1.
Einleitung ^
Es wird ein auf Scrum basierender Softwareentwicklungsprozess vorgestellt, der systematische Mechanismen zur Umsetzung von Security- und Privacy-Anforderungen beinhaltet. Scrum ist ein leichtgewichtiges Framework zur Lösung komplexer Probleme, um produktiv und kreativ ein bestmögliches Produkt zu liefern. Das Framework beruht auf der empirischen Prozesskontrolle, d.h. produzierte Artefakte werden nicht als gegeben angesehen, sondern stets einem iterativen Verbesserungsprozess unterzogen.1 Weitere Grundlagen zu Scrum können in der an der jeweiligen Stelle angeführten Literatur und in zahlreichen weiteren Quellen nachgelesen werden und werden als Basis der nachfolgenden Ausführungen vorausgesetzt.
In der Konzeption des Prozesses wurde auf verschiedenen Ansätzen aufgebaut, die den Gebieten Security by Design bzw. Secure Coding zuzuordnen sind und jeweils referenziert sind. Die daraus abgeleiteten Konzepte wurden darüber hinaus um die Berücksichtigung von Privacy by Design erweitert. Der so konzipierte Prozess dient im Projekt «ePartizipation – Authentifizierung bei demokratischer Online-Beteiligung» als Grundlage für die Entwicklung des Demonstrators. Erste Erfahrungen mit dem Prozess werden in Kapitel 4 diskutiert. Im vorliegenden Beitrag soll überwiegend auf die Privacy-Aspekte des Prozesses eingegangen werden.
2.
Privacy und Security by Design ^
- MINIMISE: The amount of personal data that is processed should be restricted to the minimal amount possible.
- HIDE: Any personal data, and their interrelationships, should be hidden from plain view.
- SEPARATE: Personal data should be processed in a distributed fashion, in separate compartments whenever possible.
- AGGREGATE: Personal data should be processed at the highest level of aggregation and with the least possible detail in which it is (still) useful.
- INFORM: Data subjects should be adequately informed whenever personal data is processed.
- CONTROL: Data subjects should be provided agency over the processing of their personal data.
- ENFORCE: A privacy policy compatible with legal requirements should be in place and should be enforced.
- DEMONSTRATE: Be able to demonstrate compliance with the privacy policy and any applicable legal requirements.
Der nachfolgend präsentierte Entwicklungsprozess ist ein Prozess, in dem inkrementell ein Softwareprodukt entwickelt wird. Die Darstellung konzentriert sich dabei auf den Prozess und die Prozessbeteiligten. Die Behandlung der Frage, wie und woraus Security-Anforderungen abgeleitet werden und wie aus den genannten Privacy-Strategien Privacy-Anforderungen abgeleitet werden, würde den Rahmen sprengen. Zu dieser Frage sei auf andere Publikationen verwiesen.12 Zu betonen ist auch, dass Privacy und Security by Design nur dann effektiv umgesetzt werden kann, wenn es bereits beim Entwurf der Softwarearchitektur berücksichtigt wird.
3.
Konzept eines iterativen Privacy und Security by Design-Entwicklungsprozesses ^
Scrum sieht keine standardisierte Methode vor, um Privacy- und Security-Anforderungen umzusetzen. Abbildung 1 zeigt unseren Prozess, der mittels Scrum definiert wurde, und in welchen Phasen welche Maßnahmen gesetzt werden, um diese Anforderungen dennoch zu berücksichtigen. Die Entwicklung erfolgt in einer Anzahl (je nach Bedarf) an Iterationen – auch als Sprints bezeichnet – mit der Dauer von 2-3 Wochen. Das Ergebnis eines jeden Sprints ist jeweils ein um Funktionalität erweitertes, lauffähiges und getestetes Produkt (oder Inkrement). Innerhalb eines Sprints werden die Scrum-typischen Phasen durchlaufen. Zusätzlich gibt es ein Backlog Refinement Meeting (oder auch als Backlog Grooming bezeichnet)13 vor dem ersten Sprint Planning und später jeweils optional während der Sprints. Zusätzlich gibt es dedizierte Privacy- und Security-Sprints, die sich besonders intensiv mit der Umsetzung von Privacy und Security beschäftigen. Diese können auch unter Zuhilfenahme spezieller Privacy- und Security-Teams erfolgen. Ein zentrales Security-Team sieht auch Kumar14 vor.
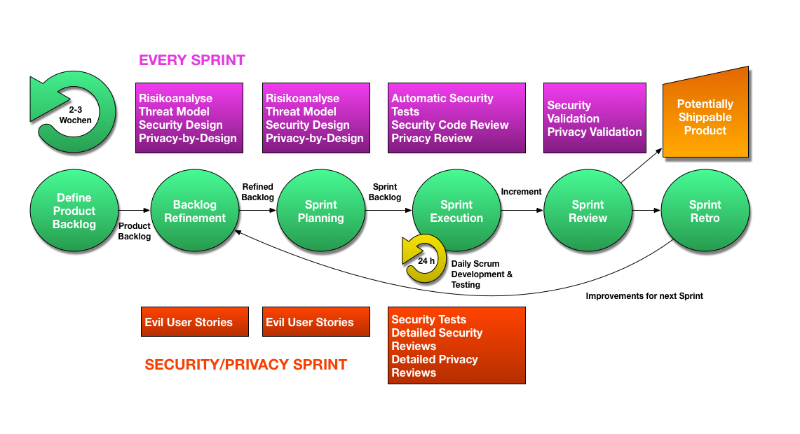
3.1.
Zielsetzung ^
3.2.1.
Abbilden von Privacy- und Security-Anforderungen im Product Backlog ^
Die Definition of Done (DoD)19 ist eine Checkliste, die festlegt, welche Eigenschaften eine User Story erfüllen muss, um sie als abgeschlossen anzusehen. Sie wird vom Entwicklungsteam gemeinsam mit den PO erarbeitet und ist einem stetigen Änderungsprozess unterworfen. Hat die nicht-funktionale Anforderung globale Relevanz, kann sie in die DoD mitaufgenommen werden – z.B. Persönliche Daten eines Nutzers dürfen von anderen Benutzern nicht eingesehen werden. So wird gewährleistet, dass die Anforderung später nicht gebrochen wird.
3.2.2.
User Stories aus Sicht eines Angreifers ^
3.2.3.
Statische Code-Analyse ^
3.2.4.
Automatische Privacy- und Security-Tests ^
So weit als möglich werden auch Privacy- und Security-Tests durch den Einsatz entsprechender Scanner und Fuzzer automatisiert – z.B. Prüfen auf Anfälligkeit gegenüber Cross Site Scripting (XSS).
3.2.5.
Inkrementelle Privacy- und Security-Reviews ^
3.3.
Zusätzliche Rollen ^
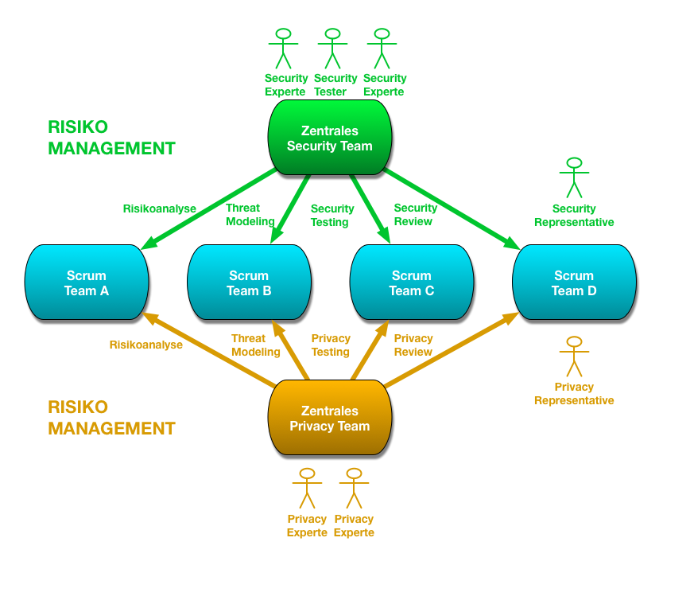
- Security-Experten und Tester: Als Mitglieder des Security Teams leisten sie Hilfestellung oder übernehmen Aufgaben im Bereich Security (z.B. Risikoanalyse, Threat Modeling, Security Testing, Code Reviews mit Fokus auf Security und Secure Coding).
- Privacy-Experten: Als Mitglieder des Privacy Teams kümmern sie sich um die Themen Datenschutz, Datensicherheit und Privatsphäreschutz. Sie unterstützen das Entwicklungsteam im Bereich Privacy (z.B. Risikoanalyse, Threat Modeling, Privacy Testing, Privacy Reviews).
4.
Diskussion und erste Erfahrungen aus dem Projekt ePartizipation ^
Im Projekt ePartizipation wird der soeben beschriebene Prozess angewandt, allerdings in einer vereinfachten Form, da sowohl das Team als auch die zu entwickelnde Software verhältnismäßig klein sind. Die Entwicklung läuft erst seit wenigen Monaten, doch bisher erweist sich der Prozess als praxistauglich und gut umsetzbar. Privacy- und Security-relevante (technische) User Stories finden ihren Weg in das Product Backlog. Deren Aufwand wird gemeinsam im Sprint Planning mit klassischen User Stories in Story Points geschätzt. Dies erhöht objektiv automatisch die Vergleich- und Priorisierbarkeit bei gleichzeitiger zunehmender Sensibilisierung des Entwicklungsteams für Privacy und Security. Letzteres wird vor allem deutlich durch viele einschlägige Rückfragen des Entwicklungsteams an die Representatives während der Sprint Plannings und Backlog Refinement Meetings. Als Konsequenz zeigt sich, dass während der Daily Scrums die Anwesenheit der Representatives nicht immer erforderlich ist. Dies wird vor allem in regulären Sprints so gelebt. In Privacy- und Security Sprints ist eine ständige Koordination zwischen den Representatives bzw. den externen Teams und dem Entwicklungsteam durch die Daily Scrums weiterhin notwendig.
Obwohl die Existenz mehrerer PO als potenzielles Problem identifiziert wurde, zeigt sich kein Interessenkonflikt zwischen den Representatives, die formal die Rolle eines PO bekleiden, und dem traditionellen PO. Um Konflikte zu vermeiden, wäre es allerdings denkbar, die Representatives lediglich als Stakeholder mit besonderen Pflichten und nicht als PO einzustufen.
5.
Danksagung ^
- 1 Vgl. Schwaber/Sutherland, The Scrum Guide, http://www.scrumguides.org/docs/scrumguide/v1/Scrum-Guide-US.pdf (aufgerufen am 7. Januar 2016), 2013.
- 2 Europäische Kommission, Eine Digitale Agenda für Europa, KOM(2010)245 endg., 19. Mai 2010, S. 20.
- 3 Art. 23 des finalen Kompromisstexts der DSGVO, http://www.statewatch.org/news/2015/dec/eu-council-dp-reg-draft-final-compromise-15039-15.pdf (abgerufen am 10. Januar 2016).
- 4 So Art. 12 Abs. 3 lit c eIDAS-VO (Verordnung (EU) Nr. 910/2014 des Europäischen Parlaments und des Rates vom 23. Juli 2014 über elektronische Identifizierung und Vertrauensdienste für elektronische Transaktionen im Binnenmarkt und zur Aufhebung der Richtlinie 1999/93/EG, ABl. L 247, 73 vom 28. August 2014), Vergleich der deutschen mit der englischen Fassung.
- 5 So der deutsche Titel von Art 23 des Entwurfs der DSGVO (Vorschlag für VERORDNUNG DES EUROPÄISCHEN PARLAMENTS UND DES RATES zum Schutz natürlicher Personen bei der Verarbeitung personenbezogener Daten und zum freien Datenverkehr (Datenschutz-Grundverordnung), KOM (2012) 11 endg., 25. Januar 2012).
- 6 Cavoukian, Privacy by Design: The 7 Foundational Principles, http://www.privacybydesign.ca/content/uploads/2009/08/7foundationalprinciples.pdf (aufgerufen am 3. Juni 2015), 2009, Hervorhebungen im Original.
- 7 Vgl. ENISA, Privacy and Data Protection by Design – from policy to engineering, https://www.enisa.europa.eu/activities/identity-and-trust/library/deliverables/privacy-and-data-protection-by-design/at_download/fullReport (abgerufen am 6. August 2015), 2014, S. 2.
- 8 Z.B. die soeben zitierte sowie Gürses/Troncoso/Diaz, Engineering Privacy by Design, Computers, Privacy & Data Protection (CPDP 2011), 2011; van Rest/Boonstra/Everts/van Rijn/van Paassen, Designing Privacy-by-Design. In: Preneel/Ikonomou (Hrsg.), Proceedings of the First Annual Privacy Forum, APF 2012, Lecture Notes in Computer Science, Springer, Berlin und Heidelberg 2014, S. 55–72; Deng/Wuyts/Scandariato/Preneel/Joosen, A privacy threat analysis framework: Supporting the elicitation and fulfillment of privacy requirements, Requirements Engineering 2011, S. 3–32; Kung, PEARs: Privacy Enhancing ARchitectures, Proceedings of the Second Annual Privacy Forum APF 2014, Lecture Notes in Computer Science, Springer, Berlin und Heidelberg 2014, S.18–29; Spiekermann/Cranor, Engineering Privacy, IEEE Transactions on Software Engineering 2009, S. 67–82 u.a.ADDIN CSL_CITATION { "citationItems" : [ { "id" : "ITEM-1", "itemData" : { "DOI" : "10.1007/978-3-642-54069-1_4", "ISBN" : "978-3-642-54068-4", "author" : [ { "dropping-particle" : "", "family" : "Rest", "given" : "Jeroen", "non-dropping-particle" : "van", "parse-names" : false, "suffix" : "" }, { "dropping-particle" : "", "family" : "Boonstra", "given" : "Daniel", "non-dropping-particle" : "", "parse-names" : false, "suffix" : "" }, { "dropping-particle" : "", "family" : "Everts", "given" : "Maarten", "non-dropping-particle" : "", "parse-names" : false, "suffix" : "" }, { "dropping-particle" : "", "family" : "Rijn", "given" : "Martin", "non-dropping-particle" : "van", "parse-names" : false, "suffix" : "" }, { "dropping-particle" : "", "family" : "Paassen", "given" : "Ron", "non-dropping-particle" : "van", "parse-names" : false, "suffix" : "" } ], "container-title" : "First Annual Privacy Forum, APF 2012, Lecture Notes in Computer Science", "editor" : [ { "dropping-particle" : "", "family" : "Preneel", "given" : "Bart", "non-dropping-particle" : "", "parse-names" : false, "suffix" : "" }, { "dropping-particle" : "", "family" : "Ikonomou", "given" : "Demosthenes", "non-dropping-particle" : "", "parse-names" : false, "suffix" : "" } ], "id" : "ITEM-1", "issue" : "8319", "issued" : { "date-parts" : [ [ "2014" ] ] }, "page" : "55-72", "publisher" : "Springer", "publisher-place" : "Berlin, Heidelberg", "title" : "Designing Privacy-by-Design", "type" : "paper-conference" }, "uris" : [ "http://www.mendeley.com/documents/?uuid=902060f3-98a2-4f1e-8a21-d92d12059d26" ] } ], "mendeley" : { "formattedCitation" : "Jeroen van Rest/Daniel Boonstra/Maarten Everts/Martin van Rijn/Ron van Paassen, Designing Privacy-by-Design (2014)," }, "properties" : { "noteIndex" : 0 }, "schema" : "https://github.com/citation-style-language/schema/raw/master/csl-citation.json" }
- 9 Hoepman, Privacy Design Strategies, ICT Systems Security and Privacy Protection, IFIP Advances in Information and Communication Technology 428, 2014, S. 446.
- 10 ENISA, Privacy and Data Protection by Design – from policy to engineering, S. 18 ff.
- 11 Vgl. Waidner/Backes/Müller-Quade, Entwicklung sicherer Software durch Security by Design, Fraunhofer SIT, https://www.kastel.kit.edu/downloads/Entwicklung_sicherer_Software_durch_Security_by_Design.pdf (aufgerufen am 10. Januar 2016), 2013.
- 12 Z.B. PRIPARE, Deliverable D1.2 Privacy and Security-by-design Methodology, v1.04, Draft, 2014 http://pripareproject.eu/wp-content/uploads/2013/11/PRIPARE_Deliverable_D1.2_draft.pdf (aufgerufen am 10. Januar 2016), liegt noch nicht in einer finalen Version vor; Hörbe/Hötzendorfer, Privacy by Design in Federated Identity Management, Proceedings of the 2015 IEEE Security and Privacy Workshops, 2015, S. 167–174.
- 13 Vgl. Cohn, Product Backlog Refinement (Grooming), https://www.mountaingoatsoftware.com/blog/product-backlog-refinement-grooming (aufgerufen am 8. Januar 2016), 2015.
- 14 Kumar, How to address Application Security in agile Scrum Teams?, http://vitalflux.com/how-to-address-application-security-in-agile-scrum-teams/ (aufgerufen am 8. Januar 2016), 2013.
- 15 Vgl. Cohn, User Stories Applied: For Agile Software Development, Addison-Wesley Professional, Boston und andere 2004.
- 16 Vgl. Bradley, Story Testing Patterns, http://www.scrumcrazy.com/Story+Testing+Patterns (aufgerufen am 6. September 2015), 2013.
- 17 Vgl. Ambler, Beyond Functional Requirements On Agile Projects, http://www.drdobbs.com/architecture-and-design/beyond-functional-requirements-on-agile/210601918 (aufgerufen am 6. September 2015), 2008.
- 18 SAFECode, Practical Security Stories and Security Tasks for Agile Development Environments, http://www.safecode.org/publication/SAFECode_Agile_Dev_Security0712.pdf (aufgerufen am 6. September 2015), 2012.
- 19 Vgl. Agile Alliance, Definition of Done, http://guide.agilealliance.org/guide/definition-of-done.html (aufgerufen am 6. September 2015), 2013.
- 20 Vgl. OWASP, Agile Software Development: Don’t forget EVIL User Stories, https://www.owasp.org/index.php/Agile_Software_Development:_Don%27t_Forget_EVIL_User_Stories (aufgerufen am 6. September 2015), 2011.
- 21 Vgl. McGraw, Misuse and Abuse Cases: Getting Past the Positive, IEEE Security & Privacy, Volume 2, Issue 3, 2004, S. 90–92.





