1.
Einführung ^
Unser Ziel ist, an das Thema mit aktuellen Werkzeugen der Corpuslinguistik bzw. der digital humanities1 heranzugehen. Insbesondere sollen bei der Analyse die Plattform http://voyeurtools.org/ sowie der Google ngramviewer (Michel et al. 2011) zum Einsatz kommen. Ergänzend werden auch die Möglichkeiten von GATE (general architecture for text engineering, http://gate.ac.uk/) kurz vorgestellt (Kap. 2).
2.
Verwendete texttechnologische Werkzeuge ^
Die Konjunktur corpuslinguistischer Untersuchungsverfahren in den letzten beiden Jahrzehnten hat eine Vielzahl von Tools hervorgebracht, die hier nicht im Einzelnen referiert werden können. Wir beschränken uns nachfolgend auf Werkzeuge, die
- die Prozesskette der Arbeitsschritte bei der Verarbeitung digitaler Textmengen unterstützen oder entsprechende Ressourcen bereitstellen,
- frei verfügbar sind und
- vergleichsweise leicht, d. h. ohne erhebliche Kenntnisse im Bereich Texttechnologie (Markup, Annotation) oder praktische Informatik (Programmierung) eingesetzt werden können.
2.1.
Voyant Tools ^
Bei den Voyant Tools handelt es sich um eine von den kanadischen digital humanists Stéfan Sinclair und George Rockwell entwickelte webbasierte Plattform für die Aufbereitung und Analyse von Textcorpora (Dokumentation: http://docs.voyant-tools.org/). Die hier verfügbaren Tools, die aus einer Reihe bereits länger laufender Vorgängerprojekte entstanden sind, senken die Eintrittsschwelle für die texttechnologische Arbeit an Dokumenten auch im Vergleich zu Infrastrukturen wie GATE (s. u. Kap. 2.3) deutlich ab,
- da sie unmittelbar in einem Browser ausgeführt werden können und
- keine lokale Verarbeitung auf dem eigenen Rechner erforderlich ist.
2.2.
Google NGram Viewer ^
2.3.
GATE – General Architecture for Text Engineering ^
3.
Textauswahl und -aufbereitung ^
Die Normtexte wurden aus den jeweiligen nationalen Fachinformationssystemen RIS bzw. Juris Anfang 2013 heruntergeladen.2 Für beide Dokumente wurde eine geringfügige Aufbereitung durchgeführt (Formatkonversion, Entfernen von automatisch generierten Seitenheadern und Seitenzahlen, Entfernung von Anmerkungen etc.). Eine Grundformenreduktion wurde nicht vorgenommen, um ggf. auch Flexionsformen gesondert betrachten zu können.
4.
Behandelte Fragestellungen ^
5.
Ergebnisse ^
5.1.
Basisdaten zum Corpus ^
| Anzahl Token | Anzahl Types | Type-Token-Relation | |
| ABGB | 78181 | 9417 | 8,30 |
| BGB | 176632 | 11230 | 15,73 |
Tabelle 1: Types, Tokens und Type-Token-Relation in beiden Normtexten
Neben den summarischen Daten spiegeln auch Frequenzlisten unterschiedliche Schwerpunktsetzungen in den beiden Normtexten wider. Dabei wurde hier keine orthographische Normalisierung vorgenommen, was bedeutet, dass die einen älteren Sprachstand reflektierenden, heute nicht mehr gebräuchlichen Formen im ABGB hervorstechen. So kommt beispielsweise das Wort «Obsorge», das im ABGB nach Eliminierung der Stoppwörter immerhin das 13.-häufigste Wort darstellt, im BGB nicht vor und wird auch in der juristischen Fachsprache in Deutschland nicht verwendet. Zwar dürfte das Wort in der Allgemeinsprache in Österreich wie in Deutschland veraltet wirken (so der Duden in der 25. Auflage 2009), weiterhin aber in der Rechtssprache verwendet werden.
| Rang | Wort im ABGB | Frequenz | Wort im BGB | Frequenz |
| 1. | person | 198 | vorschriften | 546 |
| 2. | Sachen | 163 | gilt | 521 |
| 3. | Bey | 153 | ehegatten | 463 |
| 4. | Kind | 137 | verlangen | 436 |
| 5. | Erben | 133 | soweit | 388 |
| 6. | Kindes | 126 | anwendung | 379 |
| 7. | Art | 122 | gläubiger | 370 |
| 8. | erblasser | 119 | verpflichtet | 315 |
| 9. | personen | 116 | leistung | 304 |
| 10. | Gericht | 112 | eigentümer | 267 |
| 11. | bestimmt | 105 | ehegatte | 266 |
| 12. | gläubiger | 105 | frist | 257 |
| 13. | Obsorge | 103 | erben | 249 |
| 14. | Vertrag | 93 | vertrag | 249 |
| 15. | Gilt | 92 | bestimmt | 243 |
| 16. | rücksicht | 86 | forderung | 240 |
| 17. | Eltern | 84 | schuldner | 233 |
| 18. | Falle | 80 | entsprechende | 231 |
| 19. | anspruch | 79 | finden | 229 |
| 20. | ehegatten | 78 | kindes | 226 |
| 21. | erbschaft | 78 | kind | 224 |
| 22. | vorschriften | 78 | grund | 222 |
| 23. | Letzten | 76 | anspruch | 213 |
| 24. | gesetzlichen | 74 | erblasser | 213 |
| 25. | fordern | 72 | verfügung | 210 |
Tabelle 2: Rangliste der jeweils 25 häufigsten Wörter in ABGB (links) und BGB (rechts), nach Stoppworteliminierung
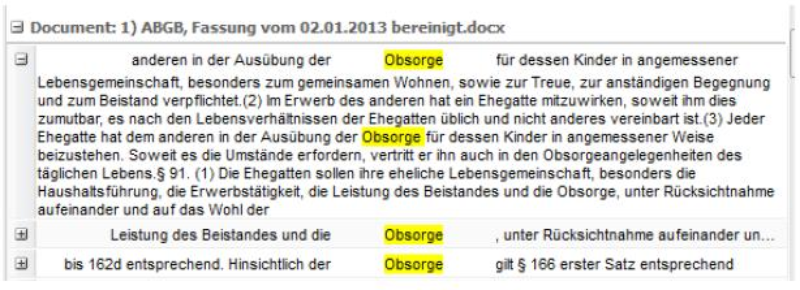
Abbildung 1: KWIC-Darstellung für «Obsorge», Corpus ABGB, mit erweiterter Kontextdarstellung für die erste Fundstelle
5.2.
«Word Trends» – relative Verteilung von Wörtern im Corpus ^
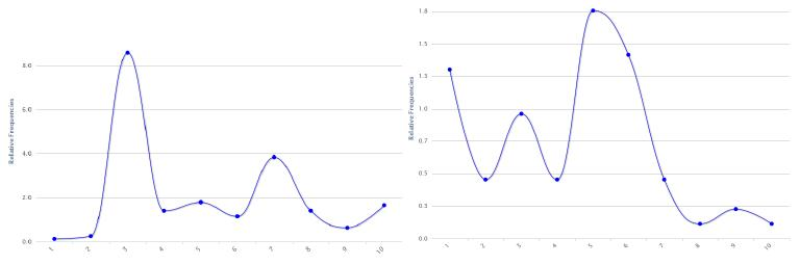
Abbildung 2: Relative Häufigkeiten für «Sachen» in ABGB (links) bzw. BGB (rechts), Textaufteilung jeweils in zehn Segmente.
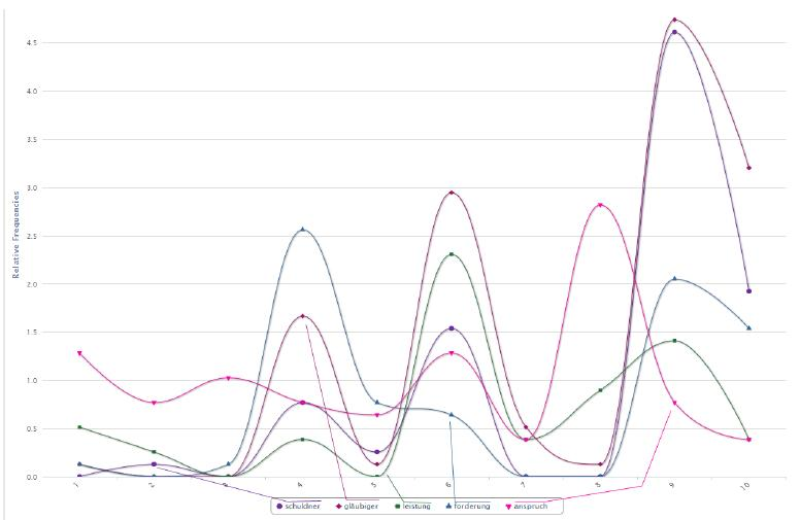
Abbildung 3: Verteilung der Begriffe «Schuldner», «Gläubiger», «Leistung», «Forderung», «Anspruch» auf 10 Segmente im ABGB
5.3.
Vergleich von Wortwolken ^

Abbildung 4: Wortwolke für ABGB (links) und BGB (rechts), jeweils ohne Stoppwörter und Zahlwörter
5.4.
Weitere Werkzeuge ^
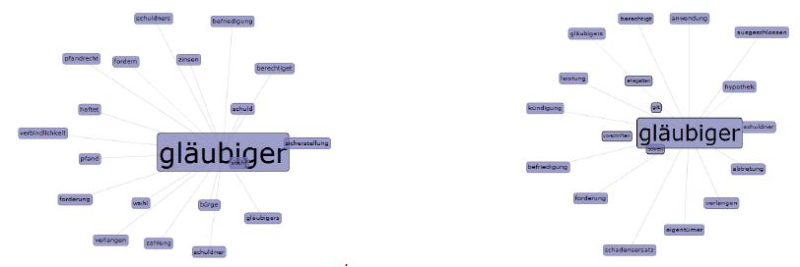
Abbildung 5: Kollokationsgraphen zu «Gläubiger» in ABGB (links) bzw. BGB (rechts).
5.5.
Arbeit mit dem Google Ngram Viewer ^
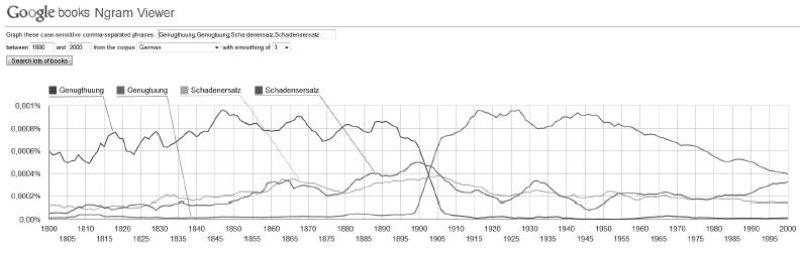
Abbildung 6: Google Ngram-Analysen für «Genugthuung», «Genugtuung», «Schadenersatz» und «Schadensersatz»
6.
Fazit und Ausblick ^
7.
Literatur ^
Cunningham, Hamish, GATE, a General Architecture for Text Engineering. In: Computers and the Humanities, Band 36, Heft 2, S. 223-254. DOI: 10.1023/A:1014348124664.
Cunningham, et al. Text Processing with GATE (Version 6).University of Sheffield, Department of Computer Science, 15. April 2011. ISBN 0956599311. Online: http://gate.ac.uk/userguide [Zugriff 1 / 13].
Deutsch, Andreas, »Billig streitet die Vermuthung, daß ein Gesetz bedachtsam abgefaßt« – Zu Wortwahl und Gesetzessprache im ABGB. In: Dölemeyer, Barbara, Mohnhaupt, Heinz (Hrsg.), 200 Jahre ABGB (1811 – 2011). Die österreichische Kodifikation im internationalen Kontext. Klostermann, Frankfurt/Main (2012).
Ferrucci, David, Lally, Adam, UIMA: An Architectural Approach to Unstructured Information Processing in the Corporate Research Environment, Natural Language Engineering, Bd. 10, Nr. 10, S. 327-348, Online: http://dx.doi.org/10.1017/S1351324904003523.
Michel, Jean-Baptiste et al., Quantitative Analysis of Culture Using Millions of Digitized Books, In: Science Bd. 331, Heft 6014, S. 176-182 (2011).
Koziol, Helmut, Bydlinski, Peter, Bollenberger, Raimund (Hrsg.), ABGB. Allgemeines Bürgerliches Gesetzbuch. Kurzkommentar zum ABGB. 3., überarbeitete u. erweiterte Auflage, Springer, Wien / New York (2010), zit. als KBB3.
Rössler, Paul, Entwicklungstendenzen der österreichischen Rechtssprache seit dem ausgehenden 18. Jahrhundert. Eine syntaktische, stilistische und lexikalische Untersuchung von Studiengesetzen und –verordnungen. Frankfurt am Main, Peter Lang [= Schriften zur deutschen Sprache in Österreich, Bd. 16] (1994).
Sinclair, James, Cardew-Hall, Michael, The folksonomy tag cloud: when is it useful? In: Journal of Information Science, Bd. 34, Heft 1, S. 15-29. Online: DOI:10.1177/0165551506078083 (2008)
Thiel, Thomas, Digital Humanities. Eine empirische Wende für die Geisteswissenschaften. In: FAZ.net [Online-Ausgabe der Frankfurter Allgemeinen Zeitung], 24. Juli 2012, Online: http://www.faz.net/aktuell/feuilleton/forschung-und-lehre/digital-humanities-eine-empirische-wende-fuer-die-geisteswissenschaften-11830514.html [Zugriff 1 / 2013].
Bettina Mielke, Vorsitzende Richterin am Landgericht Regensburg, Lehrbeauftragte an der Universität Regensburg.
Christian Wolff, Professor, Institut für Information und Medien, Sprache und Kultur, Lehrstuhl für Medieninformatik.
- 1 Die Autoren danken dem Regensburger digital humanist Manuel Burghardt für die Beratung bei der Auswahl und Anwendung der Werkzeuge.
- 2 http://www.ris.bka.gv.at/GeltendeFassung/Bundesnormen/10001622/ ABGB%2c%20Fassung%20vom%2010.01.2013.rtf bzw. http://www.gesetze-im-internet.de/bgb/ BJNR001950896.html.





