1.
Einführung ^
Schon 1986 hielten Fiedler und Traunmüller1 einen Vortrag zu juristischen Expertensystemen. Zu jener Zeit wurden an Expertensysteme, nicht nur für juristische Anwendungsgebiete, große Erwartungen gerichtet. Man versuchte, auch spezifische Programmiersprachen für solche Expertensysteme zu entwickeln.2
2.
Aktuelle IT-Einsatzfelder im Recht ^
Der IT-Einsatz in Recht und Verwaltung ist – auch ganz ohne Expertensysteme – in den letzten Jahrzehnten rasant angestiegen. Konzentrierte man sich in den ersten Jahrzehnten überwiegend auf «innerorganisatorische» Anwendungsfelder, so ist in den letzten Jahren vermehrt auch die Kommunikation mit den Bürgern Gegenstand der Automatisierung geworden. Damit einher geht der Begriffswandel von der Rechts- und Verwaltungsinformatik hin zu E-Government, E-Administration, E-Democracy oder E-Voting. Nachdem im wirtschaftlichen Bereich die E-Terminologie zunehmend von «digital» abgelöst wird (E-Business → Digital Business) und die EU-Kommission einen Kommissar für die Digitale Agenda bzw. nunmehr Digitale Wirtschaft und Gesellschaft benennt, werden wir wohl auch hier demnächst von Digital Government sprechen.3
2.1.
Dokumentenmanagement ^
- gleichzeitig von mehreren Personen gelesen werden können – und damit Prozessabläufe beschleunigt werden, in dem z.B. Stellungnahmen parallel eingeholt werden können;
- schneller von einem Ort zum anderen transportiert werden können und damit der Aktenlauf dramatisch verkürzt werden kann;
- die Dokumente automatisch mit Metadaten wie z.B. Erstellungsdatum, letztes Änderungsdatum, Versionsnummer und der jeweilige Bearbeiter sowie zusätzliche durch den Bearbeiter eingebbare Metadaten (z.B. Klassifizierung, Beschlagwortung) versehen werden können, die einerseits der Suche, andererseits auch der Information über den Bearbeitungsstand dienen.
2.2.
Berechnungssysteme ^
2.3.
Transaktionssysteme ^
2.4.
Web 2.0-Anwendungen ^
2.5.
Zwischenfazit ^
Da nun eine Reihe von Vorteilen bestehender IT-Systeme aufgezählt wurde, stellt sich die Frage: «Worin besteht dann das Problem, das durch semantische Technologien gelöst werden könnte?» Nun – alle diese Systeme bilden eine Unterstützung für den Experten, der über das Wissen bereits verfügt – oder in der Lage ist, sich dieses aus den Dokumenten zu erschließen. Wieso ist eine Website wie help.gv.at notwendig – oder wieso kann nicht wenigstens der Text auf der Website automatisch aus dem RIS generiert werden? Das geht deswegen nicht, weil ein Computerprogramm typischerweise nicht in der Lage ist, ein Dokument inhaltlich «zu verstehen». Auch daran wird seit langem gearbeitet – und wenn Sie an den Google-Übersetzungsdienst denken, dann wurden auch Fortschritte erzielt. Aber ehrlich – würden Sie darauf vertrauen, dass ein vergleichbares System rechtlich korrekte Entscheidungen treffen wird?
3.1.
Idee des Semantic Web ^
3.2.
Das Vorfeld des Normsetzungsprozesses ^
3.3.
Normsetzung = Modellbildung ^
Allerdings vermeidet der Ansatz, bereits das zu lösende Problem semantisch zu modellieren, eine sehr anspruchsvolle Aufgabe, die sich sonst bei der Formalisierung von Rechtsnormen stellt, nämlich das der Auslegung unbestimmter Rechtsbegriffe.8
3.4.
Der Aufwand semantischer Modellierung ^
Mit den heute verfügbaren Hilfsmitteln stellt die semantische Modellierung immer noch einen großen Aufwand dar, wie aus dem folgenden Beispiel deutlich wird. §§ 1 und 2 EStG enthalten die grundlegenden Regeln der persönlichen und sachlichen Steuerpflicht. Soll das in diesen Formulierungen repräsentierte Wissen auch in maschinenverständlicher Form dargestellt werden, dann dauert das wesentlich länger als die Formulierung des bloßen Textes – und ist auch für den Menschen schwerer lesbar als der Text in der natürlichen Sprache.
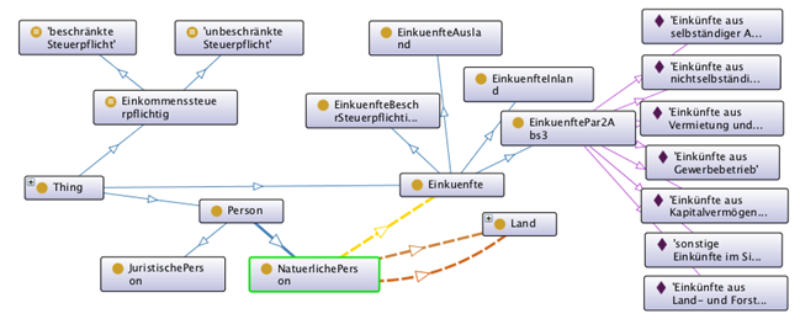
Abbildung 1: Modelliertes Wissen

Abbildung 2: Implizites Wissen

4.
Einsatzgebiete ^
4.1.
Eng abgegrenzte Rechtsmaterien mit hoher Wiederverwendbarkeit ^
Auch die Curricula an Universitäten gehören in diese Kategorie; ein Curriculum ist gem. § 51 Abs. 2 Z. 24 «die Verordnung, mit der das Qualifikationsprofil, der Inhalt und der Aufbau eines Studiums und die Prüfungsordnung festgelegt werden». Sie sind insofern eng abgegrenzt, als sie letztendlich nur eine Frage beantworten: Hat jemand den Anspruch auf einen akademischen Grad erworben.
4.2.
Abrechnungsorientierte Rechtsmaterien ^
5.
Zukünftige Entwicklungen ^
6.
Fazit und Ausblick ^
Johann Höller, Professor, Johannes Kepler Universität Linz, Institut für Datenverarbeitung in den Sozial- und Wirtschaftswissenschaften, Altenberger Straße 69, 4040 Linz, AT, johann.hoeller@jku.at; http://www.idv.edu
Martin Stabauer, Universitätsassistent, Johannes Kepler Universität Linz, Institut für Datenverarbeitung in den Sozial- und Wirtschaftswissenschaften, Altenberger Straße 69, 4040 Linz, AT, martin.stabauer@jku.at; http://www.idv.edu
- 1 Fiedler, Herbert/Traunmüller, Roland, Formalisierung im Recht und Juristische Expertensysteme, in: Informatik-Anwendungen — Trends und Perspektiven Berlin, 6.–10. Oktober 1986 Proceedings, Springer Berlin Heidelberg, S. 367–382 (1986).
- 2 Gordon, Thomas F./Quirchmayr, Gerald, OBLOG – eine Programmiersprache für juristische Expertensysteme, in: Erdmann, Ulrich/Fiedler, Roland/Haft, Fritjof/Traunmüller, Roland (Hrsg.), Computergestützte juristische Expertensysteme, S. 123–134 (1986).
- 3 Im Vorwort zum Jusletter IT vom 11. Dezember 2014 bezeichnen Schweighofer/Kummer ebenfalls bereits den «digitalen Juristen» als Leitthema, der fähig sein muss, sich in dieser digitalen Welt zu bewegen. Der vorliegende Ansatz konzentriert sich auf die praktische Umsetzbarkeit und nutzt nur Teile der theoretischen Modelle, die die Rechtsinformatik entwickelt hat. Daher wird hier – auch aus Platzgründen – auf eine Wiedergabe der entsprechenden Literatur verzichtet. Diese findet sich etwa im Beitrag Stabauer, Martin/Höller, Johann, Ein integrativer Ansatz zur semantischen Modellierung von Rechtstexten – das Zusammenwirken von Softwareentwicklung und Ontologien, in: Jusletter IT 11. Dezember 2014.
- 4 Die RIS-Daten sind zwar auch in maschinenlesbarem Format im Rahmen des Open Data Portals (www.data.gv.at) verfügbar, allerdings genügen die vorhandenen Metainformationen den Anforderungen für linked open data nicht.
- 5 Berners-Lee, Tim/Hendler, James/Lassila, Ora, The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities, in: Scientific American, 284 (5), S. 34–43 (2001).
- 6 Ein vergleichbarer Ansatz – allerdings auf der Ebene der Sachverhaltsmodellierung – findet sich in: Raabe, Oliver/Baumann, Christian/Funk, Christian/Wacker, Richard/Oberle, Daniel, Lawful service engineering – Formalisierung des Rechts im Internet der Dienste, in: Jusletter IT 1. September 2010, Rz 11 (2010).
- 7 http://www.wolframalpha.com, Abruf am 8. Januar 2015 (2015).
- 8 Vgl. Raabe, Oliver/Baumann, Christian/Funk, Christian/Wacker, Richard/Oberle, Daniel, Lawful service engineering – Formalisierung des Rechts im Internet der Dienste, in: Jusletter IT 1. September 2010, Rz 13 f. (2010).
- 9 Vgl. https://www.wien.gv.at/stadtentwicklung/flaechenwidmung/planzeigen/planlesen.html, Abruf am 7. Januar 2015 (2015).
- 10 Stabauer, Martin, Der Nutzen semantischer Technologien bei Erstellung und Pflege von Rechtstexten am Beispiel von Curricula, Linz (2014).
- 11 Stabauer, Martin/Höller, Johann, Verordnungen erstellen ohne Rechtskenntnisse – Demonstration eines Curriculum-Designprozesses, IRIS 2015.
- 12 http://semanticweb.com/gartner-reports-internet-things-tops-technology-hype-cycle_b44134, Abruf am 8. Januar 2015 (2015).
- 13 Vgl. o. V., Der Kampf um die Daten, in: auto touring, November 2014, S. 18; http://ereader.autotouring.at/reader/autotouring/OOE/2014/11#18, Abruf am 7. Januar 2015 (2014).
- 14 «Digitale Technologien verändern unsere Welt und unser Leben – und zwar komplett.»: aus Tost, Daniel, Digitalkommissar Oettinger: Gründlichkeit vor Schnelligkeit, in: http://www.euractiv.de/sections/europawahlen-2014/digitalkommissar-oettinger-gruendlichkeit-vor-schnelligkeit-308791, Abruf am 7. Januar 2015 (2015).





