1.
Einleitung ^
Das Rechtsinformationssystem des Bundes ist im Internet unter dem URL http://www.ris.bka.gv.at/ kostenfrei für jeden (weltweit) über Webseiten zugänglich. Seit kurzem existieren auch «Apps», um einen einfacheren Zugriff von mobilen Geräten aus zu erlauben1. Diese bilden jedoch «lediglich» die Möglichkeiten der Webseiten nach und bieten eine der typischerweise geringeren Bildschirmgröße angepassten Benutzerschnittstelle, besitzen jedoch keine Zusatzfunktionen. Auch die Webseiten erlauben lediglich eine Suche (wenn auch nach vielen Kriterien) nach einzelnen Paragraphen sowie den Zugriff auf ganze Gesetze. Dies allerdings sowohl zum derzeitigen wie auch früheren Zeitpunkten (in gewissem Maße fand eine Rückerfassung statt). Zusätzlich zu den Gesetzen bzw. Gesetzblättern sind weitere Daten verfügbar, z.B. Entscheidungen div. Gerichte und anderer Behörden (etwa der Datenschutzkommission), Landes-/Gemeinderecht (unvollständig!) sowie ausgewählte Erlässe. Ein ähnliches Verzeichnis, jedoch mit anderem Inhalt, stellt die Finanzdokumentation dar (Findok2). Bei ihr bestehen auch explizite Regelungen für eine kommerzielle Verwertung, was jedoch eine hohe Lizenzgebühr erfordert3.
Genau dies wird aber u.U. gewünscht, um sich nicht nur selbst eine beliebige Sammlung nach eigenen Bedürfnissen zusammenstellen zu können, sondern um diese auch elektronisch zur Verfügung zu haben (z.B. für Volltextsuche) sowie einfach aktualisieren zu können. Damit kann ein Warten auf eine neue Auflage eines Druckwerkes vermieden werden. Zusätzlich könnte ein derartiges elektronisches Verzeichnis noch weitere Funktionen unterstützen:
- Auch Entscheidungen von Gerichten bzw. Behörden können aufgenommen werden (insofern im RIS enthalten), sowohl zusätzlich zu einem Gesetz/Paragraphen (z.B. vollautomatisch alle entsprechend annotierten Entscheidungen, aber ev. auch per Volltextsuche identifizierte) wie auch als reine Entscheidungssammlung.
- Eine elektronische Sammlung erlaubt ein einfaches Teilen mit anderen, sodass auch eher selten benötigte Sammlungen für Spezialgebiete analog «Crowdsourcing» vorbereitet sein könnten.
- Basierend auf einer konkreten Instanz einer Sammlung wäre es möglich Differenzen festzustellen, d.h. Benachrichtigungen zu verschicken wenn sich Änderungen durch Novellen ergeben, oder eine Gegenüberstellung zu erzeugen: Alter Text/Inhalt <-> Neuer Text/Inhalt.
2.
Das RIS: Technische Umsetzung ^
Die Inhalte des RIS (z.B. Bundesrecht) sind so organisiert, dass jeder Paragraph / Entscheidung / Erlass / … ein eigenes Dokument darstellt und eine eindeutige und einmalige Dokumentennummer erhält. Diese ändert sich nicht mehr, sondern bei einer Novellierung dieses Paragraphen wird ein neues Dokument mit verändertem Inhalt angelegt, das ähnliche Metadaten enthält (also u.A. zum gleichen Gesetz gehört, dieselbe Paragraphennummer besitzt etc., aber z.B. ein anderes Datum des Inkrafttreten). Dokumente im RIS werden niemals gelöscht (eingeschränkter Lebenszyklus), da sie aus Dokumentationsgründen erhalten bleiben müssen. Sie sind intern in XML repräsentiert, wobei über die Webseite nur ein Abruf von daraus erzeugten HTML, PDF und RTF-Dokumenten möglich ist. Einzelne Großbereiche können (kostenpflichtig!) als Gesamtauszug auch im XML-Format bezogen werden (siehe oben analog der FinDok – ursprünglich auf CD-ROM, heute per USB-Festplatte oder Online-Zugang4).
3.
Open Government Data ^
- Primärquelle: Es besteht ein «direkter» Zugang zur Datenbank, sodass man nicht auf potentiell veraltete Kopien (siehe oben: käuflich erworbene Extrakte auf Datenträgern) angewiesen ist.
- Maschinenlesbarkeit: Wie oben erwähnt, sind die Daten im Ursprung in XML gespeichert, doch über die Webseiten ist ein Zugriff auf diesen «Quelltext» nicht möglich. HTML, PDF und RTF sind jedoch für eine maschinelle Weiterverarbeitung weniger geeignet. Über diese Schnittstelle werden die Dokumente hingegen im XML-Format ausgeliefert.
- Verwendung offener Standards/Dokumentation: Durch den Einsatz von XML und genauer Definition des Datenformats wird eine sinnvolle Weiterverarbeitung erst möglich, ohne vorher eine umfangreiche Inhaltsanalyse vorzunehmen. Weiters ist bei offizieller Dokumentation auch von Stabilität des Formats (seltene Änderungen) auszugehen.
4.
Datenabgriff von Dritt-Webseiten und ihre Weiterverwendung ^
4.1.
Screen Scraping ^
4.1.1.
Technische Umsetzung ^
4.1.2.
Rechtliche Beurteilung ^
- Kann der Zugriff auf eine Webseite auf Menschen beschränkt werden, d.h. können Computer als «Besucher» ausgeschlossen werden?
Dazu sind weiters die Entscheidungen zur Google-Bildersuche11 relevant, weil dort ähnliche Fälle entschieden wurden: Wenn etwas ins Internet gestellt wird und keine Gegenmaßnahmen (siehe unten) ergriffen wurden, so ist von einer Einwilligung für eine Speicherung sowie Zugänglichmachung von Vorschaubildern auszugehen, was zwangsweise auch den bloßen Zugriff beinhaltet. Üblicherweise wird man allerdings – im Gegensatz zu Suchmaschinen – nicht davon ausgehen können, dass eine Webseite für einen automatisierten Zugriff in Form von Screen Scraping zugänglich gemacht wurde, ebenso werden von den interessanten Daten kaum «Vorschaubilder», also in ihrem Informationsgehalt stark reduzierte Versionen, ausgelesen bzw. gespeichert. Umgekehrt kann jedoch nicht davon ausgegangen werden, dass eine Verpflichtung besteht, bestimmte Daten abzurufen (Datei robots.txt) oder auszuwerten (META-Tags), da laut der Entscheidung sogar individuelle direkt mitgeteilte Verbote irrelevant sind, sofern keine hinreichenden Schutzvorkehrungen (allgemein oder spezifisch) getroffen wurden – und sowohl robots.txt als auch META-Tags sind lediglich Erklärungen an die Allgemeinheit, aber keine Sicherungsmaßnahme.12 Details hierzu sowie einige Urteile wurden schon in einem Artikel zu einer Vorversion der Software publiziert13.
- 2. Wenn Gegenmaßnahmen ergriffen werden, dürfen diese, bzw. welche davon, umgangen werden?
4.1.3.
Vor- und Nachteile ^
» markiert etwa die Überschrift eines Paragraphen, sodass sich daraus ableiten lässt, dass hier ein neuer Paragraph in einem ganzen Gesetz beginnt).
4.2.
Proxy ^
4.2.1.
Technische Umsetzung ^
4.2.2.
Rechtliche Beurteilung ^
Vom urheberrechtlichen Standpunkt aus wird vom Server eine Vervielfältigung erstellt und an einen einzelnen Client weitergereicht. Allerdings erfolgt dies vollkommen automatisiert und ausschließlich auf Anweisung eines echten Dritten, des Endbenutzers. Die Vervielfältigung kann daher diesem zugerechnet werden. Potentiell kommt auch eine flüchtige/begleitende Vervielfältigung in Frage, was jedoch an einer eigenen wirtschaftlichen Bedeutung der Vervielfältigung scheitern kann: Wird die Seite mit eigener Werbung umrahmt, oder Daten hierfür extrahiert (um Informationen über Interessen des Nutzers zu erlangen), so kann nicht mehr davon gesprochen werden, dass die Vervielfältigung, die eine unabdingbare Voraussetzung hierfür ist, keine eigenständige wirtschaftliche Bedeutung17 besäße. Ebenso ist der alleinige (!) Zweck nicht die Übertragung zwischen Dritten, sondern diese erfolgt, um eine inhaltliche Veränderung bzw. Auswertung vornehmen zu können.
4.2.3.
Vor- und Nachteile ^
4.3.
Webservices ^
Dies ist der typische Fall von Open Government Data, da die Alternative, Download der jeweils «aktuellen» Gesamtdatenbank, u.U. sehr viel mehr Datenverkehr erfordert und immer zu - mehr oder weniger - veralteten Daten führt. Allerdings bedeutet dies auch, permanent eine entsprechend leistungsfähige und einsatzbereite Infrastruktur vorzuhalten, unabhängig von der konkreten Nutzung20. Es existieren 10 Prinzipien von OGD21, welche auch sehr konkrete technische Auswirkungen besitzen können.
4.3.1.
Technische Umsetzung ^
Webservices sind von der Idee her nichts Neues: Aufrufe von auf anderen Rechnern befindlichen Prozeduren bzw. gelagerten Daten existierten schon vorher, z.B. CORBA, COM oder Datenbankzugriff über Sockets. Die Besonderheit von Webservices liegt einerseits in der Konzeption, jeder Aufruf sollte nach Möglichkeit eigenständig und sehr einfach sein (vergleiche auch Serviceorientierte Architektur), wie der Umsetzung. Letztere erfolgt nicht über neue oder komplexe Protokolle sondern es werden «Webseiten» abgerufen (à z.B. keine Probleme mit Firewalls), die in einem einfachen maschinenlesbaren Format strukturiert sind (à leichte Programmierung und schnelles Parsen). Typischerweise wird XML verwendet (hier ist die Verarbeitungsgeschwindigkeit potentiell ein Problem), doch auch JSON (JavaScript Object Notation) findet häufig Einsatz.
4.3.2.
Rechtliche Beurteilung ^
4.3.3.
Vor- und Nachteile ^
4.4.
Gesetzbücher aus dem RIS ^
Um die Erstellung individueller Gesetzbücher zu ermöglichen wurde eine Anwendung basierend auf einem Proxy implementiert (siehe Abbildung 1 für die Benutzerschnittstelle, sowie Abbildung 2 für ein Beispiels-Ergebnis). Dies erfolgte noch vor der Verfügbarkeit der OGD-Schnittstelle. Hierbei konnten zwar beliebige Paragraphen und Entscheidungen aufgenommen werden (Zugriff durch Injektion eines kleinen Scripts, welches die Dokumentennummer ausliest), doch besaß diese Lösung mehrere Nachteile:
- Das Gesetzbuch wurde derart zusammengestellt, dass die entsprechenden Webseiten abgerufen, zu einer einzigen langen HTML-Webseite zusammengefasst, und diese anschließend nach PDF konvertiert wurde. Daraus ergab sich ein suboptimales Erscheinungsbild, das stark von der Webseitendarstellung abhängt und nur beschränkt umformatiert werden konnte.
- Da das System auf der Dokumentennummer basiert, konnten nur einzelne Paragraphen aber keine ganzen Gesetze integriert werden. Dies hätte jedoch durch eine Erweiterung der Umsetzung realisiert werden können. Problematisch ist eine solche Sonderbehandlung jedoch jedenfalls.
- Die Konvertierung von HTML nach PDF ist sehr ressourcenaufwändig und benötigte viel Zeit. Dies insb. deshalb, da HTML zwar genau definiert ist, aber sich nur äußerst wenige Webseiten exakt an diesen Standard halten. Die Software ist daher gezwungen, auch extrem fehlerhaftes HTML korrekt zu interpretieren (so wie es auch Browser tun). Dass dies bei der RIS Webseite nicht nötig ist reduzierte leider nicht die Komplexität der eingesetzten Bibliotheken.

4.4.1.
Umsetzung der neuen Version ^
Die Umsetzung erfolgte in Java unter Einbeziehung mehrerer Bibliotheken durch Josef Schaitl in seiner Masterarbeit23 und ist unter http://opencodex.fim.uni-linz.ac.at/ erreichbar. Die konkrete Formatierung erfolgt in Form einer Umwandlung der Webservice-Ergebnisse (XML-Format) nach LaTeX, welches anschließend nach PDF konvertiert wird (wobei natürlich auch andere Formate möglich wären). Als problematisch stellten sich bei der Umsetzung heraus:
- Die Geschwindigkeit des Datenabrufs ist gering (siehe oben). Darum wurde ein Caching-System eingeführt, in dem heruntergeladene Dokumente gespeichert werden. Dies stellt beim RIS kein technisches Problem dar, da Dokumente unveränderlich sind (Novellierung des Paragraph à Neues Dokument mit neuer Dokumentennummer). Potentiell könnte diese Zwischenspeicherung jedoch rechtliche Schwierigkeiten bereiten. Da aber jede Ausgabe direkt auf eine Benutzeranforderung zurückgeht, ist dies legal. Fraglich könnte noch der Datenbankschutz sein, falls das RIS als geschützte Datenbank (§ 76c ff. UrhG) nach dem Urheberrecht anzusehen wäre, denn es entsteht kontinuierlich eine fast vollständige Kopie des RIS. Allerdings steht dies der normalen Verwertung der Datenbank nicht entgegen24 und beeinträchtigt die berechtigten Interessen des Herstellers auch nicht unzumutbar (ganz im Gegenteil: kostenlos, Bandbreitenersparnis etc.). Darüber hinaus wurde der Abruf parallelisiert, sodass mehrere Dokumente überlappend abgerufen werden können25.
- Lediglich das Bundesrecht ist derzeit über die OGD-Schnittstelle abfrag- und zugreifbar. Eine Kombination mit der vorhergehenden Applikation ist jedoch nicht möglich, sodass derzeit weder Landesrecht noch Judikatur enthalten sind. Eine Einbindung derselben in das Programm wäre jedoch vergleichsweise trivial, da lediglich eine entsprechende Suchmaske eingebaut werden müsste: Es handelt sich um gleichartige Dokumente mit anderem Inhalt (wahrscheinlich wären zusätzlich Anpassungen der Formatierungsanweisungen erforderlich).
- Das zurückgegebene Format der Nutzdaten ist XML, welches selbst in XML (der Webservice-Antwort) eingebettet ist, wobei aber auch character entities und UTF-8 Sonderzeichen eingesetzt werden. Diese müssen zuerst umgewandelt werden, bevor der Text mittels LaTeX weiterverarbeitet werden kann. Der Grund für diese Kodierung ist nicht bekannt, da der Text selbst, genau wie die Webservice-Antwort, in UTF-8 Kodierung übermittelt wird und damit fast alle character entities überflüssig wären. Allerdings wird in der OGD-Spezifikation erklärt, dass das «Element ‹Dokumenteninhalt› [] die formatierten Nutzdaten [enthält]» (Hervorhebung durch Verf.). Mit anderen Worten, es werden keine strukturierten Daten übermittelt, sondern solche in einer bestimmten Vorformatierung. Dies ist nachteilig, aber wohl in der langen Historie des RIS zu begründen.
- Manche Gesetze enthalten eingebettete weitere Elemente, typischerweise Bilder (z.B. die Straßenverkehrsordnung: Schilder). Diese sind als Binärdateien direkt in das Ergebnisdokument eingebettet. Damit wird ein zusätzlicher Abruf erspart, allerdings die Datenmenge auch stark vergrößert. Die Verarbeitung dieser Elemente stellt potentiell Probleme dar, je nach Datentyp. Möglich sind laut Spezifikation XML, PDF, sowie GIF/JPG/TIFF/PNG26. Bilder werden einfach in das Ergebnisdokument eingebettet, ebenso wie PDF, doch bei den Dokumentenformaten (z.B. DOC) ist eine standardisierte Behandlung nicht möglich, daher wird in der Ausgabe eine Warnung eingefügt. XML-Dateien werden im Quelltext dargestellt – was zwar eine Einbindung erlaubt, aber in vielen Fällen wohl nicht das eigentlich gewünschte Ergebnis darstellen wird. Praktisch wurden bei Tests (nur Bundesrecht!) bisher ausschließlich eingebettete Bilder, aber keine sonstigen Formate, angetroffen.
4.4.2.
Benutzerschnittstelle und Ergebnisdokument ^
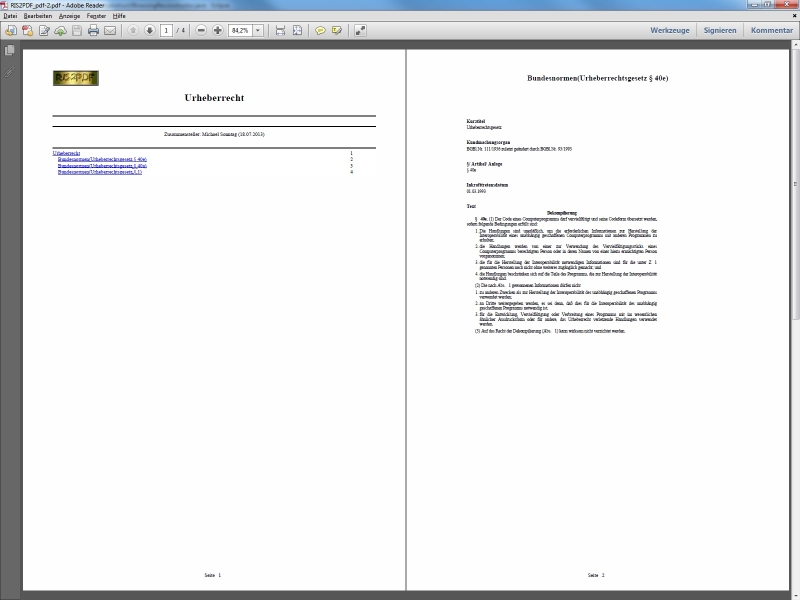
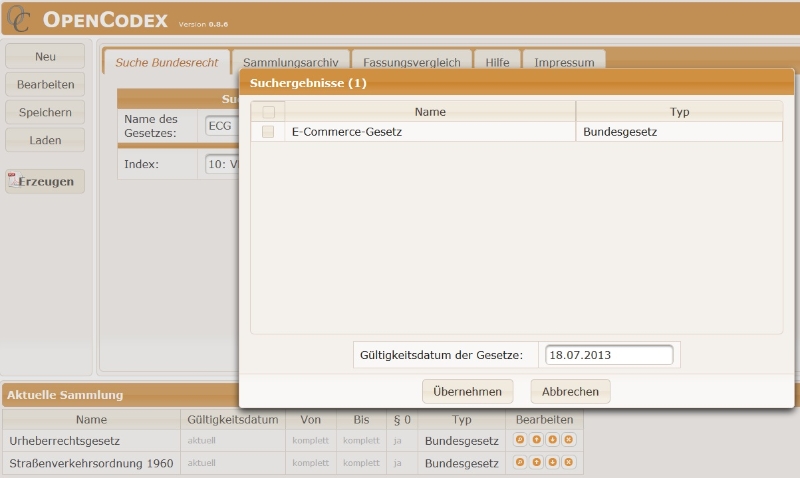
Als Beispiel wird hier eine Kombination mehrerer Paragraphen/Gesetze verwendet. In Abbildung 3 sieht man die (derzeitige und noch in Entwicklung befindliche) Benutzerschnittstelle, wobei bereits einige Elemente ausgewählt wurden (siehe unten «Aktuelle Sammlung») sowie das Suchergebnis (Suche nach «ECG» im Index des Bundesrechts) für weitere hinzuzufügende Elemente. In Abbildung 4 wird ein Ergebnisdokument dargestellt (normale Inhaltseite).

4.4.3.
Erweiterungsmöglichkeiten ^
- Wie schon erwähnt, könnte eine Möglichkeit eingebaut werden, Sammlungen zu teilen. Dies könnte durch eine einfache Schaltfläche erfolgen, welche die Konfiguration in einem öffentlichen Bereich speichert. Dieser könnte als Liste dargestellt bzw. durchsuchbar sein. Da dies auch ohne Benutzerregistrierung möglich ist, wäre jedoch eine gewisse Qualitätskontrolle erforderlich: Redaktionell oder über Bewertungen von Benutzern oder Statistiken über die Häufigkeit des Zugriffs darauf. Auch eine Möglichkeit zur Entfernung von schlechten/inaktuellen Sammlungen müsste eingebaut werden. Mit anderen Worten: Dies stellt nur geringe technische Probleme aber einen deutlich höheren Aufwand für Organisation und Implementation einer Benutzerschnittstelle dar.
- Aktualisierung einer Sammlung: Wird eine «alte» Sammlung geladen, so könnte eine Abfrage erfolgen, ob diese noch dem aktuellen Stand entspricht bzw. gegebenenfalls aktualisiert werden. Hierzu wäre es erforderlich, zu einer Dokumentennummer die aktuellste Version zu bestimmen.
- Um die Benutzbarkeit zu verbessern könnten interne Referenzen auf andere Paragraphen (ev. auch Absätze; schwieriger da meist keine vollständige Referenz) als klickbare Querverweise integriert werden. Dies erfordert jedoch das Parsen des Textes, da derartige Referenzen im Gesetzestext lediglich als normaler Text enthalten sind und keine Metainformationen (z.B. Dokumentennummer des Ziels oder die offizielle Abkürzung des betreffenden Gesetzes) enthalten.
- Eine größere Erweiterung wäre die Möglichkeit von Gegenüberstellungen: Die Differenz zwischen einem Gesetz zu zwei unterschiedlichen Zeitpunkten. Basierend auf der Dokumentennummer kann erkannt werden, ob es sich um den gleichen Inhalt handelt. Schwieriger ist jedoch das Einfügen bzw. Aufheben von Paragraphen/Artikeln. Innerhalb der Paragraphen, d.h. für den Text an sich, könnten klassische Tools zur Anzeige von Textdifferenzen eingesetzt werden.
- Benachrichtigungen über Aktualisierungen für ein individuelles Gesetzbuch könnten eingerichtet werden. Dies wäre technisch einfach zu realisieren, bedingte jedoch eine große konzeptionelle Umstellung in der Benutzeroberfläche. Derzeit ist die Nutzung anonym möglich. Sollten individuelle Benachrichtigungen erfolgen, müsste eine Benutzerregistrierung eingeführt werden – mit allem was daraus folgt (Passwort-Rücksetzung, Auskunftsrechte etc.). Alternativ könnte für jedes öffentliche (Anderen zur Verfügung gestellte) Gesetzbuch z.B. ein RSS-Feed eingerichtet werden, in dem Aktualisierungen dieser Sammlung mitgeteilt werden.
5.
Zusammenfassung ^
Michael Sonntag, Institut für Informationsverarbeitung und Mikroprozessortechnik (FIM), Johannes Kepler Universität Linz, Österreich.
Josef Schaitl, Institut für Informationsverarbeitung und Mikroprozessortechnik (FIM), Johannes Kepler Universität Linz, Österreich.
- 1 http://www.data.gv.at/anwendungen/risapp/ (9. Januar 2013)
- 2 https://findok.bmf.gv.at/findok/ (9. Januar 2013) Diese erlaubt es z.B. auch, Links auf mehrere Dokumente gleichzeitig zu erstellen. Allerdings führt dies lediglich zur Darstellung in Form einer Liste, analog einem Suchergebnis.
- 3 FN https://findok.bmf.gv.at/hilfe/vertriebsinfo.htm#10_3_kommerzielle%20Nutzung (9. Januar 2013): €14.000 pro Jahr (Wert für 2010, also inzwischen ev. höher).
- 4 http://www.ris.bka.gv.at/UI/Info.aspx (9. Januar 2013)
- 5 http://www.data.gv.at/hintergrund-infos/open-data-prinzipien/ (9. Januar 2013)
- 6 RIS OGDService Handbuch (Stand 30. Oktober 2012) http://data.bka.gv.at/RIS/Documents/RIS_OGD_Dokumentation.pdf (9. Januar 2013)
- 7 http://www.data.gv.at/datensatz/?id=31430a9f-c8ba-4654-ab68-c9c3dff0361b (9. Januar 2013)
- 8 Im Rahmen eines anderen Projektes: E-Mail Antwort von Dr. Helga Stöger (12. Juli 2006).
- 9 Dies wird dadurch erhärtet, dass deren schriftliche Einverständniserklärung für den Bezug ihrer Daten aus dem RIS als Gesamtextrakt erforderlich ist: http://www.ris.bka.gv.at/UI/Info.aspx (9. Januar 2013).
- 10 Beispielsweise durch SOP (Same Origin Policy): Zugriff ist nur auf Daten möglich, die aus derselben Quelle (dem gleichen Server: Protokoll, Host und Port müssen übereinstimmen) stammen. https://developer.mozilla.org/en-US/docs/JavaScript/Same_origin_policy_for_JavaScript (9. Januar 2013).
- 11 BGH 29. April 2010, I ZR 69/08, BGH 19. Oktober 2011, I ZR 140/10
- 12 Siehe Leitsatz 2 sowie den Volltext (http://www.suchmaschinen-und-recht.de/urteile/Oberlandesgericht-Jena-20080227.html) zum Urteil im selben Fall in niedrigerer Instanz: OLG Jena 27. Februar 2008, 2 U 319/07. Vergleiche auch das zweite Urteil zur Bildersuche, wonach die Einwilligung selbst dann gilt, wenn das Bild von der Webseite eines Nicht-Berechtigten stammt: BGH 19. Oktober 2011, I ZR 140/10. Dies kann durch (auf der eigenen Webseite befindliche!) robots.txt Dateien niemals verhindert werden.
- 13 Sonntag, Zur Urheberrechtlichen Zulässigkeit von Screen Scraping. In: Schweighofer/Kummer (Eds.): Europäische Projektkultur als Beitrag zur Rationalisierung des Rechts. Wien: OCG 2011, 141–148
- 14 BGH 29. April 2010, I ZR 39/08 «Session-ID»
- 15 Ein Beispiel könnte die Auswertung der Anfrage-Header sein, in denen normalerweise Browser-Typ und -Version mitgesendet werden. Automatische Abfragen müssten explizit vorgeben (technisch trivial), ein Browser zu sein, was hiermit schon ausreichen würde. Eine solche Sicherungsmaßnahme ist allerdings vom Client erst bei tatsächlichem Versuch erkennbar (Fehlermeldung).
- 16 Hier wird daher die Fehlertoleranz des Browsers ausgenützt, der die Seite interpretiert. Anschließend wird nur mehr das Ergebnis dieses Vorgangs, z.B. über das DOM-Modell, extrahiert.
- 17 Siehe dazu Vogel in Kucsko, urheber.recht § 41a 4.4
- 18 Die Bearbeitung selbst ist erlaubt, aber das veränderte Werk wird hier wiederum der Öffentlichkeit zugänglich gemacht. Dass diese aus jeweils nur einem einzigen Benutzer besteht, spielt hier keine Rolle, da die gleichen (oder zumindest ähnliche) Änderungen für jeden Besucher erfolgen und dadurch eine sukzessive Öffentlichkeit gegeben ist – ähnlich den Exemplaren eines übersetzten Buches.
- 19 Die konkrete Implementierung (ein Vorgänger der hier vorgestellten Software), fügte der Einfachheit halber jedoch ein minimales Script zur Extraktion der Dokumentennummer ein.
- 20 Sofern nicht Cloud-Services o.Ä. eingesetzt werden bedeutet dies, dass eine Auslegung auf die maximale Nutzung erfolgen muss, will man nicht eine Reduktion der Qualität (z.B. verlängerte Antwortzeiten) akzeptieren.
- 21 Abschnitt 2 Open Government Data Prinzipien. In: Eibl et al, Rahmenbedingungen für Open Government Data Plattformen (1.1.0) http://reference.e-government.gv.at/uploads/media/OGD-1-1-0_20120730.pdf (29. Januar 2013)
- 22 Ein Beispiel hierfür ist WSDL (Web Services Description Language), das insb. Schnittstelle und Protokoll spezifizieren kann.
- 23 Derzeit in Fertigstellung befindlich: Schaitl, OpenCodex – Erzeugung individualisierter Gesetzbücher aus den Daten des RIS. Master Thesis an der JKU.
- 24 Es werden weiterhin nur Gesetzbücher auf individuelle Anfrage erstellt. Anders wäre dies ev., wenn der Cache auch so als Ganzes zugänglich gemacht würde.
- 25 Denn das Problem ist nicht die Übermittlungsgeschwindigkeit sondern die Verzögerung, bis mit der Übermittlung begonnen wird (Latenz).
- 26 Nach Auskunft des RIS zusätzlich auch RTF, DOC, DOCX und ODT.





