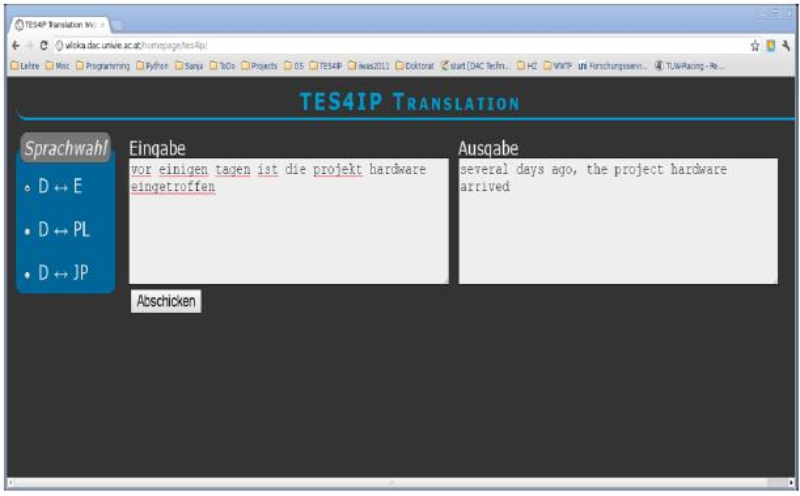
Illustration 1: Web Interface of the translation service
In order to provide the best possible functionality we have focused on the following technological and functional requirements:
- Technological: For seamless integration with other modules and services of the TES4IP platform the MT task has to offer UTF-8 character support for the various language specific special characters and high error recovery, avoiding crashes, due to noisy input data (wrong characters, misplaced carriage returns, etc.).
- Functional: The functional integration demands the swift delivery of translations of queries and sub-queries. Ideally the system should offer a number of translation candidates from which the user can choose the best fit. A combination with Computer Assisted Translation (CAT) services is possible by displaying PoS tags, word fragmentation (Japanese and Chinese) and displaying relevant sentences from the training corpus, which is not a functionality of the MT system as such, but can be integrated with low overhead.
- The MT service should be available to the user at all times within the process of linguistic analysis. Hence speed and ease of use are the key. A mark/copy/paste functionality within the working environment is vital, to allow for convenient usage. The graphical display of the results, i.e. translation candidates, as mentioned in point 1 and 2 has to be integrated in such a way, that they won’t clutter the workspace but offer the most crucial results.
2.
Language Analysis ^
3.
Applications for Mobile Devices ^
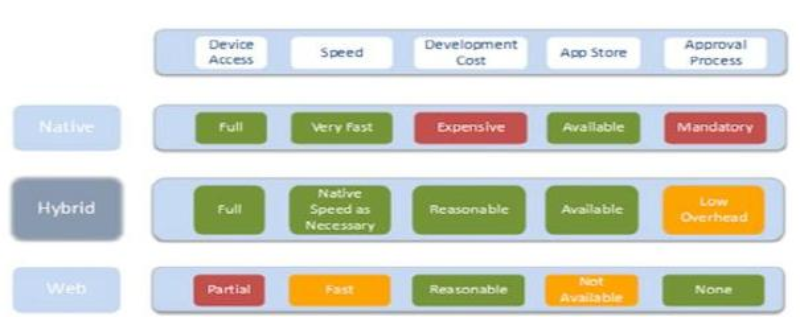
Illustration 2: Advantages of hybrid development on mobile devices (http://www.scribd.com/doc/50805466/Native-Web-or-Hybrid-Mobile-App-Development)
4.
Conclusion ^
5.
Literature ^
Christian Boitet, Herve Blanchon, Mark Seligman, Valerie Bellynck: Evolution of MT with the Web: In: Proceedings of the Conference «Machine Translation 25 Years On»: Cranfield, England (2009).
Peter Brown et al.: A statistical approach to machine translation, Comput. Linguist. MIT Press 16, 2, 79–85 (1990).
Philipp Koehn et al: Moses: Open source toolkit for statistical machine translation, pp. 177–180. Association for Computational Linguistics (2007).
Bartholomäus Wloka, Werner Winiwarter: Enhancing Language Learning and Translation with Ubiquitous Applications, pp. 203-210. International Conference on Advances in Mobile Computing and Multimedia, ACM (2010).
Bartholomäus Wloka, Werner Winiwarter: TREF – TRanslation Enhancement Framework for Japanese-English, pp. 541-546, International Multiconference on Computer Science and Information Technology (2010).
Bartholomäus Wloka, Dissertant, Österreichische Akademie der Wissenschaften, Institut für Corpuslinguistik und Texttechnologie.
Gerhard Budin, Professor, Universität Wien, Zentrum für Translationswissenschaften.
Werner Winiwarter, Professor, Universität Wien, Forschungsgruppe Data Analytics and Computing.





