1.
Zur Fragestellung ^
2.
Rechtsvorschriftentexte ^
§ 75. Wer einen anderen tötet, ist mit Freiheitsstrafe von zehn bis zu zwanzig Jahren oder mit lebenslanger Freiheitsstrafe zu bestrafen.
1 Satz = 1 Norm oder 19 Worte = 1 Norm
2.1.
Definitionen ^
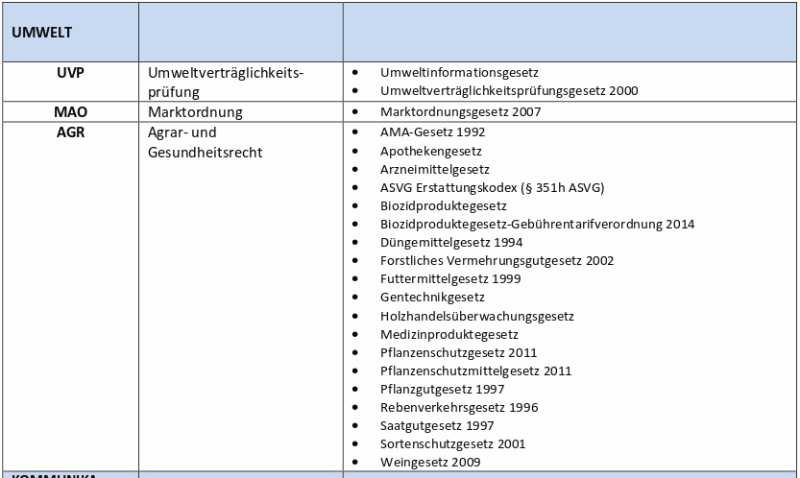
Definitionen legen die in den übrigen Texten verwendeten Spezialbegriffe fest und bilden daher die Grundlage für diese Texte. Eine Änderung dieser Textteile führt meist auch zu Anpassungen im Rest des Rechtsvorschriftentextes. Aus diesem Grund kommt es in diesem Bereich selten zu nachträglichen Veränderungen. Ist dies jedoch der Fall, so ist der Änderungsaufwand im System sehr hoch.
Die Zuordnungen zur Zuweisungsgruppe UVP lassen sich dann in der bereits oben verwendeten Darstellung schreiben als:
UIG(x) → UVP(x)
UVP – G(x) → UVP(x)
2.2.
Tabellarische Normen ^
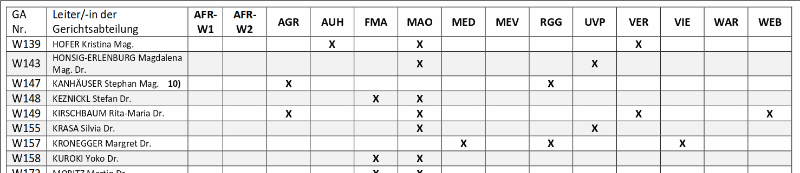
Für die Gerichtsabteilung W139 können daher folgende Zuständigkeitsnormen formuliert werden:
AUH(x) → Z(W139, x)
MAO(x) → Z(W139, x)
VER(x) → Z(W139, x)
Für die Zuweisungsgruppe UVP wiederum ergeben sich aus dem Anhang zur Geschäftsverteilung neun Zuständigkeitsnormen, die zu einander in Konkurrenz9 stehen:
UVP(x) → Z(W102, x)
UVP(x) → Z(W104, x)
UVP(x) → Z(W102, x)
UVP(x) → Z(W109, x)
UVP(x) → Z(W113, x)
UVP(x) → Z(W155, x)
UVP(x) → Z(W180, x)
UVP(x) → Z(W193, x)
UVP(x) → Z(W225, x)
2.3.
Listen ^

Zusätzlich zu der stark strukturierten Darstellung in Tabellen enthält Anlage 2 noch die Festlegung von abweichenden Zuweisungsregeln, wie z.B. die in Abbildung 3 dargestellte.
Diese Verwendung von Listen in dieser Darstellung entspricht dem Einsatz von logischen oder-Operationen, die eine Vervielfachung der Normen zur Folge haben.
Für die Schätzung der Normen bedeutet dies, dass die Zahl der Normen pro Text proportional zu den Listenelementen ist und auch die Dichte an definierten Normen entsprechend zunimmt.
Die Veränderung der Normdichte im Text mit jeder Gerichtsabteilung, die der Liste im Rechtsvorschriftentext hinzugefügt wird, zeigt die folgende Tabelle:
| Wörter | Zeichen | GA | Wörter/Norm(Durchschnitt) |
| 26 | 209 | 1 | 26 |
| 31 | 241 | 2 | 15,5 |
| 36 | 276 | 3 | 12 |
| 41 | 306 | 4 | 10,25 |
| 47 | 343 | 5 | 9,4 |
| 52 | 374 | 6 | 8,6 |
Für eine Abschätzung der Normenzahl bedeutet dies, dass es wieder ausreicht, die Zahl der Listenelemente zu zählen. Sie entspricht der Normenzahl, wenn die Normen eine einfache Struktur haben und nicht durch komplexe Teilregelungen selbst wieder in mehrere Normen zerlegt werden müssen.
Auch hier gilt wie bei den Tabellen, dass bei einer höheren Zahl an Listenelementen auch der Fehler bei Hochrechnungen stark ansteigt.
Zu beachten ist, dass die in dieser Form dargestellten abweichenden Regeln vielfach eine legistische Reaktion auf unerwartete oder unvorhersehbare Ereignisse oder Tatsachen sind und daher gerade diese Normen öfter angepasst werden, was mit viel Änderungs- und Wartungsaufwand verbunden sind.
3.
Die normative Dichte und Schätzungen ^
Die normative Dichte, also die durchschnittliche Zahl der Normen pro Wort, gibt einen Hinweis auf die wahrscheinliche Genauigkeit der Schätzung. Je größer die normative Dichte einer Darstellungsform ist – also je weniger Wörter im Durchschnitt pro Norm verwendet werden –, desto größer ist wahrscheinlich auch der Fehler der Schätzung.
Eine Auswertung der Regelbasis des Zuweisungsmoduls ergibt, dass für die aktuelle Geschäftsverteilung 789 Regeln (= Zuweisungsnormen) eingetragen sind. Zusätzlich sind für die Zuordnung von Rechtsbereichen und Zuweisungsgruppen 488 Regeln angelegt.
Anlage 1 der Geschäftsverteilung (= Zuordnung von Rechtsbereichen und Zuweisungsgruppen) hat 14 Seiten, wovon aber 3,5 Seiten wegen Seitenumbrüchen, … leer sind.
In Anlage 1 enthält diebeschriebenen Tabellen mit Listen. Eine Zählung aller Listeneinträge auf Seite 1 ergibt 49 Einträge/Normen. Multipliziert man diese Anzahl mit den 10,5 bedruckten Seiten, dann ergibt das eine errechnete Schätzung von 514,5 Normen. Das bedeutet einen Schätzfehler von 5%.
Anlage 2 hat 27 Seiten, von denen ungefähr 4 Seiten nicht bedruckt sind. Die Zahl der Normen aus der ersten Tabelle ist 77. Die Anzahl der Normen in abweichenden Regelungen ergibt 16. Beides zusammen ist auf den ersten 4 Seiten der Anlage zu finden. Insgesamt sind daher auf den ersten 4 Seiten 93 Normen, wobei zu beachten ist, dass die normative Dichte von Tabellen sehr hoch und die Tabelle zusätzlich sehr lang ist. Die Schätzung der Normenzahl ist damit: 23 Seiten x 93 Normen/4 Seiten = 534,75
Diese Schätzung hat einen Fehler von 33%, noch dazu in Richtung eines zu geringen Aufwands, was bei EDV-Projekten besonders problematisch ist.
Die Rechnung zeigt – wie erwartet –, dass bei Schätzungen zur Formalisierung von Rechtstexten mit Strukturen, die eine hohe normative Dichte haben, mit großen Abweichungen zu rechnen ist.
4.
Literatur ^
Arenas, Marcelo/Gutierez, Claudio/Pérez, Jorge, Foundations of RDF Databases, In: Tessaris, Sergio/Eiter, Thomas/Gutierrez, Claudio/Handschuh, Siegfried/Rousset, Marie-Christine/Schmidt, Renate A. (Hrsg.), Reasoning Web – Semantic Technologies for Information Systems, Springer Verlag, Berlin Heidelberg 2009, S. 158–204.
Baader, Franz, Description Logic, In: Tessaris, Sergio/Eiter, Thomas/Gutierrez, Claudio/Handschuh, Siegfried/Rousset, Marie-Christine/Schmidt, Renate A. (Hrsg.), Reasoning Web – Semantic Technologies for Information Systems, Springer Verlag, Berlin Heidelberg 2009 (S. 1-39).
Baader, Franz/Calvanese, Diego/McGuinness, Deborah L./Nardi, Daniele/Patel-Schneider, Peter F. (Hrsg.), The Description Logic Handbook2, Cambrdge University Press, Cambridge 2007 (Nachdruck 2008).
Bal, Jaroslaw/Brzykcy, Grazyna/Jedrzejek, Czeslaw, Extended Rules in Knowledge-Based Data Access. In: Olken, Frank/Palmirani, Monica/Sattora, Davide (Hrsg.), Rule-based Modeling and Computing on the Semantic Web, Proceedings ot the 5th International Symposium, RuleML 2011, Springer-Verlag, Berlin Heidelberg 2011, S. 112–127.
Balzert, Helmut, Lehrbuch der Software-Technik, Spektrum akad. Verlag, Heidelberg 1996.
Calvanese, Diego/De Giacamo, Giuseppe/Lembo, Domenico/Lenzerini, Maurizio/Poggi, Antonella/Rodrigez-Muro, Mariano/Rosati, Riccardo, Ontologies and Databases: The DL-Lite Approach, In: Tessaris, Sergio/Eiter, Thomas/Gutierrez, Claudio/Handschuh, Siegfried/Rousset, Marie-Christine/Schmidt, Renate A. (Hrsg.), Reasoning Web – Semantic Technologies for Information Systems, Springer Verlag, Berlin Heidelberg 2009, S. 225–356.
Casanovas, Pompeu/Sartor, Giovanni/Biasiotti, Maria Angela/Férnandez-Barrera, Meritxell, Introduction: Theory and Methodology in Legal Ontology Engineering: Experiences and Future Directions, In: Sartor, Giovanni/Casanovas, Pompeu/Biasiotti, Maria Angela/Férnandez-Barrera, Meritxell, Approaches to Legal Ontologies, Springer 2011, S. 1–14.
Ciaghi, Aaron/Dalla Valle, Andrea/Villafiorita, Adolfo, Adapting software Metrics to Analyze the Evolution of Laws, In: Atkinson, Katie M., Legal Knowledge and Information systems, IOS Press, Amsterdam 2011, S. 53–62.
Das, Souripriya/Srinivasan, Jagannathan, Database Technologies for RDF, In: Tessaris, Sergio/Eiter, Thomas/Gutierrez, Claudio/Handschuh, Siegfried/Rousset, Marie-Christine/Schmidt, Renate A. (Hrsg.), Reasoning Web – Semantic Technologies for Information Systems, Springer Verlag, Berlin Heidelberg 2009, S. 205–221.
Gantner, Felix, Theorie der juristischen Formulare, Duncker & Humblot, Berlin 2010.
Lachmayer, Friedrich/Reisinger, Leo, Legistische Analyse der Struktur von Gesetzen, Manz, Wien 1976.
Patton, Jeff, User Story Mapping, O’Reilly Verlag, Köln 2015.
Philipps, Lothar, Von Puppen aus Russland und einer Rechtslehre aus Wien. Der Rekursionsgedanke im Recht. In: Philipps, Lothar, Endliche Rechtsbegriffe und unendliche Grenzen – Rechtslogische Aufsätze, Editions Weblaw, Bern 2012, S. 97.
van Harmelen, Frank/Lifschitz, Vladimir/Porteer, Bruce (Hrsg.), Handbook of Knowledge Representation, Elsevier, Amsterdam 2008.
Walter, Stephan, Definitionsextraktion aus Urteilstexten. Saarbrücken dissertations in computational linguistics and language technology Band 31, Saarland Univ., Department of Computational Linguistics and Phonetics, Saarbrücken 2010.
Waltl, Bernhard/Matthes, Florian, Comparison of Law Texts: An Analysis of German and Austrian Law Texts Regarding Linguistic and Structural Metrics, In: Schweighofer, Erich/Kummer, Franz/Hötzendorfer, Walter (Hrsg.), Kooperation, Tagungsband des 18. Internationalen Rechtsinformatik Symposions IRIS 2015, OCG, Wien 2015, S. 163–172.
- 1 Unter https://www.bvwg.gv.at/amtstafel/sonstige_veroeffentlichungen.html wird die aktuelle Geschäftsverteilung des BVwG veröffentlicht.
- 2 Bal, Jaroslaw/Brzykcy, Grazyna/Jedrzejek, Czeslaw, Extended Rules in Knowledge-Based Data Access. In: Olken, Frank/Palmirani, Monica/Sattora, Davide (Hrsg.), Rule-based Modeling and Computing on the Semantic Web, Proceedings ot the 5th International Symposium, RuleML 2011, Springer-Verlag, Berlin Heidelberg 2011, S. 112–127 (S. 114).
- 3 Jeff Patton bezeichnet die in Software-Projekte häufig geforderte genaue Schätzung als Aufgabe, deren Name bereits widersprüchlich ist: «Wenn wir ganz genau wüssten, wie lang etwas braucht, dann würden wir nicht von Schätzungen sprechen» (Patton, Jeff, User Story Mapping, O’Reilly Verlag, Köln 2015, S. 61).
- 4 Es wird hier zur besseren Lesbarkeit eine einfache logische Darstellungsform verwendet. Zu technisch besser geeigneten Darstellungen vgl. z.B. van Harmelen, Frank/Lifschitz, Vladimir/Porteer, Bruce (Hrsg.), Handbook of Knowledge Representation, Elsevier, Amsterdam 2008; Baader, Franz, Description Logic, In: Tessaris, Sergio/Eiter, Thomas/Gutierrez, Claudio/Handschuh, Siegfried/Rousset, Marie-Christine/Schmidt, Renate A. (Hrsg.), Reasoning Web – Semantic Technologies for Information Systems, Springer Verlag, Berlin Heidelberg 2009 (S. 1-39); Baader, Franz/Calvanese, Diego/McGuinness, Deborah L./Nardi, Daniele/Patel-Schneider, Peter F. (Hrsg.), The Description Logic Handbook2, Cambrdge University Press, Cambridge 2007 (Nachdruck 2008).
- 5 Problemlos meint in diesem Fall nur, dass der Text selbst einfach formal dargestellt werden kann. Die großen Herausforderungen, die die Interpretation der einzelnen Rechtsbegriffe und der u.U. damit verbundene Aufbau juristischer Ontologien, zusätzlicher (Unter)Regeldefinitionen, ... mit sich bringt, werden hier nicht weiter behandelt.
- 6 Vgl. dazu auch Walter, Stephan, Definitionsextraktion aus Urteilstexten. Saarbrücken dissertations in computational linguistics and language technology Band 31, Saarland Univ., Department of Computational Linguistics and Phonetics, Saarbrücken 2010.
- 7 Vgl. zu Ontologien z.B. Casanovas, Pompeu/Sartor, Giovanni/Biasiotti, Maria Angela/Férnandez-Barrera, Meritxell, Introduction: Theory and Methodology in Legal Ontology Engineering: Experiences and Future Directions, In:Sartor, Giovanni/Casanovas, Pompeu/Biasiotti, Maria Angela/Férnandez-Barrera, Meritxell, Approaches to Legal Ontologies, Springer 2011, S. 1–14; Calvanese, Diego/De Giacamo, Giuseppe/Lembo, Domenico/Lenzerini, Maurizio/Poggi, Antonella/Rodrigez-Muro, Mariano/Rosati, Riccardo, Ontologies and Databases: The DL-Lite Approach, In: Tessaris, Sergio/Eiter, Thomas/Gutierrez, Claudio/Handschuh, Siegfried/Rousset, Marie-Christine/Schmidt, Renate A. (Hrsg.), Reasoning Web – Semantic Technologies for Information Systems, Springer Verlag, Berlin Heidelberg 2009, S. 225–356; Arenas, Marcelo/Gutierez, Claudio/Pérez, Jorge, Foundations of RDF Databases, In: Tessaris, Sergio/Eiter, Thomas/Gutierrez, Claudio/Handschuh, Siegfried/Rousset, Marie-Christine/Schmidt, Renate A. (Hrsg.), Reasoning Web – Semantic Technologies for Information Systems, Springer Verlag, Berlin Heidelberg 2009, S. 158–204.
- 8 Zur kombinatorischen Erzeugung bzw. Überprüfung von Normen über Tabellen vgl. Lachmayer, Friedrich/Reisinger, Leo, Legistische Analyse der Struktur von Gesetzen, Manz, Wien 1976, S. 64 ff.
-
9
Die Konkurrenz zwischen den Zuständigkeitsnormen wird durch §23 der Geschäftsverteilung aufgelöst:
§ 23. Durchführung und Priorisierung der allgemeinen Zuweisung
(3) Soweit in dieser Geschäftsverteilung nichts anderes bestimmt ist (z.B. gesonderte Zuweisung von Annexsachen oder Zuweisung wegen Befangenheit, Auslassungen bei der Zuweisung, Vorwegzuweisung oder Zuweisungssperre), werden Rechtssachen, die in die Zuständigkeit mehrerer Gerichtsabteilungen am Hauptsitz oder in den Außenstellen fallen, getrennt für jede Zuweisungsgruppe einzeln den dafür zuständigen Gerichtsabteilungen nacheinander zugewiesen, und zwar in aufsteigender Reihenfolge ihrer Gerichtsabteilungsnummern, beginnend bei der niedrigsten. Kommt so eine weitere Zuweisung in aufsteigen der Reihenfolge der Gerichtsabteilungsnummern nicht mehr in Frage, dann ist die Zuweisung in der genannten Reihenfolge wieder von vorne zu beginnen (neue Zuweisungsrunde) und so lange auf diese Weise fortzusetzen, bis alle Rechtssachen den zuständigen Gerichtsabteilungen zugewiesen sind.
Durch diese Vorschrift wird ein Zustandsystem bzw. -automat (vgl. Balzert, Helmut, Lehrbuch der Software-Technik, Spektrum akad. Verlag, Heidelberg 1996, S. 270ff) definiert, das mit den Darstellungsformen der klassischen Logik nicht beschreibbar ist. Die Zuweisungsregeln könnten daher besser als rekursive Normen (vgl. Philipps, Lothar, Von Puppen aus Russland und einer Rechtslehre aus Wien. Der Rekursionsgedanke im Recht. In: Philipps, Lothar, Endliche Rechtsbegriffe und unendliche Grenzen – Rechtslogische Aufsätze, Editions Weblaw, Bern 2012, S. 97 ff.) beschrieben werden:
∀n ≥ 1
UVP(xn) ∧ (n = 1∨Z(W225, xn–1)) → Z(102, xn)
UVP(xn) ∧ Z(W102, xn–1) → Z(104,xn)
…
UVP(xn) ∧ Z(W180, xn–1) → Z(193, xn)
UVP(xn) ∧ Z(W193, xn–1) → Z(225, xn) - 10 Die Dichte ist umso größer, je weniger Wörter im Durchschnitt pro Norm benötigt werden.
- 11 Vgl. zur Entfaltung von Rechtsbegriffen im Rahmen der Subsumtion Gantner, Felix, Theorie der juristischen Formulare, Duncker & Humblot, Berlin 2010, S. 43ff.





