1.
Einführung ^
Der entwickelte integrative Ansatz1 vereint klassische Methoden aus der Softwareentwicklung mit semantischen Modellierungswerkzeugen und ermöglicht so das praxisnahe Umsetzen von Rechtstexten in Ontologien. Wir stellen den angesprochenen Ansatz, bestehend aus einem semantischen Grundmodell und einem dazu passenden Vorgehensmodell, vor und demonstrieren seine Umsetzbarkeit an Hand eines Fallbeispiels von universitären Curricula nach österreichischem Recht.
1.1.
Curricula nach österreichischem Recht ^
1.2.
Normsetzungsprozess und Zusammenarbeit ^
2.
Semantische Modellierung ^
2.1.
Grundmodell ^
Als Ausgangsbasis wird das von Stabauer/Höller6 beschriebene semantische Grundmodell in leicht modifizierter Form herangezogen und um notwendige Ergänzungen für den Einsatz bei Curricula erweitert. Das so entstandene Framework trägt den Namen Curriculum Modeling Language, kurz CML. Es beinhaltet neben Klassen für die Struktur des Rechtstextes und aller Bestandteile von Curricula auch weitere Ontologien zur Abbildung von Universitäten und anderer Bildungseinrichtungen, von Personen, Regeln, Mustertexte und Übersetzungen und Mappings zu externen Ontologien.
2.2.
Curriculum ^

2.3.
Fächer, Module, Lehrveranstaltungen ^

Die vorangehende Auflistung zeigt unter anderem, dass mit CML auch natürliche Personen modelliert werden. Hierbei handelt es sich vornehmlich um Personen mit besonderen Berechtigungen, wie in diesem Fall den Verantwortlichen für eine Lehrveranstaltung. Die so modellierten Informationen können beispielsweise für eine Authentifizierung beim Bearbeiten von Daten in einer speziellen Benutzeroberfläche genutzt werden.
2.4.
Textbausteine ^
§ 10 Akademischer Grad
(1) An die AbsolventInnen des Masterstudiums Webwissenschaften ist der akademische Grad «Master of Science», abgekürzt «MSc» oder «MSc (JKU)», zu verleihen.
(2) Der Bescheid über den akademischen Grad wird in deutscher Sprache und englischer Übersetzung ausgefertigt.

Mit webwi:AkadGrad wird zunächst der Paragraph 10 modelliert, welcher dem entsprechenden Curriculum direkt untergeordnet wird. Das Objekt wird als Paragraph mit der Bezeichnung «Akademischer Grad» und der Reihenfolge 10 definiert.
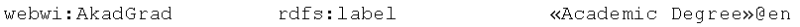
Auch die Inhaltselemente mit dem eigentlichen Text des Bausteins können auf diese Weise übersetzt und so mehrere Sprachen in einer einzigen Ontologie mit einer gemeinsamen Struktur abgespeichert werden. Dies hat unter anderem den großen Vorteil, dass spätere Änderungen an nur einer Stelle durchgeführt werden müssen, um dennoch alle modellierten Sprachversionen einzubeziehen.
2.5.
Beziehungen zu externen Ontologien ^

Die zweite an dieser Stelle erwähnte externe Ontologie ist das Legal Knowledge Interchange Format, kurz LKIF, das vom EU-weit aktiven Estrella Konsortium («European Project for Standardized Transparent Representations in order to Extend Legal Accessibility») implementiert wurde und sich inzwischen zu einer Standardsprache zur Modellierung von juristischem Wissen entwickelt hat. LKIF berücksichtigt dabei spezifische Terminologie, Regeln und auch normative Aussagen. Die Regeln erweitern hierbei den «Semantic Web Rule Language» (SWRL) Standard9, der sich wiederum selbst aus OWL und RuleML («Rule Markup Language»)10 zusammensetzt.
3.
Benutzerunterstützung ^
3.1.
Weitergehende Automatisation ^

Somit bleibt für den texterzeugenden Algorithmus die Aufgabe, die Variablen wie [CURRNAME] oder [AKADGRADLANG] durch die entsprechenden Werte, die beim modellierten Objekt des Curriculums abgespeichert sind, zu ersetzen. Dies kann auch mehrsprachig erfolgen, indem im Falle des nicht-deutschsprachigen Texts für jede Variable der Inhalt des jeweiligen rdfs:label eingesetzt wird.

Die texterzeugenden Algorithmen geben dann in einer formatierten Liste die entsprechenden Daten (Name und ECTS) dieser Bausteine aus:

Abbildung 1: cml:listeUntergeordnete
3.2.
Regelwerk ^
LV(?lv) ⋀ uebergeordnet(?lv,?baustein) ⇒BausteinUngueltig(?lv)
Allerdings stößt diese Sprache bei manchen Anwendungsgebieten an ihre Grenzen. Diese Grenzen hängen häufig mit der in OWL gültigen Open World Assumption (OWA) zusammen. Diese besagt, dass zwischen nicht vorhandenem und negativem Wissen unterschieden werden kann, da im Unterschied zu geschlossenen Systemen aus einer fehlenden Information nichts geschlossen wird.11 Das bedeutet aber, dass beispielsweise summenbasierte Regeln schwierig werden, da nie festgestellt werden kann, ob die momentan vorhandenen Teile auch tatsächlich alle sind, oder ob im offenen System noch ein weiteres Teil auftaucht.
3.3.
Benutzeroberflächen ^
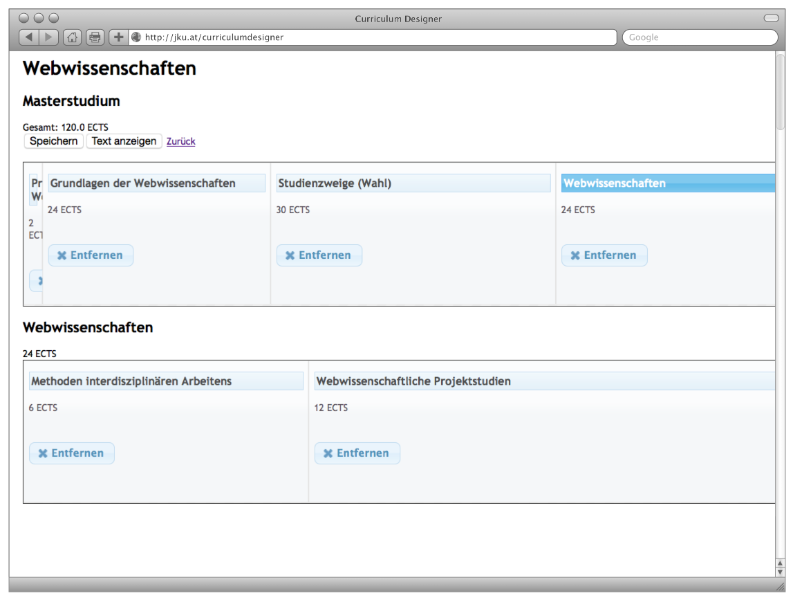
Abbildung 2: Weboberfläche Hierarchie
4.
Fazit und Ausblick ^
Johann Höller, Professor, Johannes Kepler Universität Linz, Institut für Datenverarbeitung in den Sozial- und Wirtschaftswissenschaften, Altenberger Straße 69, 4040 Linz, AT, johann.hoeller@jku.at; http://www.idv.edu
Martin Stabauer, Universitätsassistent, Johannes Kepler Universität Linz, Institut für Datenverarbeitung in den Sozial- und Wirtschaftswissenschaften, Altenberger Straße 69, 4040 Linz, AT, martin.stabauer@jku.at; http://www.idv.edu
Es sei darauf hingewiesen, dass bei der Entwicklung dieses Beitrags die praktische Umsetzbarkeit im Vordergrund stand. Zur theoretischen Einordnung siehe etwa Fußnote 6.
- 1 Vgl. Stabauer, Martin, Der Nutzen semantischer Technologien bei Erstellung und Pflege von Rechtstexten am Beispiel von Curricula, Linz (2014).
- 2 Vgl. ECTS-Leitfaden, http://ec.europa.eu/education/tools/docs/ects-guide_de.pdf, Abruf am 15. Dezember 2014 (2009).
- 3 Vgl. Höller, Johann/Stabauer, Martin, IT in der Normsetzung – Semantische Technologien als Lösungsansatz, IRIS (2015).
- 4 Vgl. http://www.w3.org/TR/owl2-overview, Abruf am 15. Dezember 2014 (2012).
- 5 Vgl. Becket, D. et al., http://www.w3.org/TR/turtle, Abruf am 15. Dezember 2014 (2004).
- 6 Vgl. Stabauer, Martin/Höller, Johann, Ein integrativer Ansatz zur semantischen Modellierung von Rechtstexten, in: Jusletter IT 11. Dezember 2014.
- 7 Vgl. http://dbpedia.org, Abruf am 15. Dezember 2014.
- 8 Vgl. http://www.estrellaproject.org/?page_id=5, Abruf am 15. Dezember 2014.
- 9 Vgl. Horrocks, Ian et al., SWRL: A Semantic Web Rule Language – Combining OWL and RuleML, http://www.w3.org/Submission/SWRL, Abruf am 15. Dezember 2014 (2004).
- 10 Vgl. Boley, Harold et al., Design Rationale of RuleML – A Markup Language for Semantic Web rules. In: Proceedings of the Semantic Web Working Symposium, S. 381–401 (2001).
- 11 Vgl. Grimm, Stephan, Knowledge Representation and Ontologies. In: Scientific Data Mining and Knowledge Discovery – Principles and Foundations, Springer, S. 210 ff. (2010).
- 12 Vgl. O’Connor, Martin J./Das, Amar K., SQWRL: A Query Language for OWL. In: OWLED’09 (2009).
- 13 Vgl. http://protege.stanford.edu, Abruf am 15. Dezember 2014.





