1.
Introduction ^
Recent developments in legal science and practice have shown that legal data analysis is a promising field. Legal tasks are increasingly becoming data-, time-, and knowledge-intensive. On the other hand, computer science has made huge progress in the domain of data mining, in particular in text mining. Algorithms processing unstructured information, i.e. text, can produce highly accurate results, with respect to precision but also to recall. Although the algorithms have been developed and are continuously improving, only less effort has been spent on tailoring those technologies to the legal domain. However, this tailoring is a crucial step in order to reproduce those high quality results outside the domains for which those text mining technologies have been developed and trained. This paper proposes a data model, which was developed to represent the particularities of legal literature (see Section 1). Thereby, it allows the processing, generation, and persisting of structured but also of unstructured data. The implementation of an adapted UIMA (Unstructured Information Management Architecture), which has originally been developed by IBM and was later on the base line for the IBM Watson software suite, allows the development and usage of most recent natural language processing (NLP) technologies. Furthermore, it enables the integration of components to perform qualitative and quantitative analysis on text corpora (see Section 5). Based on that, huge legal text corpora can be analyzed, summarized, explored and visualized in a data scientifically way. This allows the creation of new views, perspectives and representations on textually represented data. This can exemplarily be used to determine semantic structures in laws or to semantically analyze textual norms within claims examinations or due diligence to unveil inconsistencies or vagueness, increasing the exposure to risk. It has the potential to be a paradigm shift in legal science and practice.
2.
Research method and objectives: The legal domain – a challenge for data science ^
To achieve highest accuracy with NLP it is necessary, that the environment and data model are adapted to the domain of investigation, which is in this case the domain of legal data modelling and processing with a special focus on Germany. However, much effort has already been spent on NLP and processing of unstructured data (see Section 3) but hardly anyone investigated the environment which can be the base line for the analysis and allows for reuse and interoperability of components. By providing a reference architecture and a generic and flexible data model this paper shows how a tailored base line environment can look like.
Throughout this paper an adapted design science approach, originally proposed by Hevner (2004), has been used. Firstly, the problem relevancy has been analyzed and is briefly sketched (see Section 1 above and Section 3). Secondly, the focus is set on the design of a new artifact, i.e., a data science environment (see Section 4). Afterwards, the applicability is evaluated and the research contribution is summarized (see Sections 5 and 6).
3.
Related work ^
Recently, Grabmair et al. (2015) published preliminary results about the adaptation of the UIMA1. They developed a «law-specific semantic based toolbox» to automatically annotate semantic patterns at a sub-sentence level. The rules expressing those phrases are codified in Apache Ruta2, which is also used in data science environment proposed in this article. Apache Ruta is not only an established but also a maintainable and reusable pattern definition expression language.
As stated above, text mining and algorithmic processing of textual data has been in the focus of researchers and generic but monolithic workbenches, e.g., GATE (with its Jape grammar), and software packages, e.g., NLTK, have already been proposed. However, without a particular tailoring to the legal domain those do not enable data scientists to easily produce most accurate results and additionally allow the interaction with visualization and reporting engines for discovering and exploring algorithmically processed legal data.
4.1.
Reference architecture for the data science environment ^
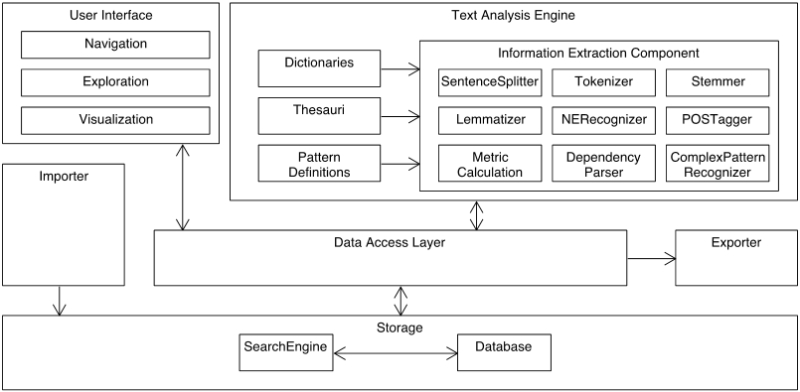
Figure 1 shows a comprehensive reference architecture consisting of an importer, an exporter, a data storage and access layer, a text mining engine, and a user interface. Based on the reference architecture we developed a collaborative web application with a Java back-end. Additionally, the search engine ElasticSearch for efficient access to the textual data has been integrated.
4.2.
Data Model, Data Storage and Access ^
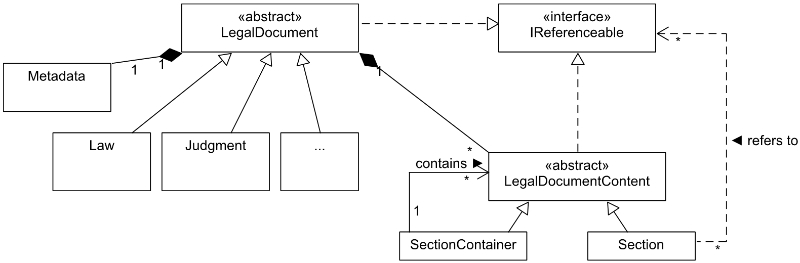
The content of the LegalDocument is implemented as a composite pattern (component: LegalDocumentContent; composite: SectionContainer; leaf: Section) (Gamma, 1994), this follows the nested structure laws in Germany have. Therefore, the data model is able to represent the nested structure of laws or judgments but is also open for flat hierarchies in documents. E.g. the German Civil Code consists of two books, which consist of several divisions, which – in turn – consist of several titles and so forth (German Civil Code, 2014). At the end of this different containers, the Sections, which hold the content of norms, are stored. This tree like structure has to be conserved by the data model since it is part of official legislative and jurisdictional documents and the containers group logically related norms together, which can then be referenced. The referencing structure is implemented via interfaces, such that each Section can have multiple references to LegalDocument or to LegalDocumentContent.
4.3.
Text Mining Engine ^
Based on the data model the text mining engine applies state-of-the-art analysis methods to legal texts. It consists of a variety of reusable components and can easily be extended with new components. As baseline architecture Apache UIMA was used. UIMA allows the composing of components in a generic and easy adaptable environment. Furthermore, it is suitable for an integration in a collaborative web platform. Consequently, the Information Extractor Component (Figure 1) extracts and annotates semantic information a legal text. Additionally, dictionaries, thesauri, and pattern definitions are required in order to detect this semantic information accordingly. We are able to use two kinds of pattern definitions: regular expressions (regex) and Ruta expressions (rule-based text annotation). The Ruta expressions allow the specification of complex linguistic structures (see Listing 1).
4.4.
Importer and Exporter ^
The importing structure is required to transform the input data, which can be of any data type (PDF, Word, XML, etc.), into the data model of our system. Therefore, the import architecture was designed such that it is possible to develop highly specified import components and at the same time easily support new file and document types.
The exporter component provides interfaces for other applications (e.g., REST APIs). The current implementation only provides methods to create data dumps (CSV) of the semantic entities and their occurrence, allowing the reuse in existing reporting and dashboard engines (e.g., Excel, etc.). Based on upcoming use cases the exporter component can be enhanced and adapted to support more functionality.
5.
Unveiling semantic structures in laws ^
5.1.
Determining legal definitions in legal texts using Apache UIMA and Apache Ruta ^

Listing 1 defines the linguistic pattern specifying legal definitions in the German Civil Code. Determining legal definitions is highly relevant in the legal domain and has been in the focus of researchers for several times (see Section 3). The code example starts by defining baseline linguistic patterns as words and key phrases (Line 1–10). Afterwards, it specifies the rules that, if found in the legal text, refer to a legal definition. For instance, the legal definition of the term «Sache» in the German Civil Code (BGB, §90ff):
§ 90: Eine Sache im Sinne des Gesetzes sind nur körperliche Gegenstände.
§ 90a: Tiere sind keine Sachen. [...]
§ 91: Vertretbare Sachen im Sinne des Gesetzes sind bewegliche Sachen, die im Verkehr nach Zahl, Maß oder Gewicht bestimmt zu werden pflegen.
§ 92: Verbrauchbare Sachen im Sinne des Gesetzes sind bewegliche Sachen, deren bestimmungsmäßiger Gebrauch in dem Verbrauch oder in der Veräußerung besteht.
5.2.
UIMA pipeline for semantic annotation of legal texts ^
The pipes & filters architecture of UIMA allows the creation of processing pipelines (see Figure 3). Various tailored software components (Splitter, Segmenter, Tokenizer, Tagger, Ruta) are concatenated in order to fulfill a complex processing task. We have developed the components especially for the German domain, taking into account the textual and editorial style, such as abbreviations, enumerations and listings, bracketing, etc. They can be (re-)used individually and almost arbitrarily be combined for other texts of the German legislation.

The last processing step of the pipeline shown in Figure 3 takes the script as introduced above into account and determines the semantic entities «Legal Definitions». Finally, those semantic entities are persisted and the user is not only able to export them into a separate CSV file, but also to access it via a search interface, view it in the browser instantly and share the view with other users collaboratively.
5.3.
Accessing results and annotations through the user interface ^
The user interface allows the data scientist to access the textual representation of the law. After the processing of an analysis pipeline, the user does not only see the actual law text and its structure, i.e., books, chapters, subchapters, sections, etc., but also the available semantic entities that have been automatically determined. The exploration screen is divided into three different sections, namely the control section (left), the text section (middle) and the information section (right). Figure 4 shows the user interface. Thereby, the user interface is interactive and enriches the textual representation with the information selected by the user. Figure 4 shows the highlighted semantic entities «LegalDefinition» (dark green) and «LegalEntity» (turquoise).

In addition to the highlighted passages in the text, the available annotations are listed in information section as it can be seen in Figure 4.
6.
Conclusion, outlook, and future applications ^
7.
Acknowledgement ^
8.
Bibliography ^
Larenz, Karl; Canaris, Claus-Wilhelm (1995): Methodenlehre der Rechtswissenschaft. Berlin, Springer.
Katz, Daniel; Martin; Bommarito, M. J., II (2014): Measuring the complexity of the law: the United States Code. In: Artif Intell Law 22 (4), pp. 337–374. DOI: 10.1007/s10506-014-9160-8.
Federal Ministry of Justice and Consumer Protection: German Civil Code. Hg. v. juris GmbH.
Gamma, Erich; Helm, Richard; Johnson, Ralph; Vlissides, John (1994): Design patterns: elements of reusable object-oriented software: Pearson Education.
Gordon, T; Prakken, H.; Walton, D. (2007): The Carneades model of argument and burden of proof. In: Artificial Intelligence 171.
Grabmair, Matthias; Ashley, Kevin D.; Chen, Ran; Sureshkumar, Preethi; Wang, Chen; Nyberg, Eric; Walker, Vern R. (2015): Introducing LUIMA: An Experiment in Legal Conceptual Retrieval of Vaccine Injury Decisions Using a UIMA Type System and Tools. In: Proceedings of the 15th International Conference on Artificial Intelligence and Law, pp. 69–78.
Hart, H. L. A (1961): The concept of law. Oxford University Press (Clarendon law series).
Hevner, Alan R.; March, Salvatore T.; Park, Jinsoo; Ram, Sudha (2004): Design science in information systems research. In: MIS quarterly 28 (1), pp. 75–105.
Houy, Constantin; Niesen, Tim; Calvillo, Jesús; Fettke, Peter; Loos, Peter; Krämer, Annika et al. (2015): Konzeption und Implementierung eines Werkzeuges zur automatisierten Identifikation und Analyse von Argumentationsstrukturen anhand der Entscheidungen des Bundesverfassungsgerichts im Digital-Humanities-Projekt ARGUMENTUM. In: Datenbank Spektrum, pp. 1–9. DOI: 10.1007/s13222-014-0175-9.
Maat, Emile de; Winkels, Radboud (2010): Automated Classification of Norms in Sources of Law. In: Enrico Francesconi (Hg.): Semantic processing of legal texts. Where the language of law meets the law of language. Springer, pp. 170–191.
Walter, Stephan (2009): Definition extraction from court decisions using computational linguistic technology. In: Formal Linguistics and Law 212, p. 183.
Wyner, Adam; Mochales-Palau, Raquel; Moens, Marie-Francine; Milward, David (2010): Approaches to text mining arguments from legal cases. In: Enrico Francesconi (ed.): Semantic processing of legal texts. Where the language of law meets the law of language. Berlin, New York: Springer, pp. 60–79.
- 1 Apache UIMA, https://uima.apache.org/, all web pages last access on 12 December 2015.
- 2 Apache Ruta, https://uima.apache.org/d/ruta-current/tools.ruta.book.html.





