1.
Introduction ^
Nowadays, many sectors face the obstacle called digitalization, and so does the legal domain. When talking about digitalization, one must distinguish between unstructured, semi-structured and structured data. In terms of digitizing texts these distinctions must be considered as well [Hashimi 2015]. Structured data can be processed easily and is the simplest way to manage information. However, semi-structured and in particular unstructured data is hard to process. Hence, transforming unstructured or semi-structured data into structured data is an important task in order to manage and process information [Svyatkovskiy et al. 2016].
The rise of legal technology is highlighted by the increasing number of digitized legal documents, in particular legal contracts [Saravanan et al. 2009]. After capturing these, in many cases they are only available as unstructured or semi-structured data and thus barely processable by computer systems. However, the semantic knowledge within such a document is highly relevant to the reader. Considerable added value can be created when modelling and structuring these digitized legal documents properly [Walter 2009]. This is in particular also true due to the fact that lawyers and legal experts use frequently different ways of expression. Having two lawyers creating two contracts with the same intent, the result is most likely two different contracts. Furthermore, legal contracts include a lot of information which is not highly relevant to the reader [Hashimi 2015]. When there is a structured way of revealing the crucial information while neglecting superfluous passages of text of such a document, the resulting view would be the same. This is the main motivation behind this work.
2.
Related Work ^
There has been considerable work on NER, in particular for the English language [Sang/de Meulder 2003]. Jurafsky summarizes much of this research in his book Speech & Language processing [Jurafsky 2007, p. 349 ff.]. Borthwick [Borthwick/Grisham 1999] gives a good overview about the research in this field. When recognizing named entities (NEs), we distinguish between distinct categories. The literature as well as various shared tasks suggest different categorizations. Borthwick [Borthwick/Grisham 1999] for instance, uses the following categories in his work: person, location, organization, date, time, percentage, monetary value, and «non-of-the-above». The CoNLL-2003 shared task suggests to use just three, respectively four, categories: person, location, organization, and «other» [Sang/de Meulder 2003]. Such a categorization of NE types often depends on the domain. For this work, the suggestion from CoNLL-2003 was adopted, enhanced by some of the categories from the literature. This led to the following set of categories: person, organization, location, date, money value, reference, and «other».
NED is defined as the process of linking a NE to an entry in some resource, which is the correct one for the context of occurrence [Bunesca/Pasca 2006]. When we talk about linking or disambiguating NEs, the literature often uses the term named entity linking (NEL) or NED for that task. In this work, the term NED is used in order to describe the task of linking a NE to a semantic function or role. Manning dedicates a whole chapter in his book Statistical NLP [Manning 1999, p. 229 ff.] to the linking of words to senses. He suggests different techniques for word sense disambiguation (WSD): supervised disambiguation, unsupervised disambiguation as well as a dictionary-based disambiguation. The same suggestions are made by Jurafsky in his book Speech & Language Processing [Jurafsky 2000]. By applying small changes, those approaches may be feasible to NED as well.
3.
Conceptual Overview ^
In order to achieve the goal of semantically analyzing and structuring legal contracts, a process consisting of NER and NED was defined. This concept serves as a reference for the actual implementation. For the explanation of this concept, the example of an employment agreement is taken. The first step towards the extraction of semantic knowledge is the application of NER. The goal of this step is to extract all NEs in the agreement. The result of this task is illustrated in the left column of Figure 3.1.
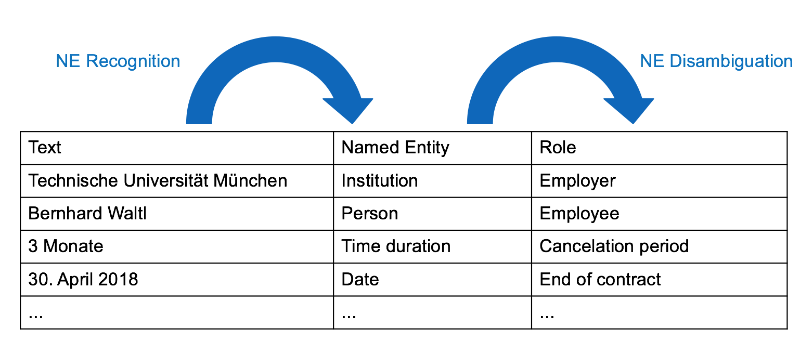
Figure 3.1: Conceptual overview of the recognition and disambiguation process
Once the NEs are recognized, the actual disambiguation can take place. Each contract needs to be modeled. For that reason, the prototypical implementation allows the definition of such a semantic model. For the sake of this example, a model with roles like Employer, Employee, Cancellation period and End of contract is assumed. Figure 3.1 includes both steps of the NER and NED process. The phrase «Technische Universität München» is recognized and classified as an organization in the first step. During the second step, the NE is linked to the respective role Employer. This is the basic concept behind the software component, being implemented in the course of this paper. Figure 3.2 depicts the described concept within a conceptual software architecture. It reflects the basic architecture of the semantic analysis component. The Semantic Analysis Component consists of two sub components, that is: (1) the Named Entity Recognition Component, and (2) the Named Entity Disambiguation Component. The former gets a Contract as input and performs NER on it. Optionally for the templated NER, it involves a Template, too. This results in an Annotated Contract. This Annotated Contract is forwarded to the disambiguation component. Depending on the approach, a Template, external resources such as knowledge bases as well as artificial intelligence (AI) is used to create the Structured Contract. The three implemented approaches of this work are discussed in Section 4.
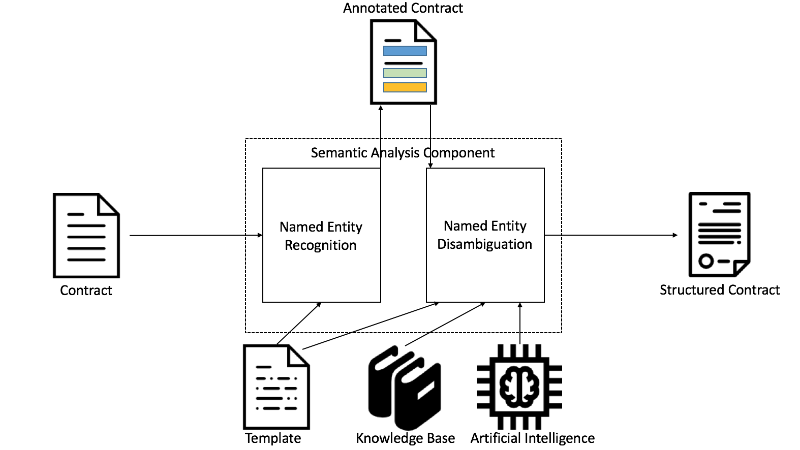
Figure 3.2: Conceptual architecture of the semantic analysis component
4.
Recognizing Named Entities and Linking towards Semantic Models ^
The prototypical implementation has been done in an existing legal data science environment that allows the collaboration on legal documents. The environment is a web application implemented with a Java back-end. Apache UIMA, developed by IBM and also used in IBM Watson, conduces as a reference architecture. The Apache UIMA utilizes the use of pipelines to process legal texts. This is achieved by a state-of-the-art pipes & filters architecture. Such a pipeline allows the incorporation of various NLP tasks, by implementing Apache UIMA components. The different steps such as tokenization, sentence splitting, or part-of-speech (POS) tagging are executed subsequently. This way, the pipeline is executed on a legal text. The processing results are stored in UIMA common analysis system (CAS) objects for further processing. More details on the data science environment, the different components and the base line architecture to perform computational intensive data analysis processes on large text corpora can be found in [Waltl et al. 2016].
4.1.
Named Entity Recognition Pipelines ^
4.1.1.
GermaNER ^
GermaNER only accepts the CoNLL-2013 format as input. Such a file contains one token per line, while sentence should be separated by a blank line. The output of the tagger is a tab separated file. The first column corresponds to the same as in the input file. In the second column, the predicted NE tag is stored in form of the beginning-inside-outside (BIO) scheme. The BIO-scheme suggest to learn classifiers that identify the beginning, the inside and the outside of the text segments [Ratinov/Roth 2009]. Our system however holds legal documents at html-formatted texts. For that reason, our pipeline first removes the html tags before we perform tokenization and sentence splitting. Eventually, a specific transformer creates a CoNLL representation of the actual legal document. All this information is stored in a CAS object and forwarded through the pipeline. Eventually the GermaNER component tries to identify the NEs. While GermaNER is responsible for the extraction of persons, organizations, locations and others, rule-based approaches are applied to the other types. We have used regex rules to identify dates and money values. The work from Landthaler et al. [Landthaler et al. 2016] was used to identify references. Since GermaNER uses its own type system, the recognized NEs are transformed into our own type system within Lexia. This step allows us to further process the recognized NEs. Afterwards, the pipeline finishes with a post-processing, in order to enrich the html representation with the gained information.
4.1.2.
DBpedia Spotlight ^
DBpedia is an interlinking hub in the web of data, enabling access to many data sources in the linked open data cloud [Mendes et al. 2011]. DBpedia contains about 3.5 million resources from Wikipedia. The ontology is populated with classes such as places, persons or organizations. Furthermore, fine-grained classifications like soccer players or IT companies are existing. Resources possess attributes as well as relations to each other [Daiber et al. 2013]. Mendes et al. [Mendes et al. 2011] developed DBpedia Spotlight Annotator to enable the linkage of web documents with that hub. It is a system to perform annotation tasks on text fragments, such as documents, paragraphs or sentences, provided by a user. Hereby, the user wishes to identify URIs for resources mentioned within that text. This can be seen as a typical NER system.
From a technical point of view, the integration of the DBpedia Spotlight UIMA component has been done in the same fashion as the GermaNER component. Our pipeline performs html stripping in order to feed plain text to the DBpedia Spotlight UIMA component. After the NE extraction, the component described in the previous section for post-processing is reused, as well as the type system transformation.
4.1.3.
Templated Named Entity Recognition ^
The intuition behind this templated NER approach is that if we compare an actual contract with its template, only the populated information remains as differences. When thinking about relevant information in a contract, mostly NEs emerge. With other words, when a contract template is filled in the majority of information are NEs. Of course, this method basically just picks off the low hanging fruits, nonetheless it is a valid NER system for that specific kind of contracts.

Figure 4.1: Example sentence from a template
A possible example of a sentence from such a template is shown in Figure 4.1. For the placeholders, a concept has been used, where two dashes followed by some word ensued by another two dashes indicate a NE. With other words, the following regex highlights a placeholder «(–)*.(–)». During the contract creation process, such a template may be filled as follows.

Figure 4.2: Example sentence from an instantiated template
Figure 4.2 depicts an instantiated template. The goal of a templated NER approach is to extract the three NEs: (1) «12», (2) «MacBook Pros», and (3) «Apple». By comparing the template and the instance, it is shown that those three NEs are the only difference between the two sentences. That is already the concept behind templated NER, which is implemented in the course of this study. In order to implement it, Google’s diff-match-patch1 (DMP) algorithm is utilized. The algorithm is based on Myers’ diff algorithm [Myers 1986]. When executing the algorithm, only pairs of differences augmented by the diff-option (equal, insert, and delete) are returned. Due to this, no types can be extracted, but just the NEs. However, the next section deals with the NED, which actually goes even further as having a type system for NEs.
4.2.
Named Entity Disambiguation ^
As already mentioned in Section 2, legal data corpora are rare, in particular when talking about annotated data. In order to perform NED to link NEs towards semantic functions such as Employee, huge data sets are required. We have no access to such data yet. For that reason, we have not built a classifier for NED as of now. However, the templated NER approach from the previous section can be extended to perform NED.
5.1.
Evaluation Method ^
5.2.
Data Set ^
| NE Types | PER | ORG | LOC | DA | MV | REF | OTH | O |
| Count | 114 | 106 | 45 | 267 | 78 | 310 | 182 | 24’314 |
Table 5.1: Composition of the evaluation data set
| NE Types | PER | ORG | LOC | DA | MV | REF | OTH | O |
| Count | 14 | 8 | 23 | 38 | 23 | 25 | 46 | 7’614 |
Table 5.2: Composition of the evaluation data set for templated NER
5.3.
Assessment ^
5.3.1.
Which implemented NER pipeline performs best? ^
It is not common to compare three systems, whereas one of the systems was evaluated on a different evaluation data set. However, for this work it was not possible to evaluate all three approaches on the same data, as already mentioned in Section 5.2. Table 5.3 summarizes the results of this evaluation.
| System | Per-entity F1 | Overall | ||||||||
| PER | ORG | LOC | DA | MV | REF | OTH | P | R | F1 | |
| Templated | 0.88 | 0.77 | 0.82 | 0.86 | 0.88 | 0.93 | 0.71 | 0.94 | 0.91 | 0.92 |
| GermaNER | 0.35 | 0.71 | 0.45 | 0.91 | 0.89 | 0.91 | 0.33 | 0.98 | 0.68 | 0.80 |
| DBpedia | 0.51 | 0.76 | 0.52 | 0.91 | 0.86 | 0.91 | 0.59 | 0.87 | 0.87 | 0.87 |
Table 5.3: NER performance of all three systems over the evaluation data set
5.3.2.
Which NE type is recognized best? ^
5.3.3.
Which NE type is recognized worst? ^
The type other has in its nature that it not just comprises miscellaneous entities, it also often covers NE of other types, falling through their own classifiers. Moreover, there exist a huge variety of different NE types, excluding the set of categories used in this work. All those types shall be recognized by the other type. This may be feasible for a system such as DBpedia Spotlight, but statistical approaches, and even the templated NER approach, clearly fail to detect all NEs of such types.
6.1.
Conclusion ^
6.2.
Limitations and Future Work ^
The results of the GermaNER as well as the DBpedia Spotlight pipeline may not reflect their actual performance. The NE types, considered in this work are: person, organization, location, date, money value, reference, and other. Dates, money values and references were only detected using rule-based methodologies, but incorporated into both pipelines. This already refines the results. In addition, these two technologies were not used in isolation, but utilized by the prototypical implementation of this work. Hence, system errors are conveyed to the two tools.
7.
Literatur ^
Bender, Oliver/Och, Franz Josef/Ney, Herman, Maximum entropy models for named entity recognition, In Proceedings of the seventh conference on Natural language learning at HLT-NAACL, 2003, pp. 148–151.
Benikova, Darina/Biemann, Chris/Kisselew, Max/Padó, Sebastian, Germeval 2014 named entity recognition shared task: companion paper, Organization, 7:281, 2014.
Benikova, Darina/Muhe, Seid/Prabhakaran, Yimam/Biemann, Chris, Germaner: Free open german named entity recognition tool, In In: Proc. GSCL-2015, 2015.
Borthwick, Andrew/Grisham, Ralph, A maximum entropy approach to named entity recognition, PhD thesis, New York University, Graduate School of Arts and Science, 1999.
Bunesco, Razvan C./Pasca, Marius, Using encyclopedic knowledge for named entity disambiguation, In Eacl, 2006, pp. 9–16.
Chieu, Hai Leong/Ng, Heww Tou, Named entity recognition: a maximum entropy approach using global information, In Proceedings of the 19th international conference on Computational linguistics, 2002, pp. 1–7.
Collobert, Ronan/Weston, Jason/Bottou, Léon/Karlen, Michael/Kayukcuoglu, Koray/Kuksa, Pavel, Natural language processing (almost) from scratch, Journal of Machine Learning Research, August 2011, pp. 2493–2537.
Curran, James R./Clark, Stephen, Language independent ner using a maximum entropy tagger, In Proceedings of the seventh conference on Natural language learning at HLT-NAACL, 2003, pp. 164–167.
Cuceran, Silviu, Large-scale named entity disambiguation based on wikipedia data, 2007.
Daiber, Jocahim/Jakob, Max/Hokamp, Chris/Mendes, Pablo N., Improving efficiency and accuracy in multilingual entity extraction, In Proceedings of the 9th International Conference on Semantic Systems, 2013, pp. 121–124.
Dozier, Christopher/Kondadadi, Ravikumar/Light, Marc/Vaccher, Arun/Veeramachaneni, Sriharsha/Wudali, Ramdev, Named entity recognition and resolution in legal text, In Semantic Processing of Legal Texts, Springer, 2010, pp. 27–43.
Faruqui, Manaal/Padó, Sebastian, Training and evaluating a german named entity recognizer with semantic generalization, In KONVENS, 2010, pp. 129–133.
Ferucci, David/Lally, Adam, Uima: an architectural approach to unstructured information processing in the corporate research environment, Natural Language Engineering, 10(3-4), 2004, pp. 327–348.
Finkel, Jenny/Grenager, Trond/Manning, Christopher D., Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd annual meeting on association for computational linguistics, 2005, pp. 363–370.
Florian, Radu/Ittycheriah, Abe/Jing, Honguyan/Zhang, Tong, Named entity recognition through classifier combination, In Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003, pp. 168–171.
Hasmi, Mustafa, A methodology for extracting legal norms from regulatory documents, In Enterprise Distributed Object Computing Workshop (EDOCW), 2015, IEEE 19th International, pp. 41–50.
Jurafsky, Dan, Speech & language processing, Pearson Education, India, 2000.
Klein, Dan/Smarr, Joseph/Nguyen, Huy/Manning, Christopher D., Named entity recognition with character-level models, In Proceedings of the seventh conference on Natural language learning at HLT-NAACL, 2003, pp. 180–183.
Landthaler, Jörg/Waltl, Bernhard/Matthes, Florian, Unveiling References in Legal Texts: Implicit versus Explicit Network Structures, In Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016, Salzburg, Austria, 2016.
Manning, Christopher D./Schütze, Hinrich, Foundations of statistical natural language processing, 1999, MIT Press.
Mendes, Palo N./Jakob, Max/Garcia-Silva, Andrés/Bizer, Christian, Dbpedia spotlight: shedding light on the web of documents, In Proceedings of the 7th international conference on semantic systems, 2011, pp. 1–8.
Myers, Eugene W., An o (nd) difference algorithm and its variations, Algorithmica, 1(1), 1986, pp. 251–266.
Nadeau, David/Sekine, Satoshi, A survey of named entity recognition and classification, Lingvisticae Investigationes, 2007, 30(1), pp. 3–26.
Ratinov, Lev/Roth, Dan, Design challenges and misconceptions in named entity recognition, In Proceedings of the Thirteenth Conference on Computational Natural Language Learning, 2009, pp. 147–155.
Reimers, Nils/Eckle-Kohler, Judith/Schnober, Carsten/Kim, Jung/Gurevych, Iryna, Germeval-2014: Nested named entity recognition with neural networks, In Workshop Proceedings of the 12th Edition of the KONVENS Conference, 2014, pp. 117–120.
Sang, Erik F./Tjong, Kim/de Meulder, Fien, Introduction to the conll-2003 shared task: language-independent named entity recognition, In CONLL ‘03 Proceedings of the seventh conference on Natural language learning at HLT-NAACL, 2003, pp. 142–147.
Saravanan, M./Ravindran, B./Raman, S., Improving legal information retrieval using an ontological framework, Artificial Intelligence and Law, 2009, 17(2) pp. 101–124.
Svyatkovskiy, K./Imai, M./Kroeger, M./Shiraito, Y., Large-scale text processing pipeline with apache spark, In Big Data (Big Data), 2016, IEEE International Conference, pp. 3928–3935.
Walter, Stephan, Definition extraction from court decisions using computational linguistic technology, Formal Linguistics and Law, 2009, 212, pp. 183.
Waltl, Bernhard/Mathhes, Florian/Waltl, Tobias/Grass, Thomas, LEXIA: A data science environment for Semantic analysis of german legal texts, In Netzwerke / Networks, Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016, Wien/Bern, Austria, 2016.
Waltl, Bernhard/Landthaler, Jörg/Scepankova, Elena/Matthes, Florian/Geiger, Thomas/Stocker, Christoph/Schneider, Christian, Automated extraction of semantic information from german legal documents, In Trends und Communities der Rechtsinformatik / Trends and Communities of Legal Informatics, Tagungsband des 20. Internationalen Rechtsinformatik Symposions IRIS 2017, Salzburg, Austria, 2017.
- 1 http://code.google.com/archive/p/google-diff-match-patch (all websites last visited in January 2018).
- 2 http://www.rechtsprechung-im-internet.de.





