1.
Aufbau der Analysesoftware ^
Hilfreich sind dazu insbesondere folgende Software-Drittbibliotheken:
- «Apache Tika»1, um aus den verschiedenen Dateiformaten wie PDF mit hinterlegter Schrift, einfachen Textdateien, oder formatierten Texten (rich text format) einen Text als Zeichenkette (String) zu erhalten.
- Für die Satzgrenzenerkennung kommt im ersten Schritt die Programmbibliothek «Apache Open NLP» zum Einsatz, die unter Verwendung von machine learning die Satzgrenzen zu erkennen versucht. Problematisch sind die vielen Abkürzungen in juristischen Texten, die zu falscher Satzgrenzenerkennung führten. Dieses Problem konnte weitgehend durch eine Abkürzungsliste behoben werden.
Danach werden die oben genannten Metainformationen wie unter anderem das zu erkennende Gericht, Aktenzeichen, Entscheidungsdatum und Entscheidungstyp hinzugefügt. Die Extraktion dieser Metadaten erfolgt mittels Beschreibung der Daten über sog. Reguläre Ausdrücke. Dies hat sich beim Entwickeln der Software als recht zuverlässig erwiesen. Problematisch erscheint, dass das Nachvollziehen, Testen und Validieren solcher Regulärer Ausdrücke schwierig ist.
Das dargestellte Vorgehen ermöglicht dann die weitergehende Analyse der Entscheidungen. So können beispielsweise Kookkurrenzen bei Rechtsnormverweisen4 zur Erstellung eines Gesetzesgraphen5 erfasst werden. Ferner können solche Sätze extrahiert werden, die abstrakt von dem Streit der zugrundeliegenden Entscheidung sind. Meist handelt es sich bei solchen abstrakten Sätzen um rechtliche Maßstäbe, welche die Anwendung des Rechts konkretisieren. Diese abstrakten Sätze sind oft das, was bei der Recherche von Gerichtsentscheidungen von Interesse ist. Insofern verspricht es großen Nutzen, diese Sätze zu extrahieren und stukturiert, beispielsweise in einer Datenbank, zu speichern. Andere Arbeiten haben sich im Schwerpunkt mit dem Extrahieren von Definitionen aus Entscheidungs- oder Gesetzestexten beschäftigt.6 Die Definitionen von Begriffen sind aber enger gefasst als allgemeine Ausführungen zum Recht oder zur Gesetzesanwendung.
2.
Verfahren zur Gewinnung rechtlicher Maßstäbe ^
Nicht alle Rechtsausführungen enthalten Zitate. Daher lässt sich das Verfahren vermutlich dadurch weiter verbessern, indem unter Einsatz von Text-Classifier weitere abstrakte Sätze identifiziert werden. Solche Verfahren des maschinellen Lernens benötigten üblicherweise Beispiele, in der Form von Text und Zuordnung (supervised machine leanring). Sätze mit Rechtsausführungen ohne Zitate dürften strukturähnlich zu denen mit einem Zitat sein, wenn der Text mit Zitat in der Klammer entfernt wird. Unter dieser Prämisse kann man die bereits erfassten Sätze als Trainingsdaten für Text-Classifier nutzen. Zusätzlich bieten sich noch die amtlichen Leitsätze der Bundesgerichte als Trainingsdaten an.7 Bei englischsprachigen Gerichtsentscheidungen lassen sich rechtliche Prinzipien von Tatsachen mithilfe solcher Verfahren abgrenzen.8 Auch (deutsche) Rechtsnormen lassen sich mit hoher Wahrscheinlichkeit in verschiedene Arten (wie Anspruch oder Einrede) richtig kategorisieren.9
Das aufgezeigte Verfahren grenzt sich von anderen Vorschlägen ab, die auf das Extrahieren von Definitionen für einzelne Tatbestandsmerkmale abzielen.10 In die gleiche Richtung wie das hier vorgestellte Verfahren geht die Arbeit von Carlson mit der LawProp11 Software, die jedoch auf die originale Belegstelle über Verweise und Textähnlichkeit in anderen Entscheidungen die Textstelle mit «legal propositions» in der zitierten Entscheidung finden kann. Dieses Vorgehen scheint ebenfalls auf deutsche Gerichtsentscheidungen übertragbar zu sein.
Urteile sind allerdings nach § 5 Abs. 1 UrhG als amtliche Entscheidungen gemeinfrei. Völlig unproblematisch ist es daher, wenn Rechtsausführungen von anderen Gerichten zitiert werden und durch die Software gesammelt werden. Gleiches gilt für amtliche Leitsätze, z.B. von der Dokumentationsstelle der Gerichte.12
Enthalten Gerichtsentscheidungen allerdings Zitate privater Werke, sind die zitierten Texte dadurch nicht (völlig) gemeinfrei. So bleiben diese im Rahmen der allgemeine Schranken im Original weiter geschützt. Dritten darf das Werk ohne Zustimmung des Urhebers bzw. Rechteinhabers nur im Kontext des amtlichen Werkes, ansonsten aber nur im Rahmen der sonstigen Schranken des Urheberrechts verwertet werden.13 Da die extrahierten Zitate den Kern der Entscheidungsbegründung betreffen, erfasst dies den Kerngehhalt des § 5 UrhG, nämlich das öffentliche Interesse der Bevölkerung an allgemeiner Kenntnisnahme. Daher ist es erforderlich, dass die Zitatstellen, wie durch das Gericht zitiert, gemeinfrei werden, solange der Bezug zum amtlichen Werk bestehen bleibt. Da die allgemeine Kenntnisnahme der Begründungen der Entscheidung sichergestellt sein soll, muss es daher ausreichen, wenn ein Link von der Rechtsausführung zu dem entsprechenden Urteil im Volltext führt.
3.1.
Als Annotation zum Gesetzestext ^
3.2.
Per Volltextsuche ^
Die nachfolgende Grafik zeigt eine entsprechende Word Erweiterung, die beim Markieren innerhalb des Dokumententextes einen Suchvorgangs von Sätzen mit rechtlichen Maßstäben im rechten Fenster auslöst. Die rechtlichen Maßstäbe können per Mausklick samt Zitat auf die Entscheidung in das Dokument des Nutzers übernommen werden.
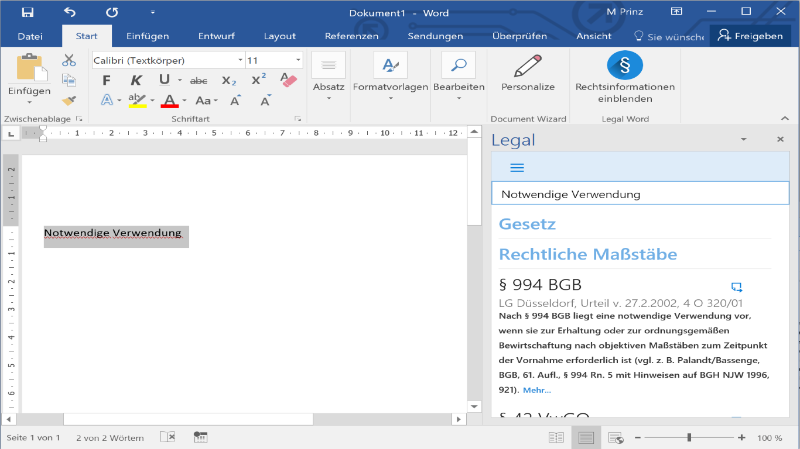
Abbildung 1: Word Add-In «Legal» mit rechtlichen Maßstäben.
3.3.
Per Annotation von Rechtsnormen untereinander ^
Bereitet man die Rechtsnormen grafisch als Netzwerk auf, so können auf Verbindungslinien zwischen Gesetzen solche Rechtsinformationen eingefügt werden, die entweder mindestens zwei Rechtsnormreferenzen enthalten oder die Rechtsnormen davor und danach im Entscheidungstext nennen. Dies bietet den Vorteil, dass sich die Verbindungen qualitativ beschreiben lassen. Beim Einarbeiten in neue Rechtsgebiete oder für eine Übersicht könnte ein solcher Gesetzesgraph einen zusätzlichen Rechercheeinstieg ermöglichen, insbesondere wenn die Rechtsinformationen wie Gesetze und rechtliche Maßstäbe beim Auswählen der Gesetze oder der Verbindung zwischen zwei Gesetzen angezeigt werden.
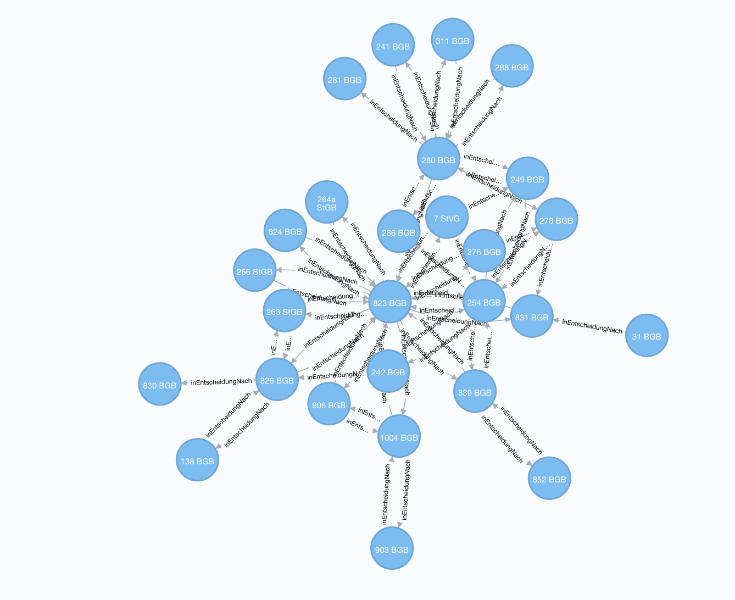
Abbildung 2: Gesetzesnetzwerk zu § 823 BGB. Verbindungen aus Kookkurrenzen von Gesetzesverweisen, gefiltert nach BGB, StGB und StVG und sortiert nach Verbindungsstärke.
4.
Verfügbare Gerichtsentscheidungen ^
Es wurden verschiedene Korpora von Gerichtsentscheidungen mit insgesamt knapp 300'000 Entscheidungen zusammengetragen. Die einzelnen Korpora stammen aus folgenden Quellen: Bundesgerichtshof (98'000 Entscheidungen), Bundesverfassungsgericht, Bundesarbeitsgericht, Bundesverwaltungsgericht, Bundessozialgericht, Bundespatentgericht, der online Rechtsprechungsdatenbank Bayern, der online Rechtsprechungsdatenbank NRW sowie Entscheidungen des Europäischen Gerichtshofs auf curia.europa.eu.
5.
Literatur ^
Carlson, James, LawProp, Using Quotations to Identify Legal Propositions in Judicial Opinions, Stanford University: CODEX: The Stanford Center for Legal Informatics, October 26, 2015.
Fromm, Axel/Nordemann, Jan Bernd (Hrsg.) Urheberrecht, 11. Auflage, 2013.
Landthaler, Jörg/Waltl, Bernhard/Matthes, Florian, Differentiation and Empirical Analysis of Reference Types in Legal Documents, in: Jusletter IT Flash 17. August 2017.
Shulayeva, Olga/Siddharthan, Advaith/Wyner, Adam, Recognizing cited facts and principles in legal judgements, Artificial Intelligence and Law, vol. 25, 2017.
Walter, Stephan, Definition extraction from court decisions using computational linguistics technology, Formal Linguistics and Law, vol. 212, 2009.
Waltl, Bernhard/Landthaler, Jörg/Scepankova, Elena/Matthes/Geiger/Stocker/Schneider, Automated
Waltl, Bernhard/Muhr, Johannes/Glaser, Ingo/Bonczek, Georg/Scepankova, Elena/Matthes, Florian, Classifying Legal Norms with Active Machine Learning, Jurix: International Conference on Legal Knowledge and Information Systems, Luxembourg, Luxembourg, 2017, S. 11–21.
- 1 https://tika.apache.org/ (alle Websites zuletzt abgerufen am 24. Januar 2018).
- 2 JSON steht für JavaScript Object Notation und wird oft beim Austausch von Daten zwischen Anwendungen genutzt.
- 3 https://github.com/google/gson.
- 4 Landthaler/Waltl/Matthes, Differentiation and Empirical Analysis of Reference Types in Legal Documents, in: Jusletter IT Flash 17. August 2017 beschreiben zutreffend, dass auch sog. stillschweigende Verweise (tacit references) wie Analogien im Gesetzestext durch die Analyse von Rechtsnormreferenzen in Gerichtsentscheidungen oder Sekundärliteratur erschlossen werden.
- 5 Bei Kookkurrenzen von Gesetzesverweisen innerhalb einer Entscheidung wird pauschal eine inhaltliche Beziehung unterstellt und eine Verbindung zwischen den Normen angelegt. Dies mag im Einzelfall nicht zutreffend sein. Erhöht sich das «Kantengewicht» mit zunehmender Anzahl der Kookkurrenzen von zwei Rechtsnormen und filtert die Verbindungen mit dem höchsten Verbindungsgewicht, so erscheinen aus dem Studium bekannte Verweisstrukturen, die sich aber selbst im Gesetzestext nicht wiederfinden (siehe Abb. 2).
- 6 Waltl/Landthaler/Scepankova/Matthes/Geiger/Stocker/Schneider 2017; Walter 2009.
- 7 Diese lassen sich aus den XML-Entscheidungsdateien von Rechtsprechung-im-Internet.de automatisch extrahieren.
- 8 Shulayeva/Siddharthan/Wyner 2017.
- 9 Waltl/Muhr/Glaser/Bonczek/Scepankova/Matthes 2017.
- 10 Walter 2009.
- 11 Carlson 2015.
- 12 Vgl. VGH Mannheim, Urteil vom 7. Mai 2013 – 10 S 281/12 = GRUR 2013, 821.
- 13 Nordemann, in Fromm/Nordemann 2014, zu § 5, Rn. 13.
- 14 Die Daten werden in die Datenbanken vom Typ MongoDB und Elasticsearch eingespielt.





