1.
Introduction ^
Until then, many technical, legal and societal obstacles have to be solved for achieving this idealist goal. Whereas technical solutions are developing and emerging, legal and societal constraints seem to grow, especially a fear of technology that cannot be easily controlled. As Winston Churchill said: «No one pretends that democracy is perfect or all-wise. Indeed it has been said that democracy is the worst form of Government except for all those other forms that have been tried from time to time […].»4 Thus, risks of failures of democratic procedures are common, a persistent threat that can be solved only by a risk analysis ex ante and ex post.5 Democracy must face risks of manipulation of information exchange, deliberation, and vote. It is also not guaranteed that this form of crowd intelligence produces wise results but it is a good chance that representatives are elected taking care of the interest of the people. Very formalistic approaches of detailed legislation and the requirement of a near zero error rate seem to lead to a dead end of no valid elections at all.6 It is evident that informational tools of democracy have to comply with constitutional law. Present strong reservations strongly restrict the use of such digital elements of democracy. This has to be accepted but communication work has to be done to overcome this obstacle to digital democracy.
E-democracy is the use of ICT in processes of politics and governance (e.g. policy making, decision making, governmental services, administrative powers etc.).7 E-voting (or electronic voting) means voting by electronic means. Besides working IT solutions, e-voting is struggling getting legal and societal acceptance. The image of a – at least partly – law-less internet – still hinders efforts in this direction; some failures are strong arguments for the many opponents to e-democracy. Its paper variant, letter voting, gets much higher acceptance but faces similar difficulties in fulfilling constitutional requirements on voting.8 E-Participation is here understood as ICT support of participatory processes in politics and governance, but much more closely related to e-government. A new quality level of two-way interaction is created between citizens and government. E-participation has the advantage of flexibility. Its main element, the electronic communication platform, is already highly accepted in society considering the strong use of social networks. For politicians, the internet, in particular the social networks, has got a similar importance as traditional communications. It is worth noticing that the strongest significance of this new form of e-democracy without particular tools could be seen in recent democratic movements against authoritarian regimes.9
Besides giving an overview of results of the E-Partizipation project, the question of analysis of textual feedback of e-participation platforms is addressed. Taking into account research results of legal data analysis that works on similar text corpora, in particular digital court files, an outline of such a system is presented.
2.
E-Partizipation project ^
The E-Partizipation project within the KIRAS Security Research programme of the Austrian Research Promotion Agency (FFG) has developed an E-Participation Platform Demonstrator that can strengthen direct democracy offering different participation scenarios. The consortium consists of AIT Austrian Institute of Technology GmbH, Digital Safety & Security Department, as project leader, and the following project or co-operation partners: Bundeministerium für Inneres (Federal Ministry of Interior), Donau-Universität Krems, Österreichische Staatsdruckerei GmbH, rubicon IT GmbH and Universität Wien, Arbeitsgruppe Rechtsinformatik. The project started in October 2014 and will end in October 2016. For more information, we refer to the project website.10
E-participation requires the use of highest security standards for the protection of privacy as sensible data about political opinions and voting behaviour are collected. Thus, the principle of Privacy by Desing (PbD) is getting more and more important. This principle implies addressing privacy and data protection during the entire technology lifecycle.11 In a software development process, privacy and data protection have to be part of the whole process. The new General Data Protection Regulation (GDPR) of the EU enhances this principles, in particular data minimisation.12
A further important aspect was e-inclusion. Conceptualisation of the platform and the inherent design principles («Design for All») aiming at enhancing the inclusion of people with disabilities such as visual, auditory, physical, cognitive, learning and neurological disabilities as well as non-native speakers and elderly people were examined and identified as a central aim for official e-participation projects.13
As result of the participation process, e-participation platforms produce statistical data but also textual (and visual) statements. An opinion, a vote, but also with reasons: a statement that overcomes the rigid limitations of present voting procedures, a more or less binary choice. This new complexity is an unsolved challenge of assessment of the will of the people. Thousands of solutions may be submitted, with variable expressions of support or amendments. Whereas many tools are available for statistical analysis, no proper tools exist for text analysis. Within the project tests, the text corpus was sufficiently small to allow a manual assessment of the textual feedback. However, if several thousands, ten-thousands or even hundred thousands are participating, often with more than one statement, manual analysis without ICT supports seems to be a nearly impossible task. Here, ICT can provide a tool strongly supporting an objective assessment process. The research results on analysis of similar text corpora in law are taken as a start. This paper summarizes results of the workshop and related discussions with the Hebrew University Jerusalem and Bar Ilan University, Ramat Gan.
3.
Challenge of textual feedback of e-participation platforms ^
4.
Legal data science: 8 views, 4 methods and 4 synthesis of the legal system ^
The goal of legal data science is to complement the existing methodology of lawyering with computer-based methods. Paraphrasing the words of Layman Allen in 195715, legal data science provides razor sharp tools for the analysis of the textual element of the legal system. «The fight for justice and law» – in the sense of Rudolf von Jhering16 – goes on, but now including legal data science. For a long time, work on legal knowledge has been only in the focus of legal theory and information science. Only since the late 1950’s – with the start of research on legal information retrieval – appropriate progress can be noted (term retrieval, text retrieval, metadata, citations, search technologies, user interface, telecommunications, etc.).
The next step – metadata – is already here but in many different forms. Classification and summarization of important content or extraction of relevant information is a standard of legal information science (e.g. high-level West’s Key Number System24 or the formidable CELEX metadata system25). Contrary to these documentation systems, metadata in legal data science is generated mostly automatically. Given some input with proper heuristics, use of learning techniques and then matching of the text corpus with these pre-defined structures, a fine set of metadata can be achieved. Considering the strong dynamics of legal systems – like textual feedback of e-participation platforms – a main advantage is evident: after sufficient training and regular updating, the analysis tool can be used for a longer time, making the analysis of new documents or new perspectives much easier than the usual retrieval and reading. Three main types of metadata can be distinguished: general metadata, citations and user feedback. General metadata concerns document dates (creation, validity, etc.), document type and annotations with thesauri or classifications, also considering multilingual jurisdictions. Citations describe the relations between documents. It has always been a key topic of legal documentation and is and will remain indispensable. Formally, it is documented if a document cites others (out-bound [cited] sources) and if it is quoted by others (in-bound [cited] sources). It is important to specify citations, e.g. referring also to the structuring elements of a document, e.g. articles, sections, paragraphs, lists, etc. The main types of citations are: basis of the act, cited acts in the document, citations in the operative part of the judgment, document amending other documents, document is amended by other acts, etc.26.The similar automatic generation of temporal relationships describes the different states of a document, e.g. creation, validity, applicability etc. Data-friendly generation of user behaviour gives strong insights of their assessment. The user’s perspective takes into account the opinions of legal professions, business and civil society about the document collection. Sufficient data protection remains a prerequisite of such metadata, in particular anonymization of user data. Metadata is not restricted to providing additional information only. It also allows the semi-automatic generation of summaries of documents, supporting a much easier and more efficient analysis of documents. The user needs are taken into account in sophisticated ranking algorithms: document vs. requirements, document in the corpus, document in the citations network, document in the timeline etc.
The last step is the most difficult one and requires strong tools of linguistic analysis. The text has to be segmented in facts, logical rules and arguments. Presently, tools are developed and tested in small environments with promising results. Here, the pre-defined models of legal knowledge are much more sophisticated requiring intensive use of natural language processing. The existing prototypes are explorative with different complexity. The logical representation is based on the first order logic, complemented by a representation of temporal layers27 and the personal scope28. The decisive factor is the rapid and efficient execution of an at least five-digit number of rules (i.e. more than 10’000 rules).29 The legal ontology brings the automation option and a much more powerful systemisation. Since the 1990's, many legal ontologies have been developed30; now a strong standard exists with LRI Core, LKIF31 and LegalRuleML32. The respective elements of the concepts have to be transposed into a computer-readable structure.33 Facts, e.g. a world ontology, can be taken from projects like Cyc.34 A major advantage of an ontology is the easier representation of relations between facts and legal concepts in a form of pre-subsumption. Legal visualization concerns the use of graphics, images and videos for visual representation of the law.35 Visualisation is especially powerful for representing the essentials, making them memorable, increasing understanding and showing hidden connections. Graphical notations are also a support for the formalization of the law, also in cases where the necessary level of abstraction for formalization is not yet reached. The focus of the argumentation view is twofold: representation of legal arguments but also the structure of each document in its elements and logical structure: factual information, evidence, arguments, conclusions, etc.36. Following the legal theory work on theories on legal argumentation (e.g.37), formalisation of legal arguments stays in the focus since the 1990's. The elements of argumentation are systematized in a logical argumentation structure. Arguments are an essential tool of legal work, because thesis, antithesis and synthesis are relevant in each case due to the dialectical roles of plaintiff, defendant and judge.
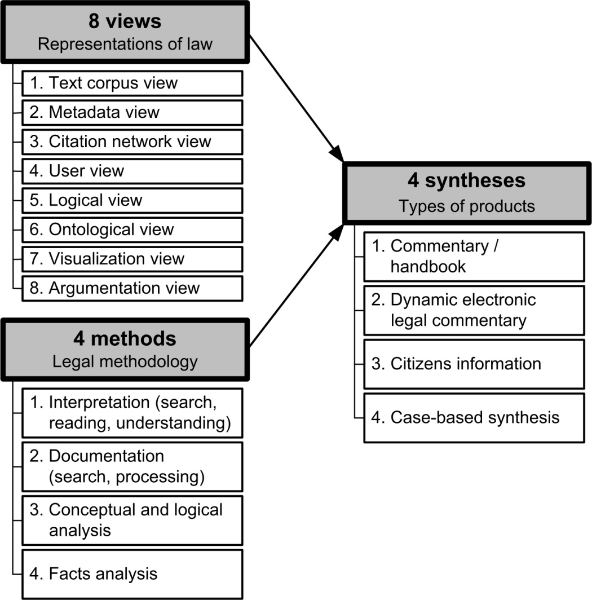
Figure 1: Legal data science38
For providing these views, 4 legal methods are available: legal dogmatics, in particular interpretation, documentation, conceptual and logical analysis and fact analysis. The standard methodology is to locate, read, interpret and understand the «legal stuff», taking into account the legal interpretation and reasoning methods in a dynamic world of concepts. Other elements are also considered, e.g. social context, legal authorities, sophisticated methods of interpretation etc. However, the very high costs can be financed only in exceptional circumstances. Thus, many views are not available at all. Stronger use of AI & law can be the solution to this knowledge acquisition problem. Legal documentation is the first major achievement solving the challenge of up-to-date storage and retrieval of documents. Legal information providers follow the negotiation and adoption of new laws, rendering of new judgements or decisions, new literature etc. They take care of all relevant changes of the particular legal system, index these materials in full-text and, if possible, add metadata and provide powerful search engines. For the conceptual and logical analysis, the fundamental statement of Sowa applies again: the terminology is to be developed and to be brought into a strong logical structure.
The 8 views are more an intermediate result that has to be transformed into a legal product, e.g. syntheses: commentary/handbook, dynamic electronic legal commentary, citizen’s information and case-based synthesis. AI & law methodology allows a representation according to the different needs of the users: Handbook, Dynamic Electronic Legal Commentary (DynELC), citizen information or case-related synthesis. Starting from the text corpus in XML format, legal data science methods drawn from many fields within the broad areas of mathematics, statistics, and information technology: pattern recognition and learning, machine learning, probability models, statistical learning, visualization, data warehousing, etc. AI & law has developed and refined these methods for legal output. It has to be noted that the required accuracy for practical use has very often not been achieved yet. Recent research on network analysis in law can be considered as an important step forward.39
5.
AI & law methods for e-participation platforms ^
Document categorisation, document segmentation, citation analysis40, temporal relations41 and thesaurus generation rely on pattern matching, machine learning and natural language processing33. The representation of documents in XML format has to be refined by use of a standard part-of-speech tagger. A knowledge base with patterns of document types, document segments, citation structures, temporal relations and concepts is matched with the text corpus resulting in a raw analysis of a document. The knowledge base has to be refined and improved using machine learning techniques. Further, the output has to be presented in a formal model (e.g. types of citations with relevance ranking). This semi-automatic approach delivers also relevant feedback from authors and users for improving the knowledge base.42 Model-based visualizations are based on grammars, i.e. strict specifications for composing visualizations based on sets of pre-defined elements and relation (e.g. the PICTMOD of Fill43). Ranking is used as a mechanism for establishing a relationship of relevance for a particular information or analysis. In law, it is used in legal information retrieval, however, with still insufficient success compared to the Google algorithm.44 Ranking gives some guidance concerning the relations of a document vs. requirements, document in the corpus, document in the citations network, document in the timeline etc.
The logical analysis and the argumentation analysis require a rule and an argumentation model. Some support can be achieved if text is transferred into logical rules (e.g. the well-known example of Softlaw/Oracle45 or recently by Islam and Governatori46). Flow-charts (activity diagrams) are also very helpful in practice. Recent work on argumentation analysis can be found in the ICAIL2015 proceedings.47 The logic programming is powerful enough to be a decisive support tool for the implementation of laws. Well-structured flowcharts help in decision-making, esp. when thousands of legal rules must be processed. However, two important elements should be added. Without a model of the layers of time use in a highly dynamic legal world is difficult48; further, a differentiation should be made according to distinct applicability of norms on legal subjects.
6.
Outline of an analysis of textual feedback of e-participation platforms ^
Semantic web: Textual feedback exists mostly in HTML files that have to be transferred to XML allowing adding of metadata with RDF or OWL. The metadata is best described by the 4 views of the legal system.
Document description and summary: A lexical ontology, e.g. a thesaurus, remains critical for a condensed short content description. Multilingual versions like Eurovoc can be very helpful for first handling of documents in a foreign language. Without question, an e-participation organiser must develop his own lexical ontology, taking into account language use in the constituency.
7.
Conclusions and future work ^
E-participation platforms face the same challenges as legal text corpora. Size, diversity, different language use and dynamic development strongly constrain intellectual analysis, in particular in real time. Legal data science looks back to more than 50 years of experience in the analysis of legal text corpora (albeit under different names, in particular legal information retrieval or AI & law). Present analysis consists in creating 8 views using AI & law methodology for producing automatically or semi-automatically analytical maps. The same methodology can be used to speed up textual feedback analysis of e-participation platforms. A first outline is given in this paper, focussing on generating semi-automatically metadata of statements: identification, type, temporal and pragmatic relations, summary and assessment. The metadata is visualised in topical maps according to the needs of the e-participation organiser. In the future, this outline will be further developed and, hopefully, added to the E-Partizipation Platform Demonstrator.
Erich Schweighofer, Professor, University of Vienna, Centre for Computers and Law (DEICL/SIL), Department of European, International and Comparative Law, Schottenbastei 10-16/2/5, 1010 Vienna, AT.
Erich.Schweighofer@univie.ac.at; http://rechtsinformatik.univie.ac.at / https://epartizipation.info; https://deicl.univie.ac.at.
Acknowledgements: The E-Partizipation project is funded by the Austrian security research programme KIRAS of the Federal Ministry for Transport, Innovation and Technology (bmvit). It has developed an E-Participation Platform Demonstrator that can strengthen direct democracy offering different participation scenarios. The support of Vinzenz Heußler and Janos Böszörmenyi is gratefully appreciated.49
- 1 Ahti Saarenpää, The Digital Lawyer. What skills are required of the lawyer in the network society? In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer (eds.), Kooperation / Co-operation, Tagungsband des 18. Internationalen Rechtsinformatik Symposions IRIS 2015. Wien: Österreichische Computer Gesellschaft (OCG), p. 73, 2015.
- 2 Cf. the numerous workshops at the IRIS conferences organised by Alexander Prosser et al. or the CeDEM conferences at the Donau Universität Krems.
- 3 Cf. proceedings of IRIS 2016 on networks: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer/Georg Borges (eds.), Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016. Wien: Österreichische Computer Gesellschaft (OCG), 2016; Erich Schweighofer, Von der Wissensrepräsentation zum Wissensmanagement im e-Government. In: Erich Schweighofer et al. (eds.), IT in Recht und Staat, Aktuelle Fragen der Rechtsinformatik 2002, Verlag Österreich, Wien, p. 85, 2002.
- 4 Speech in the House of Commons, 11 November 1947.
- 5 Cf. Thomas Preiß, Die Bedeutung der Risikoanalyse für den Rechtsschutz bei automatisierten Verwaltungsstrafverfahren, Ph.D. thesis, University of Vienna; Erich Schweighofer/ThomasPreiß, Risikoanalyse im Recht – eine neue juristische Methodik. In: Heinrich C. Mayr/Martin Pinzger (eds.), INFORMATIK 2016, Lecture Notes in Informatics (LNI), Gesellschaft für Informatik, Bonn 2016, in print.
- 6 Cf. judgement of the Austrian Constitutional Court WI6/2016 of 1 July 2016. The decision can be found in the Austrian Legal Information System RIS, http://www.ris.bka.gv.at- This judgement is strongly criticized by Heinz Mayer, Eine klare Fehlentscheidung. In: Falter 34/16, Wien 2016.
- 7 Natalie C. Helbig/J. Ramon Gil-Garcia/Enrico Ferro, Understanding the Complexity of Electronic Government: Implications from the Digital Divide, Proceedings of the Eleventh Americas Conference on Information Systems, Omaha, NE, USA, 2005.
- 8 Cf. a warning of the IT expert Arnim Rupp, IT-Experte warnt vor Betrug bei der Briefwahl, in: Der Spiegel Online, 28 July 2013, http://www.spiegel.de/spiegel/vorab/it-experte-warnt-vor-betrug-bei-der-briefwahl-a-913466.html (all websites lastly accessed: 19 September 2016).
- 9 The best example is the Arab Spring from 2010 to 2012, in particular in Egypt, Tunesia, Libya, Yemen, Syria and Bahrein. The Wikipedia article gives an overview: https://en.wikipedia.org/wiki/Arab_Spring.
- 10 Website E-Partizipation https://www.epartizipation.info/.
- 11 European Union Agency for Network and Information Security enisa, Privacy and Data Protection by Design – from policy to engineering. 2014, https://www.enisa.europa.eu/activities/identity-and-trust/library/deliverables/privacy-and-data-protection-by-design/at_download/fullReport; Oliver Terbu/Walter Hötzendorfer/Maria Leitner/Arndt Bonitz/Stefan Vogl/Sebastian Zehetbauer, Privacy and Security by Design im agilen Softwareentwicklungsprozess. In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer/Georg Borges (eds.), Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016. Wien: Österreichische Computer Gesellschaft (OCG), p. 457, 2016.
- 12 Regulation (EU) 2016/679 of the European Parliament and of the Coucil of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation), OJ L 119, 4 May 2016, p. 1, Articles 5 and 25 GDPR.
- 13 Vinzenz Heussler/Judith Schossböck/Janos Böszörmenyi, Aspekte der Inklusion aus Sicht der E-Partizipation. In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer/Georg Borges (eds.), Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016. Wien: Österreichische Computer Gesellschaft (OCG), p. 213, 2016.
- 14 Cf. the ICAIL workshops on discovery of electronically stored information (DESI), on using machine learning and other advanced techniques to address legal problems in e-discovery and information governance, the latest in 2015, http://www.umiacs.umd.edu/~oard/desi6/.
- 15 Layman Allen, Symbolic Logic: A Razor-Edged Tool for Drafting and Interpreting Legal Documents. In: The Yale Law Journal 66, p. 833, 1957.
- 16 Rudolf von Jhering, Der Kampf ums Recht, Vortrag (The fight for law), Wien, 1872. Schutterwald/Baden 1997, 1872.
- 17 Erich Schweighofer, Rechtsdatalystik – Versuch einer Teiltheorie der Rechtsinformatik. In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer (eds.), Kooperation / Co-operation, Tagungsband des 18. Internationalen Rechtsinformatik Symposions IRIS 2015. Wien: Österreichische Computer Gesellschaft (OCG), p. 61, 2015.
- 18 Qiang Lu/Jack G. Conrad, Next generation legal search - it’s already there. In: Cornell Legal Information Institute. In: VoxPopuLII, https://blog.law.cornell.edu/voxpop/2013/03/28/next-generation-legal-search-its-already-here/, 2013.
- 19 John F. Sowa, Knowledge representation: logical, philosophical, and computational foundations. Course Technology, Boston, MA, 2000.
- 20 Herbert Fiedler, Modell und Modellbildung als Themen der juristischen Methodenlehre (Model and modeling as subjects of legal methodology). In: Proceedings of the International Legal Informatics Conference IRIS 2006, OCG Publishers, Vienna, p. 275, 2006.
- 21 John Zeleznikow/Dan Hunter, Building Intelligent Legal Information Systems, Representation and Reasoning in Law, Computer Law Series 13, Kluwer, Deventer, 1994.
- 22 John Yearwood/Andrew Stranieri (eds.), Technologies for Supporting Reasoning Communities and Collaborative Decision Making: Cooperative Approaches, IGI Global Publishers, Hershey, PA 2011.
- 23 Erich Schweighofer, Indexing as an ontological-based support for legal reasoning. In: John Yearwood/Andrew Stranieri (eds.), Technologies for Supporting Reasoning Communities and Collaborative Decision Making: Cooperative Approaches, IGI Global Publishers, Hershey, PA 2011, p. 213, 2011.
- 24 Westlaw, West Key Number System® on WestlawNext®, L-374484.pdf" https://info.legalsolutions.thomsonreuters.com/pdf/wln2/L-374484.pdf.
- 25 Erich Schweighofer, Wissensrepräsentation in Information Retrieval-Systemen am Beispiel des EU-Rechts, Dissertation, Universität Wien 1995, (knowledge representation in information retrieval systems on the example of EU law, PhD thesis, University of Vienna 1995, published in extended version WUV publishers, Vienna 2000.
- 26 Albrecht Berger, The development of references in the legislative documentation, Verlag Dokumentation, Pullach near Munich 1971.
- 27 Johannes Scharf, Wissensrepräsentation und automatisierte Entscheidungsfindung am Beispiel des KOVG (Knowledge representation and automated decision making), PhD thesis, University of Vienna, 2015.
- 28 Idea of Erich Schweighofer, based on relevant thoughts of Ch. Reed, You Talkin’ to Me?. In: Jon Bing, en hyllest, a tribute, p. 154–171, 2014.
- 29 A prime example is the Australian company SoftLaw; this was subsequently acquired by Oracle; the application itself is available as Oracle Business Rules.
- 30 Giovanni Sartor/Pompeu Casanovas/Mariangela Biasiotti/Meritxell Fernández-Barrera (eds.), Approaches to Legal Ontologies: Theories, Domains, Methodologies, Dordrecht/Heidelberg/London/New York, Springer, 2011.
- 31 Rinke Hoekstra/Joost Breuker/Marcello Di Bello/Alexander Boer, The LKIF Core Ontology of Basic Legal Concepts. In: Pompeu Casanovas/Mariangela Biasiotti/Enrico Francesconi/Maria Teresa Sagri (eds.), Proceedings of LOAIT 07, II. Workshop on Legal Ontologies and Artificial Intelligence Techniques, p. 43–64, 2007.
- 32 Website OASIS LegalRuleML, https://www.oasis-open.org/committees/ tc_home.php?wg_abbrev=legalruleml.
- 33 Núria Casellas/Enrico Francesconi/Rinke Hoekstra/Simonetta Montemagni (eds.), Proceedings of LOAIT 2009, 3rd Workshop on Legal Ontologies and Artificial Intelligence Techniques joint with 2nd Workshop on Semantic Processing of Legal Text. Barcelona: IOT Series, 2009; Pompeu Casanovas/Mariangela Biasiotti/Enrico Francesconi/Maria Teresa Sagri (eds.), Proceedings of LOAIT 07, II. Workshop on Legal Ontologies and Artificial Intelligence Techniques, 2007.
- 34 Wikipedia EN, Cyc, https://en.wikipedia.org/wiki/Cyc.
- 35 Colette Brunschwig, Multisensory Law and Legal Informatics – A Comparison of How these Legal Disciplines Relate to Visual Law. In: Anton Geist/Colette R. Brunschwig/Friedrich Lachmayer/Günther Schefbeck (eds.), Strukturierung der Juristischen Semanik – Structuring Legal Semantics, Festschrift für Erich Schweighofer, Editions Weblaw, Bern, p. 573, 2011.
- 36 Kevin D. Ashley, Modeling Legal Argument. Reasoning with Cases and Hypotheticals. Cambridge MA: MIT Press, 1990.
- 37 Robert Alexy, Theory der juristischen Argumentation (Theory of Legal Argumentation). Frankfurt am Main, 1983.
- 38 Source: Vytautas Čyras/Friedrich Lachmayer/Erich Schweighofer, Network of Legal Metalevels. In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer/Georg Borges (eds.), Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016. Wien: Österreichische Computer Gesellschaft (OCG), p. 83, 2016.
- 39 Jörg Landthaler/Bernhard Waltl/Florian Matthes, Unveiling references in legal texts: implicit versus explicit network structures. In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer/Georg Borges (eds.), Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016. Wien: Österreichische Computer Gesellschaft (OCG), p. 71, 2016.
- 40 Erich Schweighofer/Dieter Scheithauer, The Automatic Generation of Hypertext Links in Legal Documents. In Proceedings of Database and Expert Systems Applications, 7th International Conference, DEXA’96, Zurich 1996, Lecture Notes in Computer Science 1134, p. 889, Springer, Berlin.
- 41 Johannes Scharf, Wissensrepräsentation und automatisierte Entscheidungsfindung am Beispiel des KOVG (Knowledge representation and automated decision making). Ph.D thesis, University of Vienna, OCG Publishers, 2015.
- 42 Erich Schweighofer, Indexing as an ontological-based support for legal reasoning. In: John Yearwood/Andrew Stranieri (eds.), Technologies for Supporting Reasoning Communities and Collaborative Decision Making: Cooperative Approaches, IGI Global Publishers, Hershey, PA 2011, p. 213–236, 2011.
- 43 Hans-Georg Fill, Bridging Pictorial and Model-based Creation of Legal Visualizations: The PICTMOD Method. In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer (eds.), Kooperation / Co-operation, Tagungsband des 18. Internationalen Rechtsinformatik Symposions IRIS 2015. Wien: Österreichische Computer Gesellschaft (OCG), p. 443–447, 2015.
- 44 Anton Geist, Relevanzsortierung bei Rechtsdatenbanken (relevance ranking in legal databases), Ph.D thesis (to be submitted), University of Vienna, 2016.
- 45 Surendra Dayal/Michael Harmer/Peter Johnson/David Mead, Beyond Knowledge Representation: Commercial Uses for Legal Knowledge Bases. In: Proceedings of the Fourth International Conference on Artificial Intelligence and Law ICAIL1993, p. 167–174, ACM, New York.
- 46 Mohammad Badiul Islam/Guido Governatori, RuleOMS: A Rule-Based Online Management System. In: Proceedings of the Fifteenth International Conference on Artificial Intelligence and Law ICAIL 2015, ACM, New York, p. 187, 2015.
- 47 Joonsuk Park/Cheryl Blake/Claire Cardie, Toward Machine-assisted Participation in eRulemaking: An Argumentation Model of Evaluability. In: Proceedings of the Fifteenth International Conference on Artificial Intelligence and Law, ICAIL2015, ACM, New York, p. 206, 2015.
- 48 Johannes Scharf, rOWLer – A hybrid rule engine for legal reasoning. In: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer (eds.), Kooperation / Co-operation, Tagungsband des 18. Internationalen Rechtsinformatik Symposions IRIS 2015. Wien: Österreichische Computer Gesellschaft (OCG), p. 155, 2015.
- 49 Heussler/Schossböck/Böszörmenyi (note 13).





