1.
Einführung ^
1.1.
Formen von Big Data ^
Traditionelles IR sucht in der Regel die sprichwörtliche Nadel im Heuhaufen, wofür es die Suchanfrage mit Wissen über den Suchenden (Vergangenheit und aktueller Kontext) und Wissen über Such- und Finderverhalten anderer kombiniert und mit Eigenschaft von Elementen aus einer Suchmenge, z.B. Websites bei der Google-Suche, vergleicht. Klassisches Big Data sucht dagegen mehr den roten Faden im Heuhaufen: Es schätzt nicht explizit bekannte Attribute und basiert darauf, dass man zuvor aus grossen Datenmengen abgeleitet hat, wie Eigenschaften respektive Attribute zusammenhängen. Diese Erkenntnis wird für das Schätzen unbekannter geschäftskritischer Eigenschaften durch die Nutzung bekannter andere Eigenschaften benutzt.1 Freestyle Big Data strebt an, Zusammenhänge in Daten zu erkennen, von deren Existenz man zuvor nichts wusste. Man spricht dabei auch vom explorativen Data Mining oder umgangssprachlich vom wissenschaftlichen Fischen im Trüben. Big Data auf dem Graphen versucht, die Zusammenhänge zwischen sehr unterschiedlichen Datensets auszuwerten und daraus Erkenntnisse abzuleiten, wobei weitgehend andere Algorithmen als bei den anderen Kernformen verwendet werden. Big Data Profiling versucht Daten zu de-anonymisieren und personenbezogen zu integrieren, um ein digitales alter Ego von natürlichen Personen oder auch von Organisationen zu schaffen. Und komplexes Big Data verwendet alle bisher beschriebenen Formen, um Konzepte oder allgemeiner Problemlösungen zu finden. Wobei die hier verwendete begriffliche Klassifikation primär dazu dienen soll, verständlich zu machen, was unter anderem bei Big Data passiert (und nicht als wissenschaftliche Ontologie zu verstehen ist).
Beim IR haben wir es mit mehreren Ingredienzien zu tun: formalen Repräsentationen von Informationsobjekten und von der Suchanfrage und formale Repräsentationen von Such-Historien, wobei letztere im Idealfall sowohl für den Suchenden als auch für andere mit ähnlichen Interessen bereitstehen. Daraus wird eine Rangliste der Objekte aus der Suchmenge definiert, die beschreibt (genauer: schätzt), wie relevant ein gesuchtes Objekt für den Suchenden in seiner jeweiligen Situation ist. Aus rechtlicher Perspektive besonders kritisch sind dabei zwei Punkte: Erstens kann Wissen über den Suchenden und seine aktuelle Situation genutzt werden, um die Qualität der erstellten Rangliste zu verbessern. Der Preis ist der Verlust von Privatsphäre. Zweitens kann Wissen über das Verhalten anderer ebenfalls genutzt werden, um die Qualität der Rangliste zu verbessern. Analog beim klassischen Big Data.
Der Einfachheit halber kann man hier von drei Ingredienzien sprechen: die geschäftskritische Frage, empirische Daten verschiedenster Art aus denen ableitbar ist, wie die richtige Antwort auf die gestellten Fragen mit bestimmten Eigenschaften korreliert und bekannten Daten zu diesen Eigenschaften. Auch hier sind oft die relevanten empirischen Daten personenbezogen, wenn auch möglicherweise (oder hoffentlich) anonymisiert.
Beim Freestyle Big Data gibt es nur Daten und menschliche Intuitionen, die in den Daten nach Mustern suchen, die dann mit Hilfe der Intuition interpretiert werden. Der Spezialfall, dass man nach einer Menge fix definierte Muster sucht, ist eine Form des klassischen Big Data. In der Praxis können so klassisches Big Data und Freestyle Big Data kombiniert werden. Je mehr Wissen über die Daten und den Echtweltbereich, den sie beschreiben, existiert, desto grösser sind die Erfolgschancen.
Beim Big Data Profiling werden in der Regel zuerst Daten zusammengeführt, die sich auf die gleiche, vorerst noch anonyme Person beziehen, um dann durch Abgleich mit bekannten explizit personenbezogenen Daten die Person zu ermitteln. Oft wird die Person erst sehr spät identifiziert oder es wird auf den eigentlichen Deanonymisierungsschritt ganz verzichtet. Solch ein verkürztes Profiling ist auch ein wesentliches Element von IR und anderen Big Data Formen. Auch ohne den eigentlichen Deanonymisierungsschritt stellt es einen Eingriff in die Privatsphäre der Betroffenen dar. Rechtlich ist das Stattfinden der De-Anomysierung sowieso nach dem Schweizer DSG irrelevant, weil ja der letzte Schritt in der Regel mit geringerem Aufwand durchführbar ist als die davor durchgeführten Schritte.
1.2.
Geschichte und aktueller Diskussionsbedarf ^
Es stellen sich aber viele weitergehende rechtliche Fragen. Unsere digitalen Datenspuren sind vielfältig. Sie können untereinander und mit Sachdaten verbunden werden. Die Durchführung von Big Data setzt fast immer auch auf den Abgleich mit den Daten anderer und die letztendliche Nutzung der Big Data Ergebnisse führt dazu, dass das Verhalten anderer sich auf unsere Chancen im Leben auswirkt. Dies gilt besonders dann, wenn bei der Durchführung von Big Data Fehler gemacht werden, aber auch dann, wenn Big Data richtig gehandhabt wird, weil es ja darum geht, aus der Kenntnis des Verhaltens der vielen Schlüsse auf den situativen Einzelfall (d.h. den eigenen Einzelfall) zu machen. Inwieweit das zulässig ist und nicht die Rechte des Einzelnen unzulässig einschränkt, ist zu hinterfragen.
Weiters sind in der Datenwelt die Rechte-Konzepte der Informatik dem Gegenstand angemessener als das Eigentumsverständnis der physischen Welt. Der Zusammenhang zwischen Ortung und Ordnung im Sinn von Carl Schmitt fällt bei virtuellen Cloud-Architekturen weg.3 Und der Zuwachs an Wissen durch Big Data hat zur Folge, dass alle Bereiche, in denen Nichtwissen die Ursache von gesellschaftlich wünschenswertem Verhalten war, politisch neu zur Diskussion stehen. Beispielsweise macht Nichtwissen über die Zukunftschancen Einzelner Solidarität und soziales Teilen einfacher: Mit jemandem solidarisch zu sein, der das sicher nie zurückgeben wird, ist schwieriger als Solidarität bei einem potentiell reziproken Anspruch auf seine/ihre Solidarität. Big Data wirft also viele neue rechtliche und politische Fragen auf.
2.
Nutzung und Nutzen ^
2.1.
Vier Schritte des Big Data Prozesses ^
Für ein erstes Einarbeiten in das Thema, ist es sinnvoll, Big Data als Prozess zu verstehen, der aus vier Schritten besteht. Die ersten drei Schritte stellen dabei die Durchführung von Big Data dar, der vierte Schritt die eigentliche Nutzung bzw. Valorisierung. Die Schritte sind:
- Sammeln von Daten
- Integrieren von Daten
- Interpretieren von Daten
- Nutzen der Interpretationsresultate
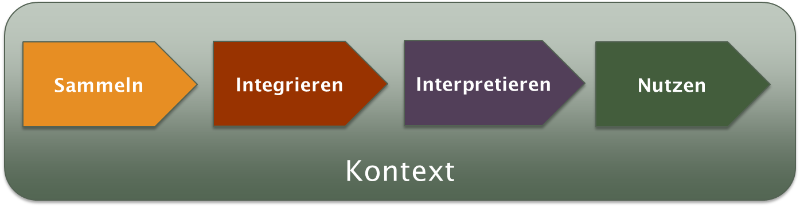
Es ist wichtig, sich stets bewusst zu sein, dass nur in einer idealen Welt, die vier Schritte problemlos getrennt betrachtet werden können und beispielsweise ein richtig durchgeführter dritter Schritt immer zu richtigen Resultaten führt, die höchstens aus Sicht von Schritt 4 wertlos sein können. In einer Welt mit Unzulänglichkeiten beeinflusst aber ein vorgängiger Schritt nicht nur den Nutzen, sondern auch die Qualität der Arbeit in den nachfolgenden Schritten. Werden im ersten Schritt obskure Daten gesammelt oder werden Daten im zweiten Schritt obskur integriert, so wird das nicht notwendigerweise im dritten Schritt erkannt, weshalb auch in diesem Schritt potentiell obskur gearbeitet wird. Eine bestmögliche Entkopplung der vier Schritte ist nur durch Zweierlei möglich: eine korrekte und gut verständliche Dokumentation des Outputs plus Direktkommunikation mit den Akteuren im nächsten Schritt. Das kann man so auf den Punkt bringen: Die Teilung der Arbeit funktioniert im Big Data nur sauber bei enger Zusammenarbeit.
Aus organisationsstrategischer wie auch aus politischer und rechtlicher Perspektive sind in den vier Schritten ganz unterschiedliche Aspekte relevant. Aus Gesamtperspektive gilt es naturgemäss zu beurteilen, ob das Handeln im Big Data Prozess rechtskonform ist und ob dadurch gesellschaftlicher Schaden oder Nutzen entsteht. Doch das ergibt sich einerseits aus einer Vielzahl von Teilaspekten der einzelnen vier Schritte und anderseits aus der Wechselwirkung mit dem Kontext, in dem die vier Schritte stattfinden.
Im ersten Schritt werden die Datenquellen für die Durchführung von Big Data identifiziert und die Daten aus diesen Quellen werden gesammelt, um sie in den nachfolgenden Schritten für Big Data zu nutzen. Dabei haben die Rechte auf die Quellen, das Wissen über die Quellen, die Qualität der Wuellen und das Passen der Quelle zum Zweck der Big Data Anwendung sowie das gut nachvollziehbare Dokumentieren von allem kritische Bedeutung. Je nach Fall werden Daten bei Big Data ad hoc oder strategisch geplant eingesetzt und es werden nur eigene oder auch externe Quellen genutzt. Dabei ist die Datenqualität kritisch.
Im zweiten Schritt werden die gesammelt Daten aufbereitet und zusammengefügt zu einer Quelle für die Anwendung von Big Data. Das kann je nachdem sehr aufwendig sein oder sehr trivial. Die Abgrenzung zwischen zweitem und drittem Schritt ist auch nicht unbedingt scharf. Ziel des zweiten Schritts ist es, dass im dritten Schritt auf eine Datenquelle mit einem Datenmodell zugegriffen werden kann. Das heisst aber nicht, dass alle Daten die gleiche Syntax und Semantik besitzen müssen. Kritisch ist allerdings die Qualität der Integration. Werden Kraut und Rüben, oder Gemüse unterschiedlicher Güteklassen gemischt, so dass dies im nachfolgenden Schritt nicht mehr unterscheidbar ist, so entsteht eine Datenquelle mit sehr schlechter Qualität für den nächsten Schritt. Je nachdem ob identische oder unterschiedliche Datenmodelle den Daten zugrunde liegen (oder diese gar nicht bekannt sind) und je nachdem die Qualität der Daten ähnlich oder unterschiedlich ist, sollten darum andere Techniken eingesetzt werden. Eine wesentliches Instrument zur Integration ist im Fall heterogener Datenquellen die Linked Data Technologie.
2.2.
Das Stack-Prinzip ^
2.3.
Nutzungsbereiche ^
Wichtige Anwendungsbereiche sind (angeordnet nach subjektiv beurteilter Relevanz und ohne Anspruch auf Vollständigkeit) Wirtschaft, Wissenschaft, Gesundheitswesen, Verwaltung, Energie und Verkehr, Justiz, Politik und Kunst. In der Wirtschaft wird Big Data vor allem dafür verwendet, attraktive Kunden zu identifizieren und Produkte und Dienstleistungen masszuschneidern, beispielsweise im Customer Relationship Management. Der Nutzen besteht (sofern das professionell gemacht wird) darin, dass der im Durchschnitt geschaffene Wert pro Kunde grösser wird und damit auch die Verdienstmöglichkeiten steigen – sei es dass Kunden gewonnen werden, die sonst nicht kaufen würden, oder sei es, dass mehr Kunden mit hoher Zahlungsbereitschaft gewonnen werden, oder sei es, dass an bisherigen Kunden mehr verdient wird. Daneben wird Big Data auch für Strategieentwicklung und Planungsaufgaben eingesetzt. Der ideelle Nutzen besteht dann darin, dass Strategien und Pläne faktenbasierter sind. Ob dies sich in einen realen Nutzen umwandeln lässt, hängt von der Qualität der Faktennutzung ab.
In der Wissenschaft wird Big Data zum Erkenntnisgewinn eingesetzt, der ja das Kernziel von Wissenschaft ist und also per definitionem – also eo ipso – Nutzen schafft. Dabei gibt es die Hoffnung, Teile des wissenschaftlichen Arbeitens automatisieren und den wissenschaftlichen Fortschritt wesentlich beschleunigen zu können. Es gibt aber auch ganz andere Perspektiven: Wenn Daten das neue Öl sind, wie von vielen gesagt wird, so sind Wissenschafter möglicherweise die neuen Hilfsarbeiter beim Ölfördern.
Im Gesundheitswesen wird Big Data nicht nur für Forschung, Absatzsteigerung und strategische Ressourcenplanung eingesetzt (siehe oben), sondern auch für eine personalisierte Behandlung von Patienten. Hier besteht der Nutzen darin, dass Therapien massgeschneidert eingesetzt und Informationen aus den Krankheitsverläufen anderer Patienten genutzt werden. Der Nutzen besteht in wirksameren Behandlungen, wobei dies bei Therapien in einigen Bereichen auf Kosten der bisherigen wissenschaftlichen Standards gehen könnte und Qualitätsfragen aufwirft. In Zukunft werden Gesundheitsdaten jedenfalls nicht absolut sondern patientenindividuell interpretiert und Therapien individuell durchgeführt werden.
In der Verwaltung wird Big Data bisher primär im Sicherheitsbereich eingesetzt. Dies wird in Zukunft noch zunehmen. Im Prinzip kann es aber auch ganz ähnlich eingesetzt werden wie in der Wirtschaft, das heisst für Planung, Strategieentwicklung und weitere Steuerungsaufgaben. Dazu wird in Zukunft auch der Einsatz in der Katastrophenvorsorge kommen, beispielsweise bei der Vorhersage von Hangrutschen. Massgeschneiderte Verwaltungsdienstleistungen analog zu massgeschneiderten Dienstleistungen in der Wirtschaft sind ebenfalls vorstellbar, finden aber derzeit vor allem in menschlicher Interaktion und verhandlungsbasiert statt. Bei allen potentiellen Vorteilen von Big Data bestehen aber auch grosse Befürchtungen, dass ganze operative Verwaltungstätigkeiten automatisiert werden könnten, beispielsweise die Vergabe von Sozialhilfe.
In der Politik hat Big Data spätestens mit dem zweiten Obama Präsidentschaftswahlkampf eingezogen, als sein Wahlkampfteam mittels Konsumdaten Wechselwähler identifizierte, die dann persönlich angesprochen wurden. In Zukunft wird Big Data auch ganz analog zur Wirtschaft in der Politik eingesetzt werden können, um besonders attraktive Wahlprogramme und politische Positionen zusammenzustellen. Der Nutzen besteht, lapidar formuliert, in der Erhöhung von Wahlchancen. Für die Ausübung von Exekutivämtern bietet Big Data zudem neue Möglichkeit der Langfristplanung. Der Schweizer Bundesrat könnte Big Data beispielsweise als Ergänzung zur aktuell verwendeten Szenario-Technik einsetzen4, um prognostizierbare Entwicklungen als Eckpunkte für Szenarien zu verwenden.
2.4.
Praktische Herausforderungen ^
Die zu bewältigenden Probleme reichen von der Identifikation dessen, was man wissen will (klassisches Big Data) über die sehr anspruchsvolle «intelligente» Datenverarbeitung (die richtigen Datenquellen mit ausreichender und bekannte Datenqualität finden + richtige Modelle und richtige Algorithmen nutzen) oder die fast noch anspruchsvollere Mustersuche (Voraussetzungen schaffen, dass Muster entstehen [z.B. bei netzwerkbasierter Angriffsdetektion] + Muster sehen + Muster verstehen) bis zur bislang teilweise noch sehr unreifen Technologie (z.B. bei Linked Data Verarbeitungspipelines) und der tatsächlichen effektiven Nutzung der Big Data Resultate, gegen die es oft heftige, erklärte und nicht erklärte, Widerstände in den Organisationen gibt.
3.
Kritische Paradigmenwechsel und Schimären ^
3.1.
Paradigmenwechsel ^
Sechs Paradigmenwechsel werden in den nächsten Jahren in vielen Bereichen keinen Stein auf dem anderen lassen: der Wechsel vom sorgfältigen zum unsauberen Umgang mit Daten, der Wechsel vom Denken in Kausalitäten zum Nutzen von Korrelationen, der Wechsel vom Klassifizieren (von Kunden, Partnerns etc.) zur radikalen Personalisierung basierend auf digitalen Alter Egos, der Wechsel vom bedarfsorientierten Datensammeln zum Datenfluten mit dem Internet of Things, die Veränderung der Wirtschaft durch mächtige von einem einzigen Datenherrn beherrschte Universum und der Abschied vom monodisziplinär juristischen Denken im Datenschutz.
(1) Laxes Qualitätsverständnis + Unsauberes Mischen
Erstens entspannt sich das Verhältnis zur Datenqualität und Datensauberkeit. Neu werden Daten, die verschiedenen Datenmodellen entsprechen und unterschiedliche Qualität haben, zusammengemischt. Das wissenschaftliche Gebot, nicht Äpfel und Birnen zu mischen fällt in Bezug auf die Datenwissenschaft, Daten unterschiedlicher Art und Qualität werden zusammengeführt. Dabei gibt es (a) den Fall, dass Daten des gleichen Datenmodells mit unterschiedlicher Qualität zusammengeführt werden, (b) den Fall, dass semantisch gleiche Daten mit unterschiedlicher Syntax zusammengeführt werden, (c) den Fall, dass syntaktisch und semantisch ähnliche Daten integriert werden (was aus Nutzungssicht der aktuell interessanteste Fall ist, beispielsweise in der medizinischen Forschung) und (d) den Fall, dass gänzlich verschiedene Daten mit inhaltlichen Querbezügen integriert werden (durch Linked Data). Das laxe Qualitätsverständnis geht in der Praxis so weit, dass auch Daten genutzt werden, deren genaue Semantik unbekannt ist. Die im Schweizer Datenschutzgesetz geforderte Richtigkeit der besonders schützenswerten Personendaten (DSG, Art. 5) wirkt in der Big Data Welt wie ein Anachronismus.
(2) Korrelationen statt Kausalitäten
(3) Radikale Personalisierung / Digitales Alter Ego
Drittens führt Big Data zu einer radikalen Personalisierung. Die traditionelle Segmentierung in der Werbung und der Produkt- bzw. Dienstleistungsspezialisierung wird durch das Fokussieren auf den oder die Einzelne/n ersetzt. Wo bisher Adressaten klassifiziert und klassenspezifisch angesprochen oder behandelt wurden, werden sie neu als Individuum angesprochen und behandelt, wobei sie im ersten Schritt weitestgehend mit ihrer digital aufgezeichneten Vergangenheit gleichgesetzt werden und im zweiten Schritt künstlich als Interpolationen des Verhaltens von Personen mit ähnlicher Vergangenheit berechnet werden. So versucht man direkt auf die Person zu spielen, spielt aber aus praktischer Notwendigkeit auf ihr digital konstruiertes Alter Ego, das eine Mischung aus selektiver individueller Vergangenheit und Massenverhalten ist. Frei nach Goethe «Bei Euch, Ihr Herren, kann man gewöhnlich das Wesen aus den Daten der anderen lesen.»
(4) Totale Vermessung der Welt / Datenflutung
(5) Datenuniversen / Monolithische Diversität
Big Data benötigt in der Regel grosse Datenmengen, die im Fall meist im grossen Stil anwendbare Resultate liefern, wodurch Economies of Scale gefördert werden. Allerdings ist es auch für ökonomische Nischen mit hochspezialisierten Produkten oder Leistungen einsetzbar, wie schon das Beispiel der personalisierten Medizin zeigt. Die erwartbare Wirkung auf die ökonomische Diversität ist bislang deshalb unklar. Allerdings fördert Big Data insbesondere die Entwicklung von Datenuniversen, die durch einen Datenherrn kontrolliert werden und deshalb eine Art monolithische Diversität besitzen. Jaron Lanier hat dafür den Begriff Sirenen-Server eingeführt.5 Das Geschäftsmodell eines Sirenen-Servers besteht cum grano salis darin, Datenlieferanten das Gefühl zu geben, dass sie kostenlose Dienste bekommen, sie indirekt aber fürs Datenliefern bezahlen zu lassen – sei es dass der Sirenenserver Dritten Dienstleistungen verkauft, deren Kosten sich diese von den Datenlieferanten bezahlen lassen (beispielsweise Präferenzprofile von Kunden, um bei diesen den Absatz oder die Produktpreise zu erhöhen, siehe klassisches Big Data), sei es dass er Steuern verlangt (beispielsweise die Verwaltung, der sich von den Einwohnern deren Überwachung finanzieren lässt). Das ist an sich weder neu noch originell, und die Stabilität der Datenuniversen ist noch unklar, die Ausprägung hat aber eine neue Qualität und vor allem Wachstumsdynamik erreicht, so dass man auch hier von einem Paradigmenwechsel sprechen sollte. Bislang sind Datenuniversen rund um Gratis-Informations- und -Kommunikationsdienstleistungen entstanden, sowie im Wartungs- und Vermietungsgeschäft, beispielsweise in der Autobranche, und im Geheimdienstwesen entstanden. Weitere Bereiche werden folgen.
(6) Transdisziplinärer Datenschutz
Mit der weitgehenden Infragestellung der rechtlichen Unterscheidung von personenbezogenen und anonymisierten Daten (aufgrund des Profilings) und von besonders schützenswerten und nicht besonders schützenswerten Daten (aufgrund der klassischen Big Data Methodik) wird die Schutzmacht von Datenschutzgesetzen grundsätzlich in Frage gestellt. In Zukunft kann nur ein Zusammenspiel von Recht, Organisation, Technik und Bildung den Schutz der Privatsphäre gewährleisten. Neben der Rechtssetzung werden sich an den Stand der Technik anpassende Normen und Empfehlungen benötigt, ebenso wie neue Formen der Supervision und des Wissensaustausches, sowie Bildungsaktivitäten. Dieses transdisziplinäre Verständnis ist allerdings erst im Entstehen. Zur Diskussion steht unter anderem die Wiederbelebung des Konzepts der vertrauenswürdigen nicht verfolgbaren Anonymität, das auf grundlegende Arbeiten von David Chaum in den 80ern zurückgeht6 und dessen Anwendbarkeit für E-Government bereits vor über 10 Jahren untersucht wurde7. Die Alternativen zum transdisziplinären Datenschutzverständnis wäre eine stark restriktive Gesetzgebung, die die Nutzung des Big Data Potentials zu verhindern sucht. Solch eine Gesetzgebung würde aber vermutlich durch die von vielen praktizierte freiwillige Datenbekanntgabe unterlaufen.
3.2.
Resultierende Chancen und Risiken ^
3.3.
Weitergehende Hoffnungen ^
Eine mit Big Data verbundene grosse Hoffnung ist, in Zukunft in vielen Bereichen gesicherte Zukunftsprognosen zu machen und die strategische Planung zu industrialisieren, das heisst den Datenverarbeitungspipelines zu überlassen. Damit könnte ein neues Paradigma entstehen, dass nämlich aus der Vergangenheit die Zukunft vorausgesagt werden kann. Solch ein neu-deterministisches Weltbild ist für viele sehr attraktiv, weil es demjenigen, der die Zukunft besser voraussagen kann, riesige Vorteile verspricht. Insofern es disruptive Veränderungen gibt, Innovation und Fortschritt immer über kleine Statistiken verfügen, ist aber davon auszugehen, dass Big Data gerade bei wesentlichen Veränderungen versagen wird – nicht bei allen, aber bei einigen – und eine Big Data basierte Innovationstriage entstehen könnte: Big Data identifizierbare Innovationen würden stark gepuscht und Big Data nichtaffine Innovation blockiert, weil frei nach Morgenstern «Nicht sein kann, was Big Data nicht voraussagt».
3.4.
Schimären der Wissenschaft und Fiktionen der Praxis ^
Zur den Schimären des wissenschaftlichen Diskurses zählen
- Vorhanden sein und Verfügbarkeit der richtigen Daten: Das heisst, die Daten sind in der Welt und man muss sie nur einsammeln. Kommentar: In der Praxis sind die vorhandenen Daten nach wie vor häufig äusserst unvollständig.8 Zudem wird der Zugriff stark eingeschränkt. Bekannt ist, dass Betreiber von digitalen sozialen Netzen der Wissenschaft nur kleine Auszüge zur Verfügung stellen, ausgenommen den eigenen Wissenschaftlern.
- Objektive Gültigkeit der Rohdaten: Das heisst, wer Rohdaten verwendet, soll sich um deren Qualität keine Sorgen machen müssen, weil die «echt» sind und keinen «Bias» besitzen. Kommentar: Das Erzeugen von Daten enthält immer eine Selektion. Datenwahrheit und Wahrheit sind zweierlei. Wer diesen Bias nicht kennt arbeitet oft besser mit gut aufbereiteten Daten.
- Statistisches Ausmitteln von Ausreissern: Dass heisst, Datenfehler werden durch Datenmassen kompensiert. Kommentar: Ob dies geschieht oder nicht hängt vom Daten-Bias ab.
- Befreiung vom Joch der Modelle (oder: Das Ende der Theorie9): Dies ist die vielleicht derzeit wichtigste Schimäre. Sie meint, aufgrund der grossen Datenmassen und von Big Data ist es in Zukunft in der Forschung möglich, auf Modelle der Wirklichkeit zu verzichten. Kommentar: Damit wird eine wissensfreie Wissenschaft angestrebt in der Sachkenntnis kaum mehr Bedeutung hat. Solch eine Reduktion auf das allein selig machende Wundermittel hat in der Geschichte im Kleinen wie im Grossen meist zum Desaster geführt. Zudem ist die Vorstellung ziemlich erschreckend, dass in Zukunft Exekutiventscheidung auf Big Data Empfehlungen basieren, beispielsweise bei Polizeieinsätzen, die keiner versteht.
- Jeder profitiert: Das heisst, von Big Data profitieren zwar manche mehr als andere, doch alle haben etwas davon. Kommentar: Die Ungleichheit beim Profitieren von Big Data ist sehr gross. Bei den dominierenden Diensten der Internetgesellschaft werden einige wenige Multimilliadäre, während die Masse Gratisdienstleistungen bekommt. Für diese Gratisdienstleistungen muss aber beim Konsum anderer Güter bezahlt werden. Zusätzlich werden Arbeitsplätze vernichtet. So dass die Nutzenbilanz für die Gesellschaft als Ganzes sehr zwiespältig ausfällt.
- Alles freiwillig (und implizit: alles ist lokal): Das heisst, dass jeder entscheiden kann, ob er Daten liefern will oder nicht und dass seine Entscheidungen nur Auswirkungen auf ihn haben. Kommentar: In vielen Bereichen werden Dienstleistungen verweigert oder stark eingeschränkt, wenn nicht in die Datenweitergabe eingewilligt wird. Zudem betreffen die eigenen Daten gerade bei Big Data auch immer andere. Und nicht zuletzt sind alle Big Data Werkzeuge, die entwickelt werden auch für kriminelle Aktivitäten und für staatlichen Terror nutzbar. So wie Banken und Versicherungen die Vertrauenswürdigkeit von Kunden prüfen, können auch kriminelle Organisation die Vertrauenswürdigkeit ihrer Mitglieder und Staaten die Angepasstheit ihrer Bürger prüfen.
Dazu kommen in der Praxis noch viele weitere Fiktionen. Als Begleiter der wissenschaftlichen Schimäre des modellfreien Big Data tritt beispielsweise in der Praxis die Illusion auf, dass durch Big Data Domänenwissen überflüssig wird. Weitere Illusionen sind:
- Transparente Datenquellen: Das heisst, wir wissen in der Regel woher die verwendeten Daten kommen, was sie bedeuten und wie hoch ihre Qualität ist. Kommentar: Das ist ganz selten der Fall.
- Transparente Big Data Anwendungen: Das heisst, Big Data ist verstehbar und nachvollziehbar, auch wenn man die Algorithmen nicht kennt. Kommentar: Big Data verführt dazu, die dadurch produzierten Empfehlungen nicht zu hinterfragen. In vielen Fällen hat niemand den Überblick, was dabei wirklich geschieht – insbesondere dann wenn alte Software-Module oder Software-Module anderer als Plug-in verwendet werden und die verwendeten Algorithmen bereits in Vergessenheit geraten sind.
- Schutz der Privatsphäre durch Anonymisierung: Das heisst, wenn personenbezogene Daten anonymisiert werden, dann ist die Privatsphäre geschützt und das DSG nicht anzuwenden. Kommentar: Big Data Profiling strebt genau die De-Anonymisierung an.
- Jeder kann ...: Das heisst, dass es keine besonderen Fähigkeiten braucht, weil die Big Data Nutzung als Dienstleistung bezogen werden kann. Kommentar: Für einfache Anwendungen ist das richtig, für komplexe sicher nicht. Die Ansprüche an die verschiedenen fachlichen Fähigkeiten, die benötigt werden, sind so hoch, dass es für einige Anwendungsbereiche gar keine Dienstleister gibt, deren Qualifikation über jeden Zweifel erhaben wäre. Für die Richtigkeit der bereitgestellten Kontextinformationen und die Valorisierung der Resultate muss sowieso jeder Nutzer selber gerade stehen.
- Big Data = umfassendes Wissen über die Welt (oder auch: Kontinuitätsfiktion): Das heisst, dass wir mit Big Data aus Daten der Vergangenheit nicht nur zuverlässige allgemeine Zukunftsprognosen machen können, sondern auch ganz konkret zukünftige Interessen von Menschen in Politik und Wirtschaft voraussagen können. Denn (so die Meinung) von der Vergangenheit kann man auf die Zukunft schliessen, wenn man nur genügend viele Aspekte berücksichtigt. Kommentar: Aus digitalen Daten über die Vergangenheit lässt sich selbst die Vergangenheit nur rudimentär konstruieren, geschweigen denn die Gegenwart oder gar die Zukunft. Zudem stellt alleine schon die Erwartung, dass alles prognostizierbar ist, eine Innovationsbremse dar, nicht nur weil sie den Mut für disruptive Innovationen nimmt, sondern weil kreativitätsfreie, billige» datenbasierte Pseudoinnovation als allzu verführerisch erscheinen.
- Big Data = direkter Nutzen: Das heisst, wenn die ersten drei Schritte des Big Data Prozesses gut durchgeführt werden, schafft das Nutzen. Kommentar: In der Praxis gibt es grosse Widerstände gegen die Nutzung zusätzlichen Wissens, die über die Widerstände aufgrund von fehlenden Fähigkeiten für den Umgang mit Big Data weit hinausgehen. Es gibt natürlich Fälle, wo Fakten nur akzeptiert werden, weil sie von Computern stammen (weshalb die siebte Form von Big Data die Erkenntnisfassade ist), oft aber scheitert umgekehrt Big Data in der Organisationspraxis entweder an der Ablehnung von Faktenbasierung oder an der Ablehnung der Computerprogramme als Faktenquelle.
Geht man in konkrete Nutzungsbereiche hinein, könnte man die Auflistung von Paradigmenwechseln, Schimären und Fiktion problemlos erweitern. Denn Big Data verändert in vielerlei Hinsicht ganz grundsätzlich wie wir arbeiten und planen. Ein Beispiel ist die Schimäre der intelligenten Stadt. Sie tritt mit wachsender Popularität in der Stadtentwicklung auf, führt dort zu grossen Einflussverschiebungen und schafft in der Praxis neue grosse Risiken, weil auch hier das existierende Domänenwissen nicht mehr berücksichtigt wird10. Exemplum docet, exempla obscurant.
3.5.
Schlussfolgerungen ^
Das Bewältigen von Paradigmenwechseln stellt fast immer eine grosse Herausforderung dar. Fehler und grober unbeabsichtigter Missbrauch sind ebenso zu erwarten wie die Unfähigkeit, mit absichtlichem, gar kriminellem Missbrauch sicher umzugehen. «Denn wir wissen noch nicht, was wir tun.» Vorsicht ist also geboten. Die skizzierten Schimären und Fiktionen illustrieren ein wenig die Gefahren die auf uns lauern.
4.
Regulierungsbereiche ^
Um nochmals einige wichtige Beobachtungen – ohne Anspruch auf Vollständigkeit – zusammenzufassen, die häufig zutreffen: Die Rohdaten sind nicht objektiv. Das Gesetz der grossen Zahlen ist bei systemischen Fehler wirkungslos. Ohne gute Modelle und vielfältige Fachkompetenzen geht es nicht. Ohnehin gibt es die Daten, die es wirklich bräuchte, entweder gar nicht oder sie sind nicht verfügbar. Von denen, die wir nutzen können, kennen wir häufig weder ihre genaue Bedeutung noch ihre Qualität. Ohnehin sind die wesentlichen Aspekte der Zukunft nicht vorhersagbar und das Denken wird uns schon gar nicht abgenommen. Dafür wird der Datenschutz durch De-Anonymisieren verletzt. Und fair ist das alles nicht.
Big Data klingt nach einer Sache, die echt Spass macht! Zu Recht. Aber nicht immer rechtmässig. Und schon gar nicht immer im Interesse vieler direkt oder indirekt Betroffener. Manchmal nicht einmal im Interesse derer, die es tun. Wir sehen in drei Bereichen den Bedarf, über neue Regulierungen politisch zu diskutieren: Datenschutz, Diskriminierungsverbot und faire Wirtschaftsförderung.
4.1.
Datenschutz ^
4.1.1.
Respektierung des Datenschutzes in Organisationen unter Schweizer Recht ^
Aktuell bestehen die Hauptprobleme in der oben angesprochenen Auflösung der Abgrenzungen, die im DSG eine zentrale Rolle spielen. Unternehmen und andere Organisationen können sich von sich aus proaktiv damit auseinandersetzen – und wir empfehlen das vor allem in Bezug auf mögliche Reputationsrisiken – aber auch eine gesetzliche Verpflichtung zu dieser Auseinandersetzung ist denkbar und sollte diskutiert werden.
- Der erste Schritt zur Selbst- und zur Fremderkenntnis ist Transparenz darüber, was im Big Data Prozess passiert. Eine öffentliche Transparenz kollidiert aber mit berechtigten wie auch mit unberechtigten Geschäftsinteressen. Einerseits soll die Konkurrenz nicht sehen, wie man vorgeht, anderseits soll den Kunden nicht bewusst werden, was mit ihnen und ihren Daten geschieht. Bei lediglich organisationsinterner Transparenz sind die Interessenskonflikte geringer. Aufgabe der Rechtsinformatik-Forschung ist es, ein Konzept für Transparenz des Big Data Prozesses zu entwickeln, das alle berechtigten Interessen berücksichtigt. Anschliessend ist zu diskutieren, inwieweit die Schaffung von Transparenz von einem neuen Datengesetz, das das Datenschutzgesetz ergänzt11, verordnet werden soll und kann.
- Der notwendige zweite Schritt kann nicht staatlich verordnet, höchstens durch Information beworben werden. Er besteht in der Etablierung von Problembewusstsein in der Unternehmenskultur12. Wenn Vertreter von Big Data Technologieanbietern allen Ernstes noch immer Datenschutz als grosses Problem Europas anprangern13, zeigt das, wie hoch das Risiko ist, bei der Einführung von Big Data durch die Zusammenarbeit mit Anbietern eine datenschutzfeindliche Kultur sich einzuhandeln. Sinnvoll ist es darum, die Schaffung des Problembewusstseins mit einer Ausbildung der Mitarbeitenden zu verbinden.
- Auf der Basis von Transparenz und Problembewusstsein macht die Durchführung einer Problem- und Risikoanalyse Sinn, nebst nachfolgender technisch-organisatorischer Problembehebung. Beides setzt nicht zwingend die ersten beiden Schritte voraus, wird durch diese aber wesentlich erleichtert.
- Der vierte Schritt ist die Verankerung in den Führungsstrukturen der Organisation durch die Definition von Good Practices, die in den organisationsinternen Governance-Strukturen als Vorgaben oder Richtlinien eingebunden werden. Derzeit gibt es noch kein klares Bild, was denn konkret Good Practices in Bezug auf Big Data und die Wahrung der Privatsphäre Betroffener sind (abgesehen vom Schaffen von Problembewusstsein, das immer eine zentrale Bedeutung hat). Auch dies ist eine Forschungsaufgabe für die Rechtsinformatik. Die Einführung von neuer Bürokratie ist sicher NICHT die Lösung, aber eine saubere Definition von Rollen, Aufgaben und Prozessen kann von grossem Nutzen sein. Im Fall der Verwaltung wäre eine Identifikation solcher Good Practices durch eCH14 angezeigt.
- Sinnvoll ist es weiters, Audits ein- und durchzuführen, die prüfen, ob die noch zu definierenden Good Practice Standards eingehalten werden. Diskutierenswert ist es auch, diese für einige Akteure beziehungsweise in einigen Bereichen (wie dem Gesundheitswesen) verpflichtend vorzuschreiben. Allerdings sind solche Audits durchaus auch im Interesse der Betroffenen, weil sie sie vom Verdacht des vorsätzlichen Missbrauchs befreien.
Zum dritten und vierten Schritt: Eine strategische Option ist, sich einer freiwilligen Selbstbeschränkung zu unterwerfen und dies allenfalls einem Audit – wie im fünften Schritt besprochen – zu unterwerfen, um dann gegen innen (Mitarbeitende) und gegen aussen (Kunden, Investoren, Regulatoren) diese ethischen Standards als Marketinginstrument zu nutzen.
Die fünf Schritte haben keinen Anspruch auf Originalität. Weber und Oertly empfehlen konkret im gleichen Kontext wie hier die vier Schritte Risikoanalyse, Festlegung einer Strategie, Festlegung einer Bearbeitungspolitik und Einführung adäquater Verfahren15, was inhaltlich sehr nahe verwandt mit unseren Schritten 3 bis 5 ist. Obendrein betonen sie wie wir die grosse Bedeutung von Transparenz.
4.1.2.
Wahrung der Rechte des Individuums ^
Die Wirklichkeit untergräbt den Wert des Datenschutzes tagtäglich: Menschen geben über sich freiwillig vieles einer breiten Öffentlichkeit preis. Zudem akzeptieren sie grossmehrheitlich Geschäftsbedingung – oft mangels guter Alternativen – in denen sie Leistungsanbieter das Recht auf Weiternutzung ihrer Daten einräumen, beispielsweise im Kreditkartenzahlungsverkehr. Viele sind sich bei populären Internet-Dienstleistungen auch gar nicht bewusst, dass sie ein Tracking «einkaufen». Dies zu unterbinden ist in der Praxis sowieso äusserst schwierig, unter anderem weil es eine offene Frage ist, welche Gerichte jeweils zuständig sind.16 Es ist weiters bereits Folklore, dass die Überwachung durch Geheimdienste zwar nicht vollständig stattfindet, aber nicht vermieden werden kann und dass eine Weitergabe von geschäftsrelevanten Daten an Unternehmen und andere Organisationen nicht unwahrscheinlich ist. Anbieter im Internet identifizieren zudem einzelne Internetbrowser und legen zu diesen Historien an, die sämtliche Daten enthalten, die über den Browser bekanntgegeben werden. So können sie – mit einigen Ungewissheiten bezüglich der Zahl der Nutzer eines Browsers – ein Profiling durchführen und dafür oft sogar Daten von anderen Sites integrieren. Wir sind also bereits gläserne Bürger, Kunden, eventuell auch Patienten, Datenschutz hin oder her.
Um die Situation etwas zu verbessern bieten sich unter anderem staatliche Massnahmen in der Bildung und Rechtssetzung, sowie nutzerorientierte Dienstleistungen und technische Lösungskonzepte an.
- Öffentliche Information und öffentliche Bildungsangebote: Aufklären über die Risiken und das Befähigen zur informationellen Selbstbestimmung sollte Teil der Schulbildung sein und sinnvollerweise schon in der Primarschule beginnen.
- Schaffung von Informationsdienstleistern: Diese würden unsere Daten in unserem Sinn verwalten ähnlich wie Finanzdienstleister unsere finanziellen Mittel verwalten und können entweder kommerzielle Dienstleister, staatliche Dienstleister oder Genossenschaften sein. Ein Beispiel für letzteres ist der Versuch des Vereins «Daten und Gesundheit» (www.datenundgesundheit.ch) eine Gesundheitsdaten-Genossenschaft aufzubauen.
- Rechtliche Absicherung des Rechts auf Selbstnutzung der auf die eigene Person bezogenen Daten: Dies würde beinhalten, dass Datensammler die gesammelten Daten an die Betroffenen bei Nachfrage herausgeben müssten und wird vom Verein Daten und Gesundheit zur Diskussion gestellt.17
- Besserer Technischer Schutz: Privacy-by-Design ist ein Designprinzip und Privacy-by-Default ist ein Konfigurationsprinzip für Software. Ihre Umsetzung sind aktuell Gegenstand von Forschung und Entwicklung im Horizon2020-Programm der EU. Im Kern geht es dabei darum, ein Konzept für elektronische Identität beziehungsweise elektronische Identitäts- und Zugriffsmanagement (eID bzw. IAM) zu entwickeln, das dem Betroffenen maximale Kontrolle über die Verteilung von auf seine Person bezogenen Daten erlaubt. Dabei spielt insbesondere das Konzept einer nicht-verfolgbaren vertrauenswürdigen anonymen elektronischen Identität eine zentrale Rolle. Diese ist viel weitergehend realisierbar als man meint, hat aber ihre Grenzen bei der Benutzung digitaler Geräte.18
4.2.
Beschränkung der Datennutzung und Datenbereitstellung ^
4.2.1.
Beispiele möglicher Diskriminierungen ^
(1) Beispiel Verkauf
Wie oben schon kurz skizziert, ist es möglich aus dem Profiling die Zahlungsbereitschaft eines Kunden abzuleiten und so den Verkaufspreis zu maximieren, ohne den Kunden zu verlieren. Bei einer umfassenden Umsetzung zahlt jeder einen anderen Preis. Vorstellbar wäre aber auch, ein Rabattsystem mit individuellen Rabatten und generell höheren Preisen so einzuführen, dass der Kunde dem Anschein nach durch das Profiling profitiert.
(2) Beispiel Versicherungswirtschaft
Während früher nur Risiken für alle bzw. für relativ grosse Gruppen berechnet werden konnten, mit Ausnahmen wie beispielsweise zukünftige Gesundheitsrisiken im Fall früherer Krankheiten, so können durch Big Data individuelle Risiken einer Person gut geschätzt werden und diese Schätzungen werden immer mehr zur Basis der Kostenfestlegung bei Versicherungen. Da die allgemein beschaffbaren Daten über eine Person oft nicht wirklich ausreichen, bieten Versicherungen mittlerweile Preisnachlässe für jene an, die sich von ihnen überwachen lassen, beispielsweise bei Autoversicherungen. Diese Entwicklung hat mehrere kritische Aspekte, die wir teilweise schon besprochen haben: die Auflösung des Solidaritätscharakters von Versicherungen, eine Preisdiskriminierung die auf dem Verhalten anderer beruht (weil selbst beim Fahrtentracking bei Autoversicherungen ja nicht nur das Fahrverhalten beurteilt wird, sondern auch die Risikohäufigkeiten auf den befahrenen Strecken), die Infragestellung der Versicherungsbranche an sich (weil Versicherungen für ein berechnetes Schicksal wenig Sinn machen) und den Aufbau einer Überwachungswirtschaft als Pendant zum Überwachungsstaat.
(3) Beispiel Personalführung
In Zukunft wird es möglich sein, aus den Daten über die Gene eines Menschen viele Schlussfolgerungen über seine Krankheitsrisiken abzuleiten. Wer gute Gene hat, hat deshalb einen Anreiz, genau dies bei einer Bewerbung anzugeben, in welcher Form auch immer. Doch auch wenn die Daten über die Gene von einigen freiwillig bereitgestellt werden, schafft das in den meisten Fällen Nachteile für andere Bewerber und Mitarbeiter des Arbeitgebers, die nicht ebenfalls Daten bereitstellen und ebenfalls gute Gene besitzen.
4.2.2.
Schlussfolgerungen ^
Die Zusammenhänge sind allerdings komplex. Es empfiehlt sich, regulierende Eingriffe ins System mit Bedacht durchzuführen. Die scheinbare Langsamkeit der politischen Prozesse ist hier ein Vorteil, sofern früh – also jetzt – mit der politischen Diskussion begonnen wird. Sinnvoll ist jedenfalls Konsumentenschutz und Preisüberwachung für das Thema zu sensibilisieren und eventuell auch von Seiten TA-Suisse19 die Entwicklung zu monitoren.
4.3.
Staatliche Förderung von Big Data ^
- Gerade aus Sicht von Privacy-by-Design Überlegungen, wird eine sichere, skalierende und günstige eID-Lösung benötigt, die das IAM optimal im Sinne aller rechtmässig Betroffenen unterstützt und gleichzeitig Missbrauch weitestmöglich einschränkt.
- Eine wesentliche Quelle für das Big Data Ökosystem sind Verwaltungsdaten, die als Open Government Data zur Sekundärnutzung veröffentlicht werden
- Big Data kann auch von der Verwaltung und in vielen anderen Bereichen des öffentlichen Sektors eingesetzt werden, der damit nicht nur Datenlieferant ist für das Ökosystem, sondern auch ein grosser Nutzer von Daten und Big-Data-Diensten des Ökosystems
Zum zweiten Punkt: Der Bundesrat hat am 2014 eine Big Data Strategie beschlossen22 und fördert seither aktiv die Bereitstellung von Big Data. Es empfiehlt sich, insbesondere bei der Veröffentlichung von Wirtschaftsdaten vorwärts zu machen.
Zum dritten Punkt: Aus Sicht der Wirtschaftspolitik auf Bundesebene sollte man als die drei wichtigsten Stakeholder von Big Data die Unternehmen, die Forschungsinstitutionen und das WBF selber ansehen. Aber auch für alle anderen Politikbereiche wird Big Data zukünftig ein wichtiges strategisches Instrument sein. Bei der Energie- und Verkehrspolitik ist das offensichtlich, ebenso bei der Gesundheitspolitik und in der Stadtentwicklung, aber es gilt praktisch für alle Politikbereiche. Deshalb sollte Big Data auch bei der Weiterentwicklung der öffentlichen Verwaltung eine zentrale Rolle spielen – vor allem um die Verwaltung effektiver zu machen und Fehlplanungen zu vermeiden. Wie Dumermuth an der Big Data Governance Tagung 2014 in Bern ausführte23, sollte die Verwaltung in die Ausbildung investieren, eine Strategie entwickeln und Governance-Leitlinien für den Einsatz von Big Data formulieren. Das Nutzenpotential ist sehr gross für die Verwaltung, wie die Risiken vielfältig sind, weshalb es wenig sinnvoll ist nur ein Laissez-faire zu praktizieren. Mindestens mittelfristig sollte es auch möglich sein, die szenario-basierte Langfristplanung des Bundesrats um Big Data Prognosen zu erweitern, beziehungsweise big-data-basiert die Szenarien zu fokussieren.
4.4.
Die Rolle der Wissenschaft ^
Wir haben oben schon angesprochen, dass die Förderung von Wissenschaft sinnvoll ist. Doch wie so oft in der Geschichte ist die Rolle der Wissenschaft ambivalent und es besteht ein grosses Risiko, dass am Ende sie selber unter die Räder kommt.
Ein grosser zukünftiger Problembrocken ist beispielsweise IoT, das Internet der Dinge. Einige diesbezügliche Pläne von Wissenschaftlern und Entwicklern – an Hochschulen wie in der Privatwirtschaft – würden gut zu einem James Bond Film-Bösewicht alten Stils passen. Das soll (um nur ein Beispiel aus mündlicher Quelle zu bringen ) in Zukunft beispielsweise eine Gesundheitslandkarte für die Welt erstellt und Arbeitgebern zur Verfügung gestellt werden, damit diese wissen, wie gesund oder krank die Menschen in einem Stadtviertel oder Dorf sind, aus dem ein Stellenbewerber kommt. Das Ziel der Innovation: Förderung von Diskriminierung im Arbeitsmarkt (womit man viel Geld verdienen will), die vermutliche Wirkung fortschreitende Ghettoisierung. Leider ist es in der IoT-Community weit verbreitet, Ausnahmen bestätigen wie immer die Regel, staatliche Regulierung als Behinderung des Fortschritts abzulehnen. Dies geschieht unter anderem gern mit dem Argument, dass auch das Internet sich ohne staatliche Regulierung prächtig entwickelt hat. Vergessen wird dabei, wie gross die Geschwindigkeitsunterschiede zwischen beiden Fällen sind und wie sehr sich die Ziele unterscheiden. Das Internet brauchte lange und dahinter standen in den ersten zwanzig Jahren vor allem idealistische Ziele (von Zusammenarbeit in der Wissenschaft bis zum Kampf gegen die allgegenwärtige Werbung) und militärische Ziele (zuverlässige Kommunikationsnetze). Hinter Big Data stehen kommerzielle Ziele und Machtinteressen bis hin zum Versuch, die Welt zu kontrollieren. Darum ist bei Big Data ein Laissez-faire viel gefährlicher als es einst beim Entstehen des Internets war.
Allerdings steht den oben skizzierten Umtrieben eine wissenschaftliche Forschung gegenüber, die genau das Gegenteil anstrebt, beispielweise die bereits stattfindende datenbasierte Diskriminierung in der Arbeitswelt aufzuzeigen.24 Wir beobachten also ein grosses Spannungsfeld zwischen einer ohne ethischen Bedenken vorwärts strebenden, oft durch finanzielle Motive getriebenen, Big Data / IoT Forschung und Entwicklung auf der einen Seite und einer Nutzung der dabei entwickelten Technologien durch andere Forschende, um den Missbrauch aufzuzeigen. Hier wäre es dringend notwendig, dass wenigsten die Forschenden an den Hochschulen die ethischen Aspekte sehen und diskutieren.
Das eigentliche Risiko für die Wissenschaft ist, dass sie angesichts ihrer Kommerzialisierung und dem wachsenden Drittmitteldruck zu einem Dienstleistungssektor wird, dessen Arbeitnehmer die soziale Leiter immer weiter hinuntersteigen, weil in den Augen der Öffentlichkeit nicht das Erfinden genialer Algorithmen sondern das Geld Machen mit den Algorithmen wertvoll ist. Je weniger ethisch reflektiert Wissenschaftler arbeiten, desto grösser scheint uns das Risiko, dass dieser Abstieg stattfinden wird.
5.
Zusammenfassung ^
Big Data bringt grossen Nutzen, geht aber mit vielen nicht ganz unkritischen Paradigmenwechseln einher, die das Auftreten von verführerischen Schimären und Illusionen fördern. Zwei Hauptprobleme stellen das De-Anonymisierungspotential des Big Data Profiling und das Diskriminierungsrisiko dar. Ersteres lässt sich mit rein rechtlichen Massnahmen kaum befriedigend lösen, sondern benötigt einen transdisziplinären Ansatz, zweiteres verlangt nach einem breiten politischen Diskurs. Neben der Verhinderung des Missbrauchs sollte der Staat auch über positive Fördermassnahmen für das entstehende Big Data Ökosystem nachdenken. Für die Rechtsinformatik ergeben sich aus diesen Überlegungen neue Forschungsfelder, insbesondere in den Bereichen Transparenz25, Good Practices bei der verantwortungsvollen Nutzung von Big Data in der Praxis und Nutzung des Internets der Dinge. Da wir erst am Anfang der breiten Big Data Nutzung stehen, müssen zwar viele Aussagen in diesem Beitrag als vorläufige Beurteilungên angesehen werden, doch der politische Diskurs über Big Data ist schon jetzt möglich und sinnvoll – und in manchen Bereichen sogar dringend notwendig!
Prof. Dipl. Ing. Dr. phil. Reinhard Riedl, Wissenschaftlicher Leiter des Fachbereichs Wirtschaft, Berner Fachhochschule (BFH), reinhard.riedl@bfh.ch; http://www.wirtschaft.bfh.ch.
- 1 Mathematisch betrachtet ist traditionelles IR ein Spezialfall von klassischem Big Data (weil der Fitness-Wert von Dokumenten bezogen auf eine Suchanfrage geschätzt wird).
- 2 Vergleiche: Mathys, Roland, Was bedeutet Big Data für die Qualifikation als besonders schützenswerte Personendaten?, in: Jusletter IT 21. Mai 2015.
- 3 Koval, Peter / Riedl, Reinhard, Zur 2.0 (zweiten) Ordnung von E-Government, Proceedings IRIS 2009, Salzburg (2009).
- 4 Vortrag von Frau Bundeskanzlerin Corina Casanova beim SGVW Netzwerkanlass am 23. Oktober 2014 auf dem Landgut Lohn
- 5 Lanier, Jaron, Who Owns the Future, 53ff, Simon and Schuster, New York (2013)
- 6 Chaum, David, Security Without Identification: Transaction Systems to Make Big Brother Obsolete. Communications of the ACM, 28(10):1030–1044, October 1985.
- 7 Auerbach, Niklas, Trustworthy Anonymous Digital Identity in E-Government, Dissertation, Universität Zürich (2004).
- 8 Beispielhaft wird dies erläutert in Offenhuber, Dieter / Ratti, Carlo, Drei Mythen über Smart Cities, In: Geiselberger, Heinrich und Moorstedt, Tobias, Big Data – Das neue Versprechen der Allwissenheit, Suhrkamp, edition unseld (2013).
- 9 Weichert, Thilo, Das Ende der Theorie – die Datenschwemme macht wissenschaftliche Methoden obsolet, In: [FN 7].
- 10 Interview mit Greenfeld, Adam, Smart Phone, Smart Bomb, Smart City, In: Das grosse Rauschen: Warum die Datengesellschaft mehr Menschenverstand braucht, Verlag Neue Zürcher Zeitung (2013).
- 11 Epiney, Astrid, Big Data und Datenschutzrecht: Gibt es einen gesetzgeberischen Handlungsbedarf?, in: Jusletter IT 21. Mai 2015.
- 12 Eine gute Definition von Unternehmenskultur findet sich im Klassiker Schein, Edgar H., Organizational Culture and Leadership, 4th Edition, John Wiley & Sons (2010): «[...] ein Muster gemeinsamer Grundprämissen, das die Gruppe bei der Bewältigung ihrer Probleme externer Anpassung und interner Integration erlernt hat, das sich bewährt hat und somit als bindend gilt; und das daher an neue Mitglieder als rational und emotional korrekter Ansatz für den Umgang mit Problemen weitergegeben wird.»
- 13 Dies geschieht vor allem im Lobbying off records.
- 14 eCH ist die Schweizer Standardisierungsorganisation für E-Government, www.ech.ch.
- 15 Weber, Rolf H. / Oertly, Dominic, Aushöhlung des Datenschutzes durch De-Anonymisierung bei Big Data Analytics?, in: Jusletter IT 21. Mai 2015.
- 16 http://www.zeit.de/digital/datenschutz/2015-04/facebook-datenschutz-klage-schadensersatz-oesterreich, ale Internetquellen zuletzt besucht am 17. Mai 2015.
- 17 Gächter, Thomas, Vortrag Das Recht auf Kopie – Grundvoraussetzung für die informationelle Selbstbestimmung am 26. Januar 2015 bei einer Veranstaltung des Vereins im Hotel Kreuz in Bern.
- 18 Roduner, Christof, Citizen Controlled Data Protection in a Smart World, Master’s Thesis, University of Zurich (2003) http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.202.456&rep=rep1&type=pdf.
- 19 TA-Suisse ist das Kompetenzzentrum für Technologiefolgenabschätzung der Schweizer Akademien der Wissenschaften, https://www.ta-swiss.ch/.
- 20 Wie Big Data ist auch der Begriff des soziotechnischen Ökosystems nicht klar definiert. Wir verstehen darunter das Zusammenspiel der technischen Ressourcen und der sie nutzenden Akteure im politisch-rechtlichen, sozialen und ökonomischen Kontext.
- 21 Da dies auch für ein einzelnes Land kaum möglich ist, wenn die internationale Zusammenarbeit nicht blockiert werden soll, beteiligt sich die Schweiz am europäischen Large Scale Pilot STORK 2.0, https://www.eid-stork2.eu/, und leitet in diesem Projekt den e-Banking Piloten und das Service-Design.
- 22 http://www.egovernment.ch/umsetzung/00881/00883/index.html?lang=de.
- 23 Siehe http://www.rechtsinformatik.ch/Unterlagen_2014/Dumermuth_Tagung%202014.pdf. Martin Dumermuth, Chancen und Risiken von Big Data (Podcast), in: Jusletter IT 21. Mai 2015.
- 24 Am 27. Bis 29. August 2015 findet die Konferenz «Discrimination in the Labor Market» in Bern statt. http://www.wirtschaft.bfh.ch/de/forschung/institut_unternehmensentwicklung/veranstaltungen/conference_lm_discrimination.html.
- 25 Transparenz war schon 2013 Generalthema der Rechtsinformatiktagung IRIS, http://www.univie.ac.at/ri/IRIS2013/.





