1.
Introduction ^
2.
Foundations ^
3.
Syntax – Semantic Transitions through Visualization ^

Figure 1: Transitioning from syntax to semantics
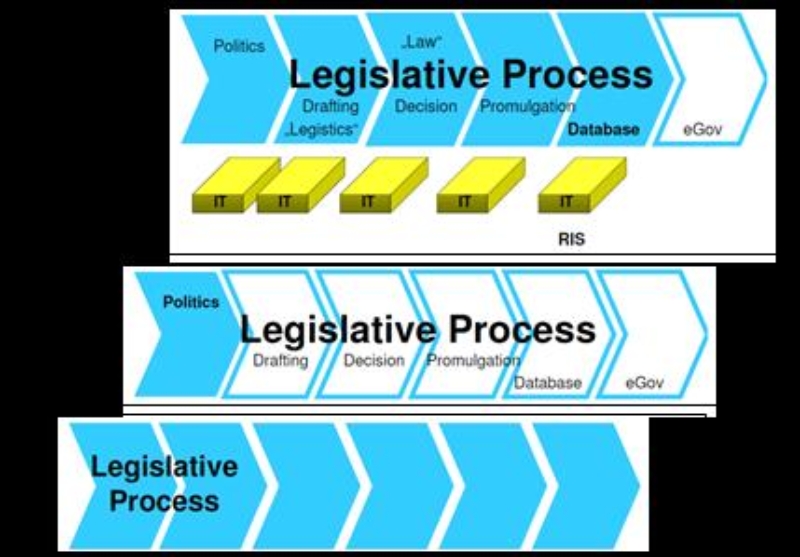
Figure 2: Legislative Workflow, Source: [Lachmayer, 2008]

Figure 3: Transitioning from semantics to syntax
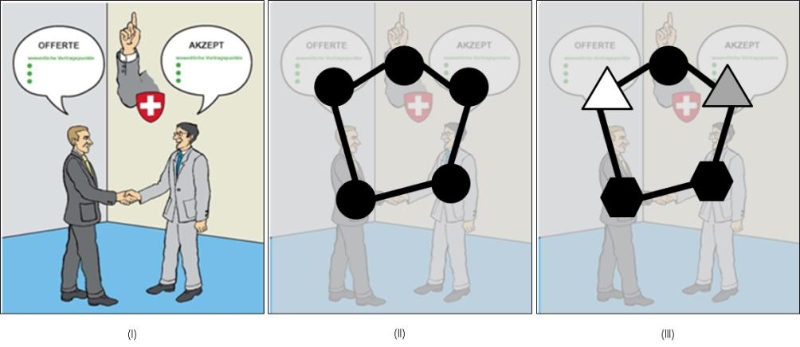
Figure 4: Visualizing analysis for transitioning from semantics to syntax, Sources: [Brunschwig, 2011], [Fill, 2013]
4.
Implications and Further Research Directions ^
5.
References ^
Bertin, J., Semiology of Graphics: Diagrams, Networks, Maps. University of Wisconsin Press, 1983.
Brunschwig, C. R., Multisensory Law and Legal Informatics – A Comparison of How these Legal Disciplines Relate to Visual Law. in: Anton Geist, Colette Brunschwig, Friedrich Lachmayer, F. & Günther Schefbeck (Eds.), Strukturierung der Juristischen Semantik – Structuring Legal Semantics, Festschrift für Erich Schweighofer, Editions Weblaw, Bern, pp. 573-668, 2011.
Fill, Hans-Georg, Presentation on: Polysyntactic Meta Modeling: Historical Roots in the Work of Raimundus Lullus, Accompanying text in: Erich Schweighofer, Franz Kummer, Walter Hötzendorfer (Eds.); Abstraktion und Applikation – Tagungsband des 16. Internationalen Rechtsinformatik Symposiums, books@ocg.at, Band 292, Wien, 2013, pp. 439-444.
Fill, Hans-Georg, Visualisation for Semantic Information Systems, Gabler, 2009.
Joye, D.E.: Euclid’s Elements, Clark University, URL: http://aleph0.clarku.edu/~djoyce/java/elements/toc.html (access 15-03-2013), 1997.
Kienreich, Wolfgang/Lex, Elisabeth/Rapp, Stefan, Maschinelle Lernverfahren für die automatische Klassifikation von juristischen Dokumenten, in: Erich Schweighofer, Franz Kummer, Walter Hötzendorfer (Eds.); Transformation juristischer Sprachen – Tagungsband des 15. Internationalen Rechtsinformatik Symposiums, books@ocg.at, Band 288, Wien, 2012, pp. 83-87.
Lachmayer, Friedrich, Austrian Legal Information System RIS 02, Legislative Workflow, URL: http://www.legalvisualization.com/download.php?hash=e69efbcdd1f3ec9c3df40ce8eec981ef?fname=Austrian_Legal_Information_System_RIS_02%2C_Legislative_Workflow.pdf (accessed 10-03-2013), 2008.
Schweighofer, Erich/Lachmayer, Friedrich, Ideas, Visualisations and Ontologies, in: P. Visser, R.G.F. Winkels, Proceedings First International Workshop on Legal Ontologies, LEGONT’97, Juli 1997, Melbourne, Victoria, Australia, 7-13.
Messer, B., Zur Interpretation formaler Geschäftsprozess- und Workflow-Modelle, in: Jörg Becker, Wolfgang König, Reinhard Schütte, Oliver Wendt and Stephan Zelewski, Wirtschaftsinformatik und Wissenschaftstheorie – Bestandaufnahme und Perspektiven, Gabler, 1999, pp. 95-123.
Moody, D. L., The «Physics» of Notations: Toward a Scientific Basis for Constructing Visual Notations in Software Engineering, IEEE Transactions on Software Engineering 35(6), 2009, pp. 765 ff.
Nöth, Winfried, Handbuch der Semiotik, Metzler, 2000.
Stöger-Frank, Angela, Aus drei mach eins: Eine Suchmaske für drei Datenbanken (FINDOK, LEXISNEXIS, LINDE) zur Reduktion des Suchaufwandes, in: Erich Schweighofer, Franz Kummer, Walter Hötzendorfer (Eds.); Transformation juristischer Sprachen – Tagungsband des 15. Internationalen Rechtsinformatik Symposiums, books@ocg.at, Band 288, Wien, 2012, pp. 53-55.
Tarski, A., Der Wahrheitsbegriff in den formalisierten Sprachen, Studia Philosophica I, 1936, pp. 261-405.
Ware, Colin, Information Visualization – Perception for design, Morgan Kaufman, 2000.
Zemanek, Heinz, Das geistige Umfeld der Informationstechnik, Springer-Verlag, Berlin, Heidelberg, 1992.
Hans-Georg Fill, Assistant professor, Research Group Knowledge Engineering, University of Vienna.





