1.
State of the art: Maschinen-lesbare Anfragen und Menschen-lesbare Anfragen ^
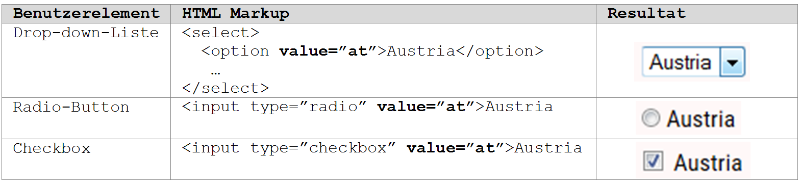
[B] Die Information der Anfrage wird als Freitext an den Server übermittelt. Der an den Server gesendete Wert wird nicht vom System vorgegeben. Benutzerelemente dieser Art umfassen ein- und mehrzeilige Textfelder (<input> und <textarea>). Gewöhnlich werden diese Benutzerelemente im Rahmen von Anfragen an ein OBIS ausschließlich zur Stichwortsuche herangezogen. Stichwörter werden serverseitig entweder in einem Tagging-System oder als Volltextsuche implementiert; das Prinzip bleibt letztendlich dasselbe: Ein Suchalgorithmus versucht aus einer Menge von in der Datenbank des Systems gespeicherten Contents mittels einer Trägerfunktion (von bisweilen hoher Komplexität!) die relevantesten Ergebnisse zu ermitteln.
Es lohnt sich ein Blick auf zwei tatsächliche OBIS: Die Plattform www.help.gv.at (in der Folge als HELP bezeichnet) liefert Bürgern Informationen zu Behördenwegen aller Art. Die Plattform wurde 1997 vom Bundesministerium für Finanzen lanciert und hat sich nach beständiger Weiterentwicklung zur wichtigsten Drehscheibe der österreichischen E-Administration entwickelt.
Zusammenfassend kann eine Tabelle erstellt werden, die die Kommunikationsmöglichkeiten von OBIS beschreibt:
| Benutzer sendet eine Anfrage | parametrisierte Anfrage | natürliche Sprache |
| Anfrage wird vom System verarbeitet | Maschinen-lesbare Anfrage | Menschen-lesbare Anfrage |
| Antwort wird generiert | Automatisiertes Content Retrieval | Menschlicher Vermittler |
| Antwort wird an Benutzer übermittelt | Aus einer Menge vorgefertigter Contents | «Maßgeschneiderter» Content |
2.
Linked Open Government ^
Christian Bizer beschrieb das Dilemma von elektronischen Verwaltungsdaten im Jahre 2009 wie folgt: «The great majority of public-sector data is either not accessible on the Web or accessible only in two forms: Human-readable formats […] and proprietary data formats». Die erste Form erlaubt keine maschinelle Auswertung der zur Verfügung gestellten Information und die zweite macht es nötig, dass die potentiellen Konsumenten der Information im Besitz der richtigen Software sind, um die benötigten Daten auslesen zu können [1]. Um diesen Defiziten zu begegnen, ist ein Modus zu schaffen, Daten des öffentlichen Sektors in Maschinen-lesbarer Form darzustellen, in einem offenen Format und basierend auf einem gemeinsamen Vokabular – denn es sollen nicht nur verschiedenartige, abstrakte Dokumentstrukturen, sondern Contents mit einer Maschinen-lesbaren Bedeutung über das World Wide Web ausgetauscht werden können, Contents, die so reich aufbereitet sind, dass sie eine Maschinen-verständliche Beschreibung der Dinge, die sie beinhalten, bereitstellen. Dies sind die Anforderungen an Linked Open Government Data.
Man kann zweifelsfrei sagen, dass es in den letzten fünf Jahren auf diesem Gebiet Fortschritte gegeben hat, besonders im Bereich der Open Government Data Initiativen: Das US-amerikanische OGD Portal www.data.gov wurde 2009 gestartet, das britische Gegenstück www.data.gov.uk folgte 2010. Die EU fördert OGD durch die Public Sector Information Direktive (PID) 2003 und durch das Open Data Package 2011 [3]. Österreich startete sein Projekt «LOD Pilot AT» im Jahre 2014 (http://www.lodpilot.at) – hier wurden Datensätze von unterschiedlichen Open Data Portalen integriert, sowohl Verwaltungsdaten als auch Nicht-Verwaltungsdaten (etwa vom Open Data Portal Austria https://www.opendataportal.at, einer Sammlung von offenen Daten aus einem weiten Themenbereich). Diese Daten wurden in ein einheitliches Format konvertiert und können über eine Web API angesprochen werden.
3.
Herausforderungen an das Natural Language Processing ^
4.
Zu einem besseren OBIS mit Hilfe semantischer Technologien? ^
Das österreichische Online Portal http://www.lehre.at setzt sich zum Ziel, Informationen über Lehrberufe zur Verfügung zu stellen. Informationen sollen so vollständig wie möglich und so einfach zugänglich wie möglich präsentiert werden. Das Portal integriert dabei Informationen aus verschiedenen Datenquellen, wie etwa dem Online Business Intelligence Tool https://www.diebestenlehrbetriebe.at, bei welchem Firmen die Qualität ihrer Lehrlingsausbildung evaluieren lassen können.
Um beurteilen zu können, wie das System (und zukünftige Systeme auf ähnlicher Basis) vom Einsatz semantischer Technologien profitieren könnten, wird eine Ontologie in der Domäne Lehre entwickelt. Um den Umfang der Ontologie bestimmen zu können, wird eine Liste von Fragen aufgestellt, die das System beantworten können soll (sog. competency questions [5]). Die Liste beinhaltet so u.a.:
- Wo kann ich in der Nähe meiner Heimatstadt eine Lehrstelle finden, die meinen Fähigkeiten entspricht?
- Welche Lehrstellen gibt es, die eine Berufsschule in der Nähe meines Wohnorts anbieten?
- Welche Fähigkeiten werden benötigt, um Augenoptiker zu werden?
- Welcher Lehrberuf wird in Wien am besten entlohnt?
- Welche ausbildungsrechtlichen Probleme könnten sich ergeben, wenn ich von Lehrberuf A zu Lehrberuf B wechsle?
- Welche Firmen im Gesundheitswesen bieten eine Ausbildung an, die von https://www.diebestenlehrebtriebe.at am besten bewertet wurde?
Man kann sehen, dass es sich um einen Mix aus ausbildnerischen, geografischen, arbeitsmarkttechnischen und berufsrechtlichen Fragestellungen handelt. Auch sollen Evaluierungen, die auf dem Portal https://diebestenlehrbetriebe.at erstellt wurden, in Betracht gezogen werden. Die Wiederverwendung und Weiterentwicklung bestehender Ontologien wird diskutiert; allerdings existiert zum jetzigen Zeitpunkt keine verwertbare Ontologie, die die spezielle Situation der Lehrausbildung in Österreich wiederzugeben vermag.
5.
Literatur ^
[1] Bizer, Christian, The Emerging Web of Linked Data, IEEE Intelligent Systems, vol. 24, no. 5, pp. 87–92, September–October 2009
[2] Heath, Tom/Bizer Christian, Evolving the Web into a Global Data Space, Morgan & Claypool, 2011
[3] Ding, Li/Peristeras, Vassilios/Hausenblas Michael, Linked Open Government Data, IEEE Intelligent Systems, vol. 27, no. 3, pp. 11–15, May–June 2012
[4] Maynard, Diana/Li, Yaoyang/Peters, Wim, NLP Techniques for Term Extraction and Ontology Population, https://gate.ac.uk/sale/olp-book/main.pdf (as per 6 January 2016)
[5] Noy, Natalya F./McGuinness, Deborah, Ontology Development 101: A Guide to Creating Your First Ontology, Stanford Knowledge Systems Laboratory Technical Report KSL-01-05 and Stanford Medical Informatics Technical Report SMI-2001-0880, 2001, http://www.ksl.stanford.edu/people/dlm/papers/ontology-tutorial-noy-mcguinness.pdf (as per 6 January 2016)
[6] Russell, Stuart/Norvig, Peter, Artificial Intelligence. A Modern Approach, Third Edition, Pearson Eudcation Inc., 2010
[7] Traunmüller, Roland/Krenmayr, Andreas, Bürgerinformationssysteme – Neue Vorstellungen, In: Schweighofer, Erich, Kummer, Franz, Hötzendorfer (Hrsg.), Kooperation. Tagungsband des 18. Internationalen Rechtsinformatik Symposions. IRIS 2015, Wien 2015.





