I.
Einführung ^
- Höhere Qualität des Rechtstextes an sich durch das ermöglichte schnellere Aufdecken von Unvollständigkeiten und inneren Widersprüchen.
- Verbesserter Entwicklungsprozess des Rechtstextes in Hinsicht auf ein gemeinsames Verständnis und gemeinsame Begrifflichkeiten. Unterschiedliche Wissensstände der Beteiligten können durch gezielte Informationen ausgeglichen werden.
- Verbesserte Kommunikation. Worte haben häufig unterschiedliche Bedeutungen, was zu Missverständnissen und schlecht verständlichen Texten führen kann. Semantische Modelle hingegen erheben den Anspruch der Eindeutigkeit.
- Im Fall von Änderungen in den Rechtsnormen wird das Durchführen einer Wirkungsanalyse wesentlich vereinfacht und verbessert.
- Die Qualität von eventuellen auf Grund des Rechtstextes implementierten IT-Systemen wird durch eine direktere Informationsübermittlung verbessert.
II.
Verwandte Forschung ^
III.
Semantisches Grundmodell und Vorgehensmodell ^
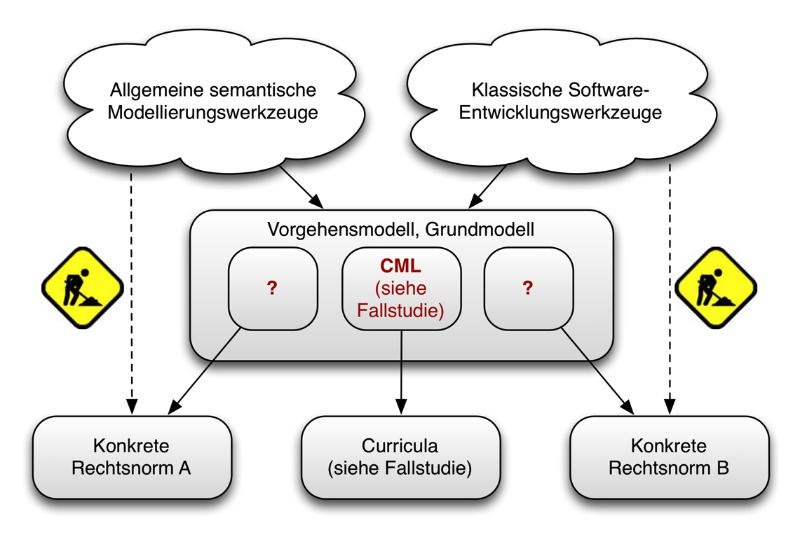
Abbildung 1: Forschungslücke
1.
Semantisches Grundmodell ^
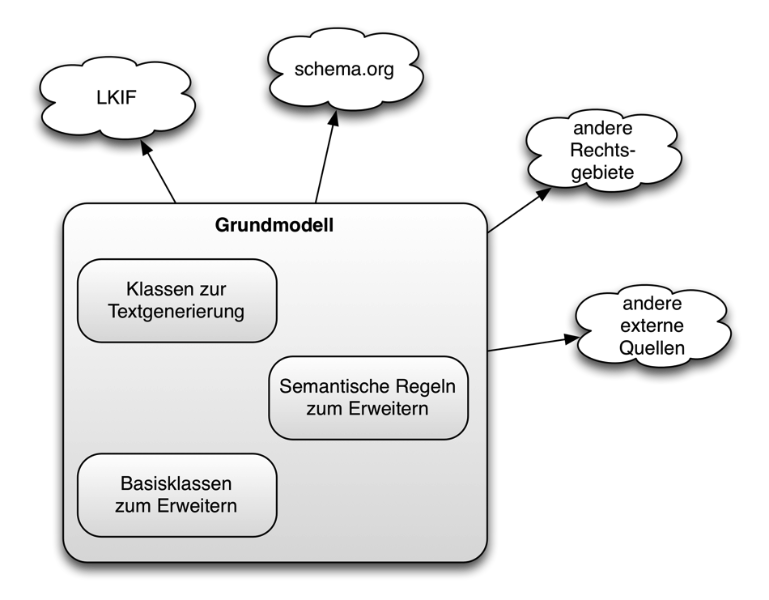
Abbildung 2: Semantisches Grundmodell
2.
Automatische Generierung von Rechtstext ^
Um dieses Ziel zu erreichen, wird im Grundmodell ein Satz von Basisklassen angeboten, die für eine große Bandbreite von Rechtsgebieten eingesetzt werden können. Im Wesentlichen bilden diese Klassen die grundlegenden Bausteine von Rechtstexten ab, wie beispielsweise Paragraphen, Absätze, Ziffern, Litera etc. und deren hierarchische Beziehungen zueinander. Gemeinsam mit einer zusätzlichen Helferklasse namens Inhalt sind sie alle Subklassen der Klasse Textbaustein, die die essentiellen Grundfunktionalitäten für Hierarchisierung, Ordnung und Organisation von Rechtstext bereit stellt. Diese Funktionalität wird mittels integrierten Metainformationen und Beziehungen zu anderen Textbausteinen modelliert.

Abbildung 3: Automatische Textgenerierung
StringBuffer sb = new StringBuffer();
Collections.sort(textbausteine);
for(Textbaustein b : textbausteine) {
sb.append(b.toString());
}
3.
Vorgehensmodell ^
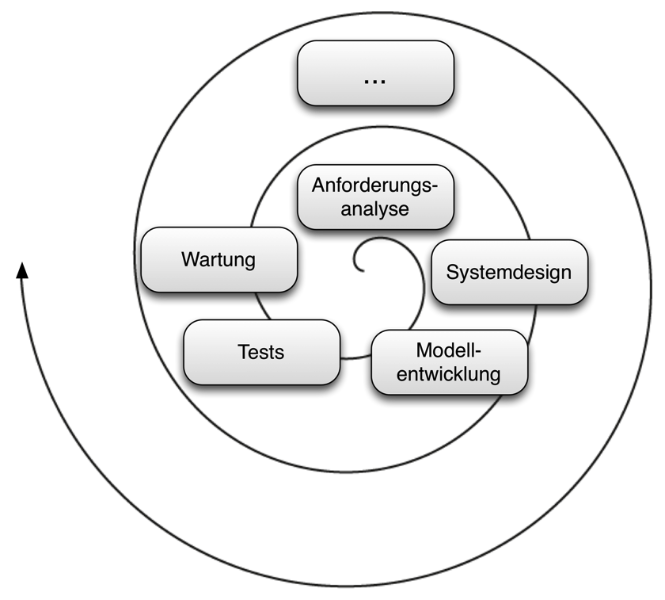
Abbildung 4: Vorgehensmodell
Abbildung 4 zeigt das Vorgehensmodell, das aus den folgenden Schritten besteht:
- Anforderungsanalyse
Im ersten Schritt müssen die Bedürfnisse und Anforderungen aller am Rechtssetzungsprozess Beteiligten erhoben und analysiert werden. Häufig sind mehrere Benutzergruppen mit unterschiedlichem technischen und juristischen Wissensstand involviert. Zur Strukturierung kann etwa folgende Vorgehensweise eingesetzt werden14:- Anforderungserhebung
- Anforderungsanalyse
- Anforderungsspezifikation
- Anforderungsbewertung
- Systemdesign
Der nächste Schritt beinhaltet das Design des Gesamtsystems und dient insbesondere der Komplexitätsreduktion und Minimierung von Risiken hinsichtlich Fehlentwicklungen. Beispielsweise sind hier folgende Fragen zu beantworten:- Soll das gesamte Rechtsgebiet oder nur bestimmte Teile modelliert werden?
- Wie soll die Struktur des Modells aussehen, wie werden einzelne Teilbereiche der Rechtsnorm abgebildet? Gibt es Beziehungen zu anderen Rechtsnormen und wie sollen sie ggf. modelliert werden?
- Gibt es externe Quellen wie etwa bereits modellierte Rechtsnormen, die wiederverwendet werden können?
- Welche semantische Sprachebene wird benutzt, welche Regelsprache, welche Programmiersprache? Welche Frameworks können verwendet werden?
- Braucht es eine oder ev. mehrere Benutzeroberflächen zur Unterstützung der Anwender?
- Modellentwicklung
Hier erfolgt die eigentliche Implementierung des semantischen Modells sowie eventueller Regelwerke und Benutzeroberflächen. Auf Basis des zuvor entwickelten Systemdesigns werden die ermittelten Anforderungen programmatisch umgesetzt. In dieser Phase sind die Unterschiede zwischen verschiedenen Rechtsgebieten am höchsten, dies liegt an höchst unterschiedlichen rechtlichen Voraussetzungen, externen Beziehungen und Strukturen. Nichtsdestotrotz versucht das Grundmodell, die unterschiedlichen Implementierungen zueinander kompatibel zu halten, indem gewisse Grundrichtlinien eingehalten werden müssen. - Tests
Als ein erster Test kann die Konkretisierung des Modells für eine spezifische Anwendung gesehen werden. Eine bestimmte Rechtsnorm wird mit Hilfe des eben entwickelten semantischen Modells abgebildet. Gelingt dies, stellt es ein Indiz für eine erfolgreiche Implementierung dar. Dies wird beispielsweise in der Fallstudie im nächsten Abschnitt gezeigt. Jedenfalls ist es sinnvoll, noch weitere Tests durchzuführen, hierzu gibt es je nach konkreter Umsetzung in der Literatur ausreichend erprobte Möglichkeiten. - Wartung
Unter Wartung fällt «die Veränderung eines Softwareprodukts nach dessen Auslieferung, um Fehler zu beheben, Performanz oder andere Attribute zu verbessern oder Anpassungen an die veränderte Umgebung vorzunehmen»15. Im vorliegenden Fall ist also zu unterscheiden zwischen:- Wartung zum Zweck der Verbesserung der Software, wenn etwa Fehler im Modell ausgebessert oder auch Algorithmen und Regeln korrigiert bzw. neue Funktionalitäten eingeführt werden.
- Wartung zum Zweck der Anpassung an externe Änderungen. Manche Rechtsnormen werden mehr oder weniger regelmäßig angepasst. Wenn das entsprechende Modell mit diesen Änderungen umgehen kann, verlängert dies seine Lebenszeit erheblich.
IV.
Fallstudie: Curriculumserstellung ^
1.
Umwelt und Setting ^
Das Universitätswesen im europäischen Raum und so auch in Österreich durchläuft seit Beginn der 1990er große Veränderungen. Mit dem Universitätsgesetz 2002 wurden die österreichischen Universitäten vollrechtsfähig, dies brachte unter anderem das Erfordernis zur Erlassung einer universitären Satzung mit sich. IT-Systeme für Curricula müssen so auch diesen Rechtsnormen entsprechen. Weiters gab es umfangreiche Änderungen im Studienrecht, beispielsweise wurden die Weichen in Richtung Bologna-Architektur gestellt, vornehmlich also ein dreistufiges System aus Bachelor-, Master- und Doktoratsstudien. Auch wurde ein einheitliches Leistungspunktesystem eingeführt, das European Credit Transfer System (ECTS)16.
2.
Implementierung des Grundmodells ^
2.1.
Ontologien ^
| Ontologie | Inhalt |
| cml.owl | Grundstruktur, bindet die anderen Ontologien ein. |
| cml_uni.owl | Modelliert Universitäten und andere Bildungseinrichtungen. |
| cml_curr.owl | Modelliert ein Curriculum; stellt sicher, dass alle nötigen Bestandteile vorhanden sind. |
| cml_templates.owl | Musterdaten, Vorlagen für verschiedene Arten von Curricula, Vorschläge für Rechtstext, englische Übersetzungen. |
| cml_rules.owl | Enthält die in SWRL modellierten Regeln zur automatisierten Prüfung von Curricula. |
| cml_extended.owl | Stellt die Verbindung zu LKIF her, Mapping von externen Konzepten. |
Tabelle 1: CML Ontologien
2.2.
Semantisches Regelwerk ^
CML macht starken Gebrauch von SWRL. Drei grundlegende Arten von Regeln können zur Validierung eines modellierten Curriculums unterschieden werden:
- Bedingungen, die erfüllt sein müssen, damit ein Curriculum als gültig und korrekt bezeichnet werden kann. Ein Bachelor-Curriculum an der JKU muss beispielsweise mindestens eine Lehrveranstaltung beinhalten, «die Inhalte der Frauen- und Geschlechterforschung abdecken; dies sind mindestens a) eine Pflichtlehrveranstaltung im Umfang von 3 ECTS in Bachelor- und Diplomstudien.»17 Dies kann mit folgender SWRL-Regel überprüft werden, die korrekte Curricula als CurriculumMitGenderLV kategorisiert:

- Regeln, die die Aufmerksamkeit der für die Prüfung des Curiculums verantwortlichen Person auf eine Irregularität lenkt, deren Erfüllung jedoch keine unbedingte Voraussetzung für ein korrektes Curriculum ist. Beispielsweise umfassen Bachelor-Curricula üblicherweise 180 ECTS, von diesem Wert kann jedoch in begründeten Fällen abgewichen werden18. Die folgende Regel überprüft, ob der Standardwert der Kategorie des Curriculums eingehalten wird, andernfalls wird das Curriculum als CurriculumSpezialECTS kategorisiert.
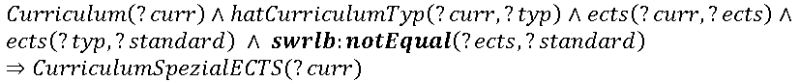
- Die dritte Kategorie beinhaltet jene Regeln, die nicht oder nur mit hohem Aufwand mit semantischen Technologien umgesetzt werden können. In vielen Fällen liegt dies an der in OWL gültigen Open World Assumption (OWA). Deren Grundidee ist es, dass, wenn ein bestimmtes Stück Wissen nicht von der Menge an bestehendem Wissen abgeleitet werden kann, nichts daraus geschlossen werden kann. Somit kann zwischen nicht vorhandenem und negativem Wissen unterschieden werden19.
Viele Regeln dieser Kategorie sind summenbasiert, so wie das folgende Beispiel: Es soll festgestellt werden, ob die Summe der ECTS der Fächer eines Curriculums den Gesamt-ECTS des Curriculums entspricht. Abbildung 5 zeigt die Problematik: In OWA kann man nicht wissen, ob die momentan untergeordneten Fächer tatsächlich die einzigen sind. Es könnte immer ein weiteres Fach auftauchen, das bisher nicht berücksichtigt wurde.
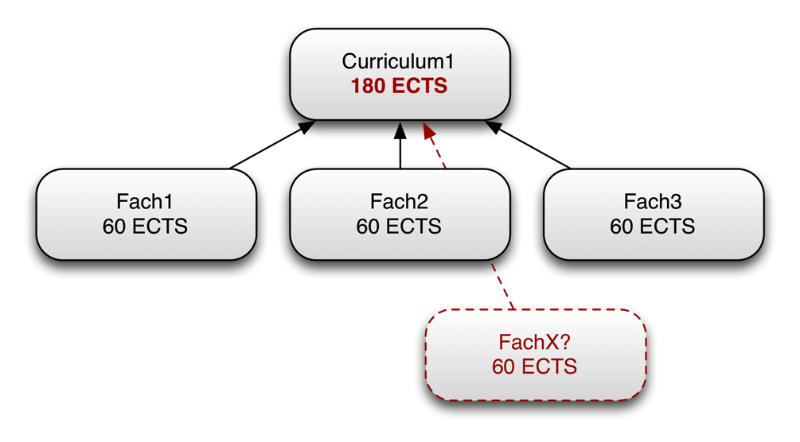
Abbildung 5: Problematik OWA
- Eine Möglichkeit, dieses Problem zu lösen, ist die Einführung von sogenannten Closure Axiomen, die eine künstliche Closed World Umgebung erzeugen. Diese Vorgehensweise erweitert die Ontologie um eine sehr große Anzahl von Axiomen, zudem muss jede Änderung an mehreren Stellen passieren. Eine weitere Möglichkeit wäre der Einsatz von SQWRL (Semantic Query-Enhanced Web Rule Language), welches zeitpunktbezogene Abfragen in einer Ontologie bietet, wie sie in einem Closed World System möglich wären20. Im folgenden Beispiel wird SQWRL eingesetzt, um eine Summe der ECTS der Fächer zu bilden und diese mit dem Curriculum zu vergleichen:
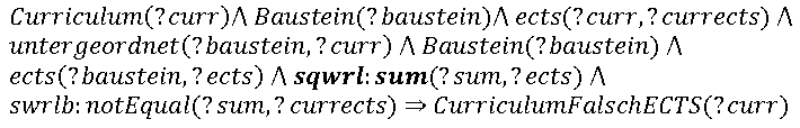
- Da SQWRL noch nicht standardisiert ist und von vielen Frameworks bzw. Reasonern nicht voll unterstützt wird, verwendet unser Ansatz Java-Algorithmen, um die gewünschten Überprüfungen durchzuführen.
2.3.
Grafische Benutzeroberflächen ^
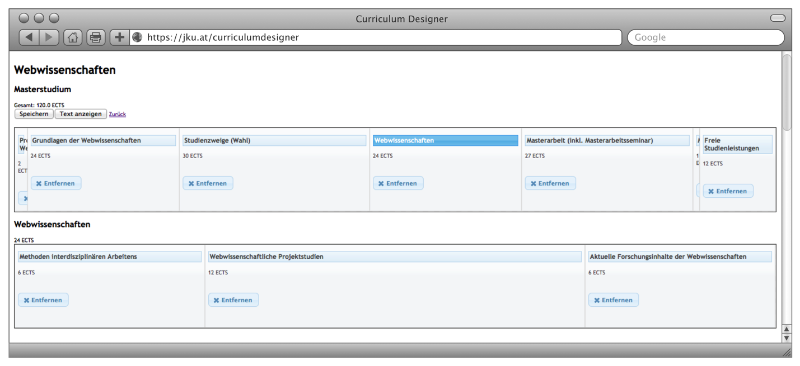
Abbildung 6: Curriculum Designer
3.
Ergebnisse ^
V.
Fazit ^
Martin Stabauer / Johann Höller, Institut für Datenverarbeitung in den Sozial- und Wirtschaftswissenschaften, Johannes Kepler Universität Linz.
- 1 Vgl. z.B. Muhr, Rudolf (2012): Zur Bürgerfreundlichkeit und Verständlichkeit alltagsnaher österreichischer Rechtstexte. In: Moraldo, Sandro M. (Hrsg.): Sprachenpolitik und Rechtssprache – Methodische Ansätze und Einzelanalysen, S. 117–140.
- 2 Vgl. z.B. Kowalski, Robert A. (1995): Legislation as logic programs. In: Informatics and the Foundations of Legal Reasoning, Springer, S. 325–356. Oder auch Bourcier, Danièle (1995): La décision artificielle: le droit, la machine et l’humain. Presse universitaires de France. Oder auch Rissland, Edwina et al. (2003): AI and Law – a fruitful synergy. In: Artificial Intelligence 150(1).
- 3 Vgl. Lauritsen, Marc (2013): Are we free to code the law? In: Communications of the ACM 56(8), S. 60–66.
- 4 Vgl. Höller, Johann/Ipsmiller, Doris (2009): Semantik – was wir immer schon wussten: Semantische Technologien in der Unterstützung von Rechtsetzungsprozessen. In: Schweighofer, Erich (Hrsg): Semantisches Web und Soziale Netzwerke im Recht: Tagungsband des 12. Internationalen Rechtsinformatik Symposions, S. 144ff.
- 5 Vgl. Winkels, Radboud/Den Haan, Nienke (1995): Automated legislative drafting – Generating paraphrases of legislation. In: Proceedings of the 5th international conference on Artificial intelligence and law, ACM, S. 112–118.
- 6 Schefbeck, Günther (2009): Per Anhalter durch das Legiversum – Rechts- und Legislativinformatik 2.0. In: Schweighofer, Erich (Hrsg): Semantisches Web und Soziale Netzwerke im Recht: Tagungsband des 12. Internationalen Rechtsinformatik Symposions, S. 55.
- 7 Vgl. http://www.estrellaproject.org.
- 8 Vgl. Horrocks, Ian et al. (2004): SWRL: A Semantic Web Rule Language – Combining OWL and RuleML, http://www.w3.org/Submission/SWRL.
- 9 Vgl. Boley, Harold et al. (2001): Design Rationale of RuleML – A Markup Language for Semantic Web rules. In: Proceedings oft he Semantic Web Working Symposium, S. 381–401.
- 10 Vgl. z.B.: McCarty, L. Thorne/Sridharan, N.S. (1982): A computational theory of legal argument. Oder auch Bing, Jon (1984): Handbook of legal information retrieval.
- 11 Vgl. Bizer, Christian et al. (2008): Linked data on the web. In: Proceedings of the 17th international conference on World Wide Web, ACM, S. 1265–1266.
- 12 Vgl. Hitzler, Pascal et al. (2012): OWL 2 Web Ontology Language Primer (Second Edition), http://www.w3.org/TR/owl2-primer.
- 13 Vgl. Boehm, Barry W. (1988): A spiral model of software development and enhancement. In: IEEE Computer 21(5), S. 61–72.
- 14 Vgl. Bourque, Pierre/Fairley, Richard E. (2014): SWEBOK 3.0 – Guide to the Software Engineering Body of Knowledge, IEEE Computer Society.
- 15 IEEE Standard Glossary of Software Engineering Technology 610.12-1990, S. 46.
- 16 Vgl. ECTS-Leitfaden (2009), http://ec.europa.eu/education/tools/docs/ects-guide_de.pdf.
- 17 § 19 Abs. 1 Z 11 der Satzung der JKU, Satzungsteil Studienrecht.
- 18 Vgl. § 54 Abs. 3 des Universitätsgesetzes (UnivG).
- 19 Vgl. Grimm, Stephan (2010): Knowledge Representation and Ontologies. In: Scientific Data Mining and Knowledge Discovery – Principles and Foundations, Springer, S. 210ff.
- 20 Vgl. O’Connor, Martin J./Das, Amar K. (2009): SQWRL: A Query Language for OWL. In: OWLED’09.
- 21 Vgl. http://protege.stanford.edu.





