1.
Das Kriegsopferversorgungsgesetz im Überblick ^
Gemäß § 63 KOVG hat der Bundesminister für Arbeit und Soziales den für Leistungen nach dem Allgemeinen Sozialversicherungsgesetz vorgesehenen Anpassungsfaktor auch für die im Kriegsopferversorgungsgesetz vorgesehenen Leistungen für verbindlich zu erklären. Die im KOVG angeführten Beträge sind mit diesem Anpassungsfaktor zu vervielfachen und durch Verordnung des Bundesministers für Arbeit und Soziales festzustellen.12
2.
Software zur semi-automatischen Vollziehung des KOVG ^
2.1.
Die ontologische Unterstützung der Subsumtion ^
2.2.
Technische Aspekte ^
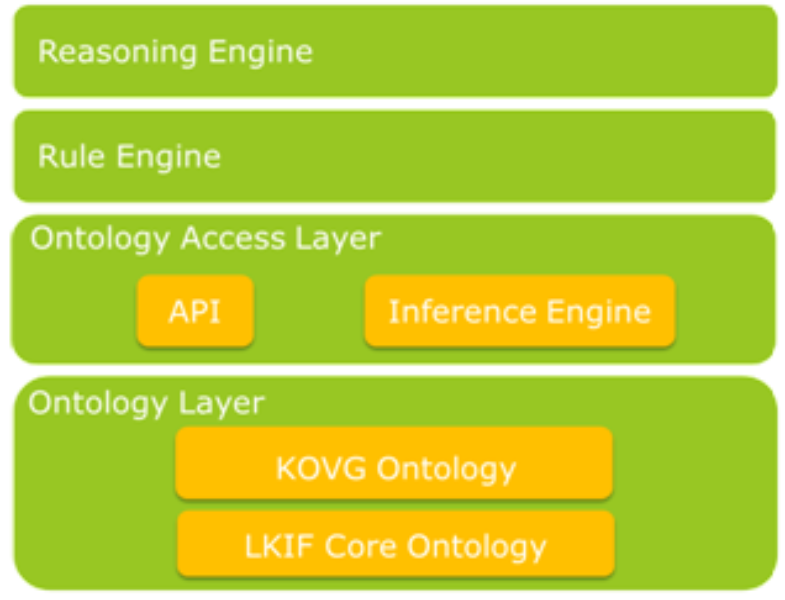
3.
Die Ontologie des Kriegsopferversorgungsgesetzes ^
- Welcher Personengruppe gehört der Antragsteller aufgrund der festgestellten Minderung der Erwerbsfähigkeit an?
- Welche Versorgungsleistungen gebühren dem Antragsteller?
- Wie lautet die Formel für die Berechnung der jeweiligen monetären Versorgungsleistung?

4.
Das Potential semi-automatischer Vollziehung ^
5.
Schlussfolgerungen ^
6.
Literatur ^
Sartor, G. (Hrsg.), Approaches to Legal Ontologies: Theories, Domains, Methodologies, Springer Netherlands (2011).
Schweighofer, E., An Ontological Representation of EU Consular Law. In: Francesconi, E., Montemagni, S., Rossi, P., Tiscornia, D. (Hrsg.), Proceedings of the 4th Workshop on Legal Ontologies and Artificial Intelligence Techniques 2010, Florenz, S. 77–86 (2010).
Hoekstra, R., Breuker, J., Di Bello, M., Boer, A., The LKIF Core Ontology of Basic Legal Concepts. In: Casanovas, P., Biasiotti, M., Francesconi, E., Sagri, M. (Hrsg.), Proceedings of the 2nd Workshop on Legal Ontologies and Artificial Intelligence Techniques 2007, Stanford, S. 43–63 (2007).
Gangemi, A., Design patterns for legal ontology construction. In: Casanovas, P., Biasiotti, M., Francesconi, E., Sagri, M. (Hrsg.), Proceedings of the 2nd Workshop on Legal Ontologies and Artificial Intelligence Techniques 2007, Stanford, S. 65–85 (2007).
Allemang, D., Hendler, J., Semantic Web for the Working Ontologist, Morgen Kaufmann, Burlington (2008).
Hitzler, P., Krötsch, M., Rudolph, S., Sure, Y., Semantic Web, Springer, Berlin/Heidelberg (2008).
Noy, N., McGuinness, D., Ontology Development 101: A Guide to Creating Your First Ontology. http://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html, aufgerufen: 1.1.2012.
Philipps, L., Anschauliche Normlogik. Zugleich eine Erinnerung an Bindings Normentheorie, in: Jusletter IT 5. Oktober 2011.
Bron, M., Eli-Ali, A., Ji, X., Klarman, S., Modeling Nomic in LKIF-Core Ontology., Leibniz Center for Law (2007).
- 1 BGBl. Nr. 152/1957.
- 2 § 1 Abs. 1 KOVG.
- 3 Vgl. § 1 Abs. 2 KOVG.
- 4 § 2 Abs. 2 KOVG.
- 5 § 6 KOVG.
- 6 §§ 7 ff. KOVG.
- 7 §§ 53 ff. KOVG.
- 8 Damit ist das heutige Bundesministerium für Arbeit, Soziales und Konsumentenschutz gemeint (2011).
- 9 §§ 7 ff. KOVG.
- 10 Verordnung des Bundesministeriums für soziale Verwaltung vom 9. Juni 1965 über die Richtsätze für die Einschätzung der Minderung der Erwerbsfähigkeit nach den Vorschriften des Kriegsopferversorgungsgesetzes 1957 (Minderung der Erwerbsfähigkeit) BGBl. Nr. 150/1965.
- 11 Vgl. §§ 11, 11a, 12, u.w. KOVG.
- 12 Verordnung des Bundesministers für Arbeit, Soziales und Konsumentenschutz über die Rentenanpassung sowie über die Feststellung bestimmter Werte im Versorgungsrecht für das Kalenderjahr 2011 BGBl. II Nr. 456/2010.
- 13 Vgl. §§ 73, 93 KOVG.
- 14 Bundeskanzleramt Österreich, Bürgerkarte. http://bka.gv.at/site/5268/default.aspx, aufgerufen: 11.12.2011.
- 15 Vgl. Wikipedia, Federated identity management. http://en.wikipedia.org/wiki/Federated_identity_management, aufgerufen: 11.12.2011.
- 16 „Beschädigte“, „Schwerbeschädigte“ usw.
- 17 Vgl. Bundeskanzleramt Österreich, Elektronische Zustellung. http://www.bka.gv.at/site/5532/default.aspx, aufgerufen: 23.12.2011.
- 18 § 77 KOVG.
- 19 Vgl. dazu insbes. § 12 Abs. 2 KOVG, der den Anspruch auf eine Zusatzrente von der Höhe des Einkommens des Antragstellers abhängig macht.
- 20 Darunter ist an dieser Stelle die eigentliche Ontologie samt der verwendeten Programmbibliothek für den Zugriff und die Inferenzmaschine zu verstehen.
- 21 Das Ergebnis der Operation.
- 22 Vgl. dazu insbes. § 16 Abs. 1 KOVG, der dem Antragsteller für jeden Familienangehörigen monatlich eine Familienzulage in doppelter Höhe der Zusatzrente gewährt.
- 23 Hoekstra, R., Breuker, J., Di Bello, M., Boer, A., The LKIF Core Ontology of Basic Legal Concepts. In: Casanovas, P., Biasiotti, M., Francesconi, E., Sagri, M. (Hrsg.), Proceedings of the 2nd Workshop on Legal Ontologies and Artificial Intelligence Techniques 2007, Stanford, S. 43–63 (2007).
- 24 Engl. Library.
- 25 The OWL API. http://owlapi.sourceforge.net/index.html. aufgerufen: 30.12.2011.
- 26 Jena – A Semantic Web Framework for Java. http://openjena.org/index.html, aufgerufen: 30.12.2011.
- 27 Darunter versteht man in der objektorientierten Programmierung Instanzen einer Klasse.
- 28 Bei monetären Versorgungsleistungen.
- 29 Vgl. Wikipedia, Domain ontologies and upper ontologies. http://en.wikipedia.org/wiki/Ontology_(information_science)#Domain_ontologies_and_upper_ontologies, aufgerufen: 1.1.2012.
- 30 Estrella, LKIF Core Ontology. http://www.estrellaproject.org/?page_id=,3 aufgerufen: 5.1.2012.
- 31 Noy, N., McGuinness, D., Ontology Development 101: A Guide to Creating Your First Ontology. http://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html, aufgerufen: 1.1.2012.
- 32 Engl. „Competency Questions“.
- 33 §§ 21 ff. KOVG.
- 34 §§ 23 ff. KOVG.
- 35 § 7 KOVG.
- 36 § 9 Abs. 2 KOVG.
- 37 Allemang, D., Hendler, J., Semantic Web for the Working Ontologist, Morgen Kaufmann, Burlington, S. 179 ff. (2008).
- 38 Mit Hilfe von „Properties“ werden in RDF Beziehungen zwischen Objekten ausgedrückt.
- 39 Evtl. kovg:enablesService.
- 40 Besser bekannt als „decision tree“ – vgl. Wikipedia, Decision tree. http://en.wikipedia.org/wiki/Decision_tree, aufgerufen: 5.1.2012.
- 41 Vgl. Bron, M., Eli-Ali, A., Ji, X., Klarman, S., Modeling Nomic in LKIF-Core Ontology., Leibniz Center for Law, S. 11 ff. (2007).
- 42 Vgl. Philipps, L., Anschauliche Normlogik. Zugleich eine Erinnerung an Bindings Normentheorie. In: Jusletter IT 5. Oktober 2011 Rz. 47 (2011).
- 43 Heeresversorgungsgesetz BGBl. Nr. 27/1964.
- 44 Bundespflegegeldgesetz BGBl. Nr. 110/1993.





