1.
Problemstellung ^
Richtlinie 93/109/EG des Rates vom 6. Dezember 1993 sieht vor, dass «Unionsbürger, die ihren Wohnsitz in einem Mitgliedstaat haben, dessen Staatsangehörigkeit sie nicht besitzen, dort das aktive und das passive Wahlrecht bei den Wahlen zum Europäischen Parlament ausüben können» (Art 1 Abs 1 rl cit1). «Jeder aktiv Wahlberechtigte der Gemeinschaft kann sein aktives Wahlrecht entweder im Wohnsitzmitgliedstaat oder im Herkunftsmitgliedstaat ausüben» (Art 4 Abs 1). Die doppelte Stimmabgabe (wie auch die doppelte Kandidatur) wird allerdings dabei ausgeschlossen. Die MS sorgen dafür, dass «die aktiv Wahlberechtigten der Gemeinschaft, die dies wünschen, rechtzeitig vor den Wahlen in das Wählerverzeichnis eingetragen werden können» (Art 9 Abs 1). Zu diesem Zwecke normiert Art 13, «[d]ie Mitgliedstaaten tauschen untereinander die Informationen aus, die für die Durchführung des Artikels 4 notwendig sind.» Zusätzlich existieren verschiedene Bestimmungen über den Verlust des aktiven oder passiven Wahlrechts bei zivil- oder strafrechtlichen Einzelfallentscheidungen (Art 6 und 7). Der in Art 13 eingeforderte Abgleich erfolgt bilateral und ex ante, also vor der Wahl und ergibt letztlich eine jeweils bilateral abgeglichene Wählerevidenz. Selbst unter Annahme einer einzigen Meldebehörde pro MS bedeutet dies (27*26)/2 = 351 bilaterale Abgleichsregime – dank der real existierenden dezentralen Meldebehörden in zahlreichen MS ergibt sich ein offenbar nicht mehr handhabbares Netzwerk bilateraler Abgleiche unter der mitgliedstaatlichen Ebene. Das in RL 93/109 eingeforderte Abgleichsregime kann daher durchaus als gescheitert bzw. nicht umgesetzt angesehen werden.2 Dies erscheint bedauerlich, da ein solcher Abgleich bspw. als Basis für die Europäische Bürgerinitiative EBI3 hätte verwendet werden können, womit die Abwicklungs- und Konsistenzprobleme vor allem des Annex III der Verordnung zur EBI vermieden würden.4
2.1.
Der Status quo ^
Die Masse der heute im Einsatz befindlichen Datenbanksysteme folgt dem relationalen Modell und hatn sich seit der Einführung dieses Modells durch Codd5 in den 70-er Jahren strukturell nicht wesentlich verändert:
- Daten werden logisch gesehen zeilenorientiert in Tabellen gespeichert, physisch hingegen als verkettete Werte pro Zeile gespeichert, siehe dazu Abbildung 1, die eine Verkettung über einen Delimiter «;» beispielhaft vorsieht, heute gebräuchlicher sind XML-Strukturen, was aber am Grundsatz der Zeilenorientierung in der Speicherung nichts ändert.
- Bestimmte Felder werden zu Schlüsselfeldern bzw. Indizes erklärt und für diese Suchstrukturen, beispielsweise Indexbäume, aufgebaut; über diese Indizes ist das rasche Durchsuchen auch größter Datenmengen möglich, das Suchen nach nichtindizierten Feldern oder Feldbruchstücken erfordert hingegen das sequenzielle Durchsuchen der gesamten Tabelle, was je nach Größe dieser Tabelle Suchzeiten von Stunden oder Tagen (sic) produzieren kann.
- Bestimmte, häufig verwendete Tabellen werden in den Hauptspeicher des Datenbankservers vorgeladen und stehen hier rasch zur Verfügung (s. zum Thema der Zugriffszeiten auch Abschnitt 2.3), die Masse der Daten ist aber auf einem permanenten Speichermedium, typischerweise einer Festplatte, untergebracht. Die Suchzeiten sind daher von den Zugriffszeiten auf dieses Festplattenmedium wesentlich beeinflusst und begrenzt.
- Diese Begrenzungen sind für viele operationale Anwendungen, wie etwa Systeme im Rechnungswesen, Produktion und Materialwirtschaft, Buchungssysteme, nicht entscheidend, da diese Verarbeitungen oft eine einzige Zeile einer Datenbanktabelle (z.B. einen Kunden oder einen Auftrag) betreffen, oder aber eine relativ kleine Anzahl von Sätzen, z.B. die für einen Fertigungsauftrag benötigten Materialien, die über Indexstrukturen (hier bspw. die Referenznummer zum Fertigungsauftrag) schnell herausgefunden werden können.
- Diese Begrenzungen sind aber entscheidend, wenn es um analytische Anwendungen geht, in denen die gesamte Datenbanktabelle durchsucht werden muss; Beispiel: um den durchschnittlichen Kundenauftragswert herauszufinden, muss einfach der gesamte Kundenauftragsbestand durchsucht werden. Daher wurden im analytischen Bereich mehrdimensionale Zwischenstrukturen, sog. «Data Cubes» geschaffen, die aus den Einzeldaten vordefinierte Aggregate bilden, die wiederum periodisch mit den neuen, aktuellen Einzeldaten fortgeschrieben werden; diese ermöglichen rasche analytische Zugriffe, sind aber im Einsatz schwerfällig, da jede Änderung des vordefinierten Aggregats den Neuaufbau des Data Cubes zur Folge hat.6
2.2.
Column Store ^

Abbildung 1: Row und Column Store am Beispiel von Kostenstellen
2.3.
In-Memory ^
Der rasche Fortschritt bei Speicherbausteinen verbunden mit den Möglichkeiten der Datenkompression durch Column Stores ermöglicht es mittlerweile auch, sehr große Datenbanken vollständig in den Hauptspeicher des Datenbankservers zu legen und damit alle sequenziellen Suchoperationen im Hauptspeicher durchzuführen. Dies führt zu einer Verbesserung der Suchzeiten um Größenordnungen: Zugriffszeiten auf Festplatten werden in Millisekunden (ms) angegeben8, Zugriffszeiten von Hauptspeicherbausteinen hingegen in Nanosekunden (ns)9 – dazwischen liegt der Faktor 10-6. Auch wenn die Zugriffszeit nicht der einzige Leistungsfaktor ist und die Unterschiede damit nicht linear auf die Gesamtleistung des Systems umgelegt werden können, so ergibt sich doch ein Unterschied um Größenordnungen.10
3.1.
Datenformat ^
Zunächst muss jede technisch administrierbare Lösung auf einem einheitlichen Datenformat aufbauen, das sowohl syntaktisch als auch semantisch eindeutige Definitionen der Feldinhalte bietet und von allen beteiligten Meldebehörden unterstützt wird. Eine Möglichkeit bietet die Election Markup Language EML11 in ihrer VoterInformation Struktur, die zur Bildung von Wählerevidenzen dienen soll. Hier müsste allerdings genauer die Datenbasis der 27 bzw. 28 MS der Union und dieses Datenformat analysiert werden, gegebenenfalls müsste eine Erweiterung des standardisierten EML-Formats stattfinden. Zusätzlich ist auch zu klären, wie Staaten ohne Meldewesen bzw. -pflicht mit diesem Datenaustausch umgehen können.
Weiters empfiehlt es sich, folgende Fragen der Namensübertragung zu lösen:
- Die Behandlung von Transliterationen aus dem Griechischen und Bulgarischen; so kann der Vorname Влади́мир sowohl mit «Vladimir» (im Englischen und Französischen üblich) als auch mit «Wladimir» (im Deutschen gebräuchlich) transliteriert werden;
- Die Behandlung diakritischer Zeichen; «Irina Zalisova» und «Irina Zálišová» mögen für einen menschlichen Benutzer dieselbe Person sein, für ein Datenverarbeitungssystem hingegen sind dies unterschiedliche Zeichenketten; die meisten europäischen Sprachen – inkl. des Deutschen – weisen diakritische Zeichen auf;
- Lokalisierte Vornamen wie bspw. «Karl Schwarzenberg» und «Karel Schwarzenberg»;
- Anführung und Schreibweise von Adelsprädikaten und Mittelnamen (z.B. die Frage, ob Edgar F. Codd und Edgar Codd dieselbe Person sind);
- Die Vereinheitlichung der Schreibweise akademischer Titel (z.B. vor- oder nachgestellt);
- Eine Regelung bezüglich umbenannter oder zusammengeführter Gemeindenamen (z.B. Karl-Marx-Stadt zu Chemnitz oder Gemeindezusammenlegungen in ländlichen Regionen) bei der Festlegung des Geburtsortes, dies auch für Geburtsorte außerhalb der EU (vgl. «Bombay» und «Mumbai»);
- Transliterations- und Transkriptionsregeln für Geburtsorte außerhalb der EU (z.B. «Београд», «Beograd», «Belgrad» und «Belgrade»).
3.2.
Zeitpunkt des Abgleichs ^
Zu diesem Zweck können die unabgeglichenen Evidenzen der einzelnen Meldebehörden in die Hauptspeicherdatenbank geladen werden. Dies überwindet sowohl das Problem des bilateralen wie auch des ex ante Abgleichs der Evidenzen. Dabei sind auch zeitliche Schiefstände möglich, was bedeutet, dass die beteiligten Meldebehörden bezüglich des Aktualisierungsintervalls bzw. -zeitpunkts frei sind. Wesentlich ist lediglich das gemeinsame Datenformat wie im letzten Abschnitt beschrieben. Da die Datenbestände dank In-Memory-Technik rasch auch sequenziell durchsucht werden können, ist es möglich, den Datenabgleich auf der Grundlage von unscharfem Schließen15 und im Vergleich von Nichtschlüsselattributen16 durchzuführen. Entscheidend ist in diesem Zusammenhang die Erstellung von Algorithmen für einen solchen Abgleich17, wobei diese erst bei Vorliegen einer konkreten Anfrage (on demand) ausgeführt werden.
3.3.
Procedere - Beispiel ^
Im Falle einer online anzugebenden Unterstützungserklärung zu einer EBI könnte ein solches Verfahren folgendermaßen aussehen:
- Eingabe des Landes, für das eine Unterstützungserklärung abgegeben werden soll, sowie der Staatsbürgerschaft/en;
- Eingabe der dem Annex III zu Verordnung 211/2011 entsprechenden persönlichen Daten in lateinischem, griechischem oder bulgarischem Zeichensatz, gegebenenfalls mit entsprechenden diakritischen Zeichen;
- Suche nach dem angegebenen Schlüsselattribut – wenn für das jeweilige Land lt. Annex III der VO (EU) 211/2011 anzugeben bzw. überhaupt vorhanden; Beispiele wären etwa für Österreich die Pass- bzw. Personalausweisnummer;
- Falls dies kein eindeutiges Resultat ergibt, unscharfe Suche nach Übereinstimmungen im jeweiligen Land;
- Suche, ob die betreffende Person in einem anderen EU-Land gemeldet ist, und Zusammenführen aller – wahrscheinlichen – Meldedaten der Person in der EU aus den einzelnen, unabgeglichenen Teilevidenzen im In-Memory-Datenbestand;
- Suche nach Duplikaten, d.h. mehrfach abgegebenen Unterstützungserklärungen (ggf. auch für andere MS) und automatische Vormerkung dieser Fälle für eine vertiefte Prüfung.
Bei den letzten Abgleichsschritten müssen die gefundenen Sätze grundsätzlich paarweise miteinander verglichen werden, also als Tupel (si, sj) der Satzmengen I und J, wobei es bei Verwendung probabilistischer Verfahren grundsätzlich zu zwei Arten von Fehlern kommen kann:
- Fehler erster Ordnung, wenn eine Identität fälschlicherweise angenommen wird («false positives»);
- Fehler zweiter Ordnung, wenn eine tatsächlich bestehende Identität nicht erkannt wird («false negatives»).
- Verfahren mit unscharfem Schließen bzw. probabilistische Verfahren müssen sinnvollerweise einen Cut-off-Punkt aufweisen, ab dem eine Annahme/Ablehnung der Identität zweier Datensätze erkannt wird, d.h.
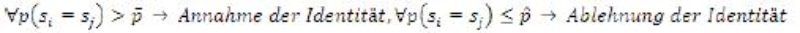
Wobei \(\bar{p}\) und \(\hat{p}\) die entsprechenden Wahrscheinlichkeitsschranken sind. Für alle \(\hat{p} < p \leq \bar{p}\) kann keine Aussage getroffen werden; diese Fälle müssen einer weiteren Behandlung unterzogen werden. Je stringenter nun die Konventionen sind, die dem Mapping zugrunde gelegt werden, umso besser können die Sätze voneinander abgegrenzt und umso besser die entsprechenden Wahrscheinlichkeiten gebildet werden – umso geringer wird also der Anteil der Sätze sein, die im undefinierten Zwischenbereich \(\hat{p} < p \leq \bar{p}\) zu liegen kommen.
4.
Forschungsbedarf ^
Bezüglich der genauen Ausgestaltung der Abgleichsalgorithmen und deren Validierung besteht konkreter Forschungsbedarf, die datentechnische Grundlage für ein derartiges System scheint aber jedenfalls gelegt. Der Geschwindigkeitsgewinn der In-Memory-Technik ermöglicht aber unter Umständen auch einen ex ante Abgleich; dieser muss allerdings paarweise sein und stellt damit ein quadratisches Problem dar: wenn beispielsweise die Datenbestände F und D miteinander abzugleichen sind, so ergibt dies n(F) x n(D) Abgleiche. Bestehen also die beiden Datenbestände beispielsweise aus 60m und 80m Datensätzen, so ergibt dies 4,8 x 1015 individuelle Abgleiche. Entsprechend verhält sich das Mengengerüst eines Abgleichs zwischen allen 27 Datenbeständen der MS ex ante. Hier wäre in einem Benchmark zu prüfen, wie sich aus dem Operations Research bekannte Optimierungsstrategien hier anwenden lassen und welches Laufzeitverhalten ein solcher, allenfalls optimierter, Abgleich in einem In-Memory-System zeigt.
Alle Webreferenzen wurden per 2.1.2013 geprüft.
Alexander Prosser, Professor, Wirtschaftsuniversität Wien, Department Informationsverarbeitung und Prozessmanagement.
- 1 Artikelreferenzen ohne Angabe der Rechtsquelle beziehen sich immer auf besagte Richtlinie.
- 2 Müller-Török/Stein, Die Europäische Bürgerinitiative aus Sicht nationaler Wahlbehörden; Verwaltung & Management 2010/5, S. 255-262 und Balthasar/Müller-Török, Ein Vorschlag zur Effektuierung der Richtlinie 93/109/EG, Tagungsband der IRIS 2011, 281-288 und die darin zitierte Literatur.
- 3 Verordnung (EU) Nr. 211/2011 des europäischen Parlaments und des Rates vom 16. Februar 2011; http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=OJ:L:2011:065:0001:0022:DE:PDF.
- 4 Vgl. Balthasar/Prosser, Die Europäische Bürgerinitiative - Gefährdung der Glaubwürdigkeit eines direkt-demokratischen Instruments? Journal für Rechtspolitik 18 (3), S. 122-132.
- 5 Codd, A Relational Model of Data for Large Shared Data Banks, Communications of the ACM 13(6), S. 377-398.
- 6 Prosser/Ossimitz, Data Warehouse Management Using SAP BW, UTB für Wissenschaft, Stuttgart, 2001.
- 7 Siehe die Benchmarks in Abadi/Madden/Hachem, Column Stores vs. Row Stores: How Different Are They Really? SIGMOD 2008, S. 967-980.
- 8 Hier zwei Beispiele handelsüblicher Systeme: http://www.seagate.com/files/docs/pdf/de-DE/datasheet/disc/ds-cheetah-15k-6-de.pdf, http://www.wdc.com/wdproducts/library/SpecSheet/DEU/2879-771442.pdf.
- 9 Hier wiederum zwei handelsübliche Beispiele: http://www.kingston.com/dataSheets/KVR13LR9D4_16HM.pdf, http://www.toshibadirect.com/td/b2c/adet.to?poid=515911.
- 10 Ein Rechenbeispiel mag dies veranschaulichen: Dauert ein sequenzieller Zugriff auf eine (große) Tabelle einen Tag, also 24x3600 Sekunden, so bedeutet eine Beschleunigung um den Faktor 106 eine Abarbeitung dieses Zugriffs in nicht einmal einer Zehntelsekunde. Damit werden auch größte Datenmengen für analytische Auswertungen zugänglich.
- 11 http://docs.oasis-open.org/election/eml/v7.0/cs01/eml-v7.0-cs01.pdf http://docs.oasis-open.org/election/eml/v7.0/cs01/Schemas/.
- 12 Hinrichs; Intelligente Datenbereinigung in epidemiologischen Registern, http://www.krebsregister-niedersachsen.de/registerstelle/dateien/BTW99.pdf.
- 13 Bereits Balthasar/Müller-Török weisen darauf hin, dass die RL 93/109 keine Fristen oder Zyklen für die Datenübertragung gemäß ihrem Art 13 einräumt (S. 305f).
- 14 Hierin unterscheidet sich der vorliegende Vorschlag grundsätzlich von dem, der von Balthasar/Müller-Török zum selben Problem gemacht wurde.
- 15 Vgl. Rodabaugh/Klement (Hrsg.): Topological and Algebraic Structures in Fuzzy Sets: A Handbook of Recent Developments in the Mathematics of Fuzzy Sets; Springer, 2003.
- 16 Brenner/Schmidtmann, Determinants of Homonym and Synonym Rates of Record Linkage in Disease Registration; Methods of Information in Medicine 35 (1), S. 19-24, http://www.schattauer.de/en/magazine/subject-areas/journals-a-z/methods/contents/archive/issue/special/manuscript/14145/download.html.
- 17 Blakely/Salmond, Probabilistic record linkage and a method to calculate the positive predictive value, International Journal of Epidemiology 31 (6), S. 1246–1252, http://ije.oxfordjournals.org/content/31/6/1246.full.





