1.
Suche bei Swisslex ^
2.1.
Crosslinguale Suche ^
Die Schweiz hat vier Landessprachen: deutsch, französisch, italienisch und räteromanisch. Bei Swisslex sind 70% der Inhalte in deutscher, 26% in französischer und 4% in italienischer Sprache. In diesem Kontext ist es unabdingbar, dass Swisslex eine crosslinguale Suche anbietet, d.h. dass z.B. mit deutschen Suchbegriffen auch die entsprechenden französisch- oder italienisch-sprachigen Dokumente gefunden werden können.
2.2.
Normalisierung der Flexionsformen ^
Suchbegriffe sollen nicht nur in der eingegebenen Form sondern auch in anderen Flexionsformen gefunden werden. So soll z.B. mit unberechtigt auch unberechtigter, unberechtigte oder unberechtigtes gefunden werden. Zudem sollen nicht nur die sich durch Endungen unterscheidenden Flexionsformen, sondern auch im Wortstamm abgewandelte Formen wie ging beim Verb gehen gefunden werden. Begriffe wie Oberst und oberster unterscheiden sich zwar nur in ihrer Endung, gehören morphologisch jedoch nicht zusammen und sollen daher unterschieden werden. Bei Begriffen wie Garten und Betrug, die gleichzeitig Substantive als auch Verbformen von garen und betragen sind, sind die Verben meist nicht mit gemeint. Die alleinige Anwendung morphologischer Regeln reicht hier nicht.
2.3.
Neue Rechtschreibung ^
2.4.
Suchlogik ^
2.5.
Mehrwortbegriffe ^
Es gibt viele Fachtermini, die aus mehreren Wörtern bestehen, z.B. ungerechtfertigte Bereicherung. Werden diese eingegeben, sollen Dokumente gefunden werden, in denen diese Fachtermini ggf. auch in flexierter Form wie z.B. einer ungerechtfertigten Bereicherung im Zusammenhang enthalten sind. Gleichzeitig sollen bei der Suche mit ungerechtfertigte Bereicherung Dokumente, in denen die einzelnen Wörter des Mehrwortbegriffs verteilt an unterschiedlichen Stellen im Dokument enthalten sind, wie z.B. ungerechtfertigte Kritik und persönliche Bereicherung, nicht gefunden werden.
2.6.
Sortierung und Ranking ^
Für Juristeninnen und Juristen ist es wichtig, dass die neuesten Dokumente in der Trefferliste nach oben sortiert werden. Zwar bietet Swisslex auch eine Sortierung nach «Relevanz» an, diese wird jedoch nur selten verwendet. Daher ist eine recht unscharfe Suche, verbunden mit einem guten Relevanzranking wie es z.B. Google macht2, für Swisslex weniger geeignet.
2.7.
Transparenz ^
2.8.
Fine-Tuning ^
3.
Architektur des Lösungsansatzes ^
Die Suchbegriffe werden dann auf ihre linguistischen Grundformen zurückgeführt; aus Klägers wird damit z.B. Kläger. Dies geschieht gleichermassen bei den Suchbegriffen wie bei den Begriffen in den Dokumenten. Dadurch werden z.B. Regresses und Regresse auf das Lemma Regress normalisiert. Damit kann bei der Suche mit verschiedenen Flexionsformen jede Flexionsform eines Begriffs als Suchbegriff eingegeben werden, und es werden alle Dokumente gefunden, die eine der Flexionsformen des Begriffes enthalten.
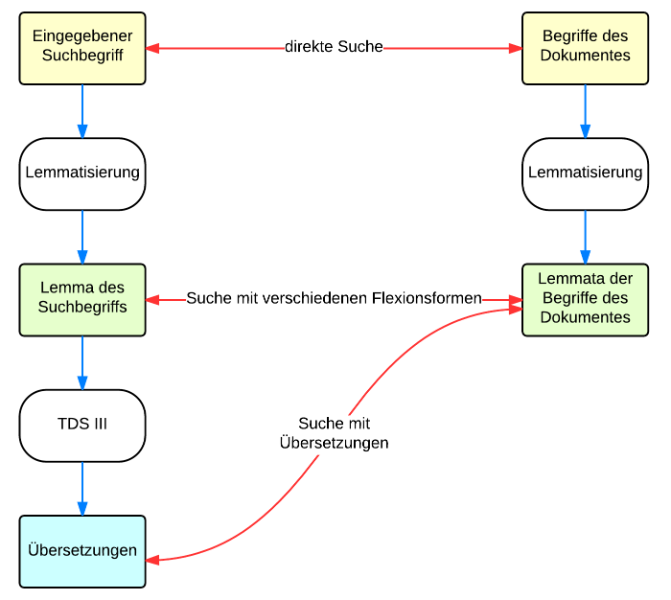
Abbildung 1: Basisarchitektur – Verarbeitung der Suchbegriffe (links) und Indexierung der Dokumente (rechts)
Schliesslich werden die Suchbegriffe bzw. deren Grundformen noch übersetzt. Damit findet z.B. Regress auch Dokumente in italienischer Sprache, die Regresso enthalten. Dies ist ein gängiger Ansatz für die crosslinguale Suche.8
4.
Anpassungen des Lösungsansatzes ^
Der bislang beschriebene Ansatz bietet einen guten Recall, d.h. die meisten relevanten Dokumente werden damit gefunden. Allerdings gibt es einige Fälle, in denen durch linguistische Mehrdeutigkeiten oder unzureichende Berücksichtigung linguistischer Besonderheiten die Precision leidet. Im Folgenden werden daher entsprechende Anpassungen des oben allgemein beschriebenen Lösungsansatzes erläutert:
4.1.1.
Mehrdeutige Lemmatisierungen ^
Einige Wortformen erlauben mehrere Lemmatisierungen wie z.B. Betrug oder Garten. Die Suche mit Betrug meint meistens das Nomen und nicht das Verb betragen oder gar die französische Übersetzung faire. Ähnliches gilt für die Suche mit Garten, welche meistens nicht das Verb garen und erst recht nicht dessen Imperativ gar meint, wobei gar wiederum viele andere Bedeutungen hat. Wird umgekehrt mit dem französischen Begriff jardin gesucht, sollte die Übersetzung Garten gefunden werden, nicht jedoch die anderen Formen des Verbes garen.
4.1.2.
Mehrdeutige Akzentsetzungen ^
4.1.3.
«Falsche Freunde» in den unterschiedlichen Sprachen ^
Viele Wörter, die z.B. dem Lateinischen entlehnt sind, existieren gleichlautend in den verschiedenen Sprachen und haben identische oder sehr ähnliche Bedeutungen. Allerdings gibt es auch einige gleichlautende Wörter, die unterschiedliche Bedeutungen haben. So würde das französische Wort für Gerichtsstand for praktisch alle englischen Dokumente finden. Ebenso hat der deutsche Donner nichts mit dem französischen Verb donner zu tun.
4.1.4.
Verschiedene Bedeutungen eines Lemmas ^
Manche Wörter sind bereits in ihrer Grundform in einer Sprache mehrdeutig. So kann Bank das Geldinstitut oder die Parkbank meinen. Während gerade bei der Übersetzung eine Zuordnung zu einer Bedeutung die Precision erhöhen würde, so wäre die Zuordnung zu einer Bedeutung in den Dokumenten nur nach aufwendiger und fehleranfälliger semantischer Analyse z.B. mit statistischen Verfahren und bei der Suche nur über noch unsicherere statische Annahmen über die Nutzer möglich. Daher wird bei Swisslex auf eine entsprechende Differenzierung verzichtet.
4.2.
Mehrwortbegriffe ^
Die juristische Suche wird besonders effizient, wenn mit juristischen Fachbegriffen gesucht wird. Diese Fachbegriffe bestehen häufig aus mehreren Wörtern wie z.B. ungerechtfertigte Bereicherung oder grobe Fahrlässigkeit. Hier wäre eine Übersetzung der einzelnen Wörter sehr ungenau. Der TDS III bietet eine grosse Anzahl von Übersetzungen von Mehrwortbegriffen und Phrasen, die Swisslex für die Suche verwenden kann.
Wird ein solcher Mehrwortbegriff wie z.B. ungerechtfertigte Bereicherung erkannt, wäre eine Verknüpfung mit AND wenig präzise. Schliesslich sind damit eher nicht Dokumente gemeint, die beide Begriffe an weit entfernten Stellen in unterschiedlichen Zusammenhängen enthalten wie z.B. ungerechtfertigte Kritik an einer und persönlichen Bereicherung an anderer Stelle. Gleichzeitig wäre eine Suche als wortwörtliche Phrase zu eng. Flexionen wie einer ungerechtfertigten Bereicherung oder der ungerechtfertigten Bereicherungen sollen ebenfalls gefunden werden.
Daher werden Mehrwortbegriffe erkannt und auch ohne eingegebenen Operator automatisch zusammenhängend gesucht sowie übersetzt. Werden Mehrwortbegriffe mit einem Proximity-Operator wie z.B. SAME verwendet, so wird der Proximity-Operator in die Übersetzung übernommen. Daher findet ungerechtfertigte SAME Bereicherung nicht nur Die Bereicherung war ungerechtfertigt sondern auch l’enrichissement était illégitime.
4.3.
Weibliche und männliche Berufsbezeichnungen ^
4.4.
Transparenz und Anpassbarkeit ^
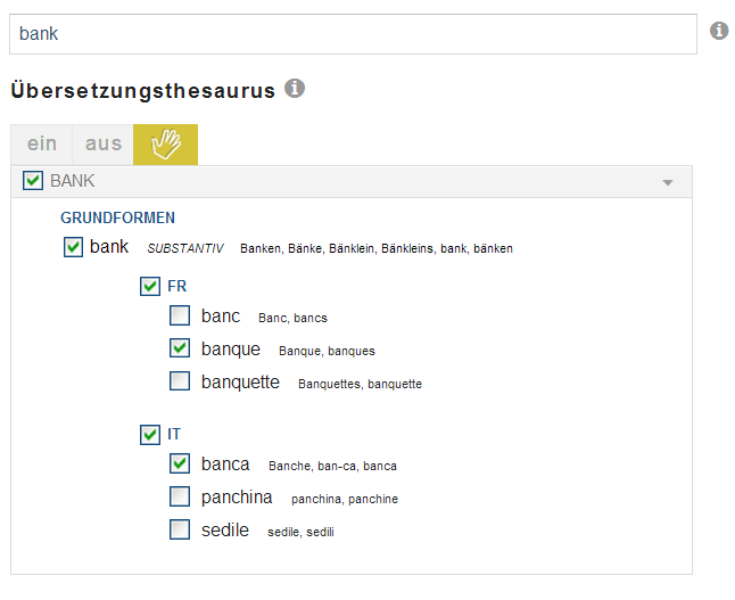
Abbildung 2: Auswahl der passenden Übersetzungen zum Begriff Bank
5.
Evaluation ^
6.
Conclusio ^
7.
Literatur ^
Korenius, Tuomo/Laurikkala, Jorma/Järvelin, Kalervo/Juhola, Martti, Stemming and lemmatization in the clustering of finnish text documents. In Proceedings of the thirteenth ACM international conference on Information and knowledge management (pp. 625–633). ACM 2004
Nasharuddin, Nurul Amelina/Abdullah, Muhamad Taufik/Kadir, Rabiah Abdul/Azman, Azreen, A Review on the Cross-lingual Information Retrieval, Information Retrieval & Knowledge Management,(CAMP), 2010 International Conference on. IEEE 2010
Cappellano/Bühler, TDS und Jurivoc: die beiden Schweizer juristischen Thesauri https://www.bj.admin.ch/dam/data/bj/staat/rechtsinformatik/magglingen/2010/03_cappellano_buehler-d.pdf
8.
Anhang ^
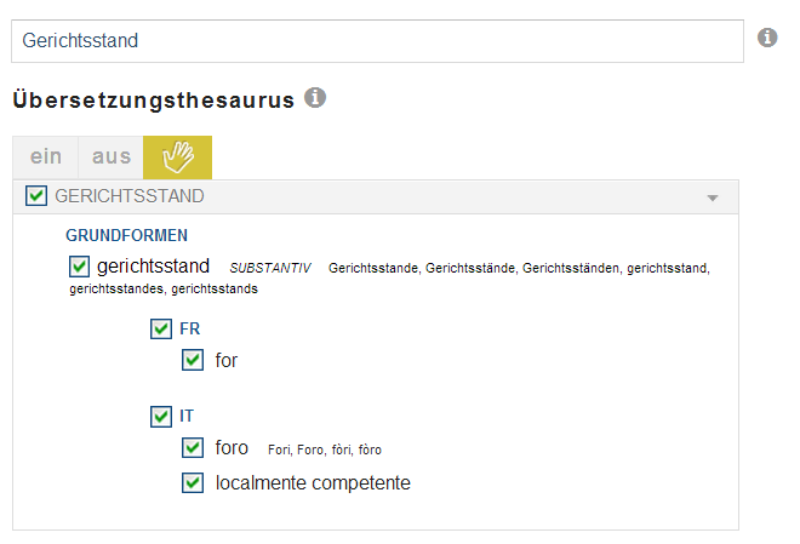
Abbildung 3: Übersetzungen der Suche mit Gerichtsstand
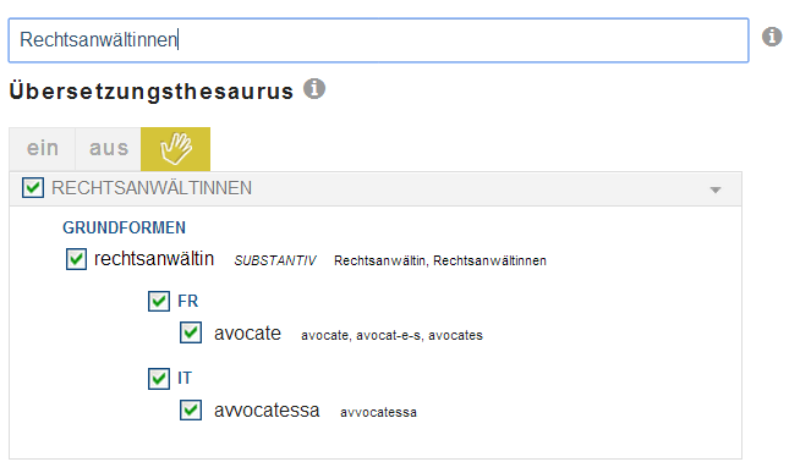
Abbildung 4: Suche mit Rechtsanwältinnen findet nur die weiblichen Formen
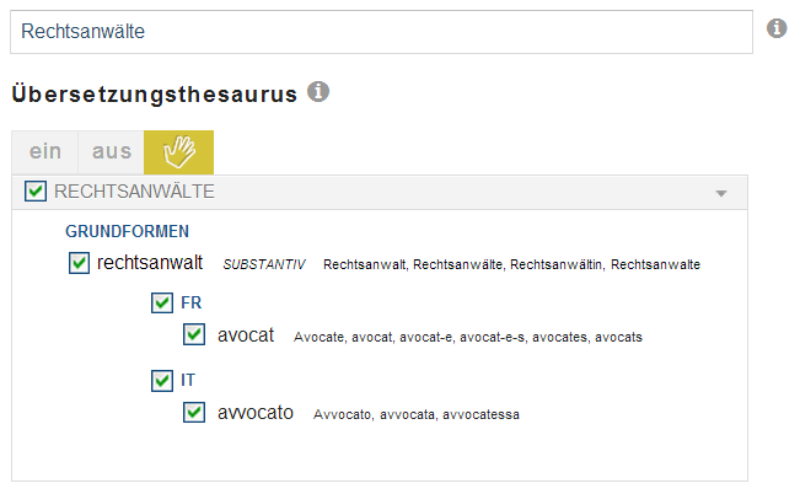
Abbildung 5: Suche mit Rechtsanwalt findet auch die weiblichen Formen
Jörn Erbguth, CTO, Swisslex – Schweizerische Juristische Datenbank AG, Rue du Mont Blanc 21, 1201 Genf, jerbguth@swisslex.ch; www.swisslex.ch
- 1 http://lucene.apache.org/solr.
- 2 Zur Suche bei Google: «Alles über die Suche». http://www.google.ch/intl/de/insidesearch/howsearchworks/algorithms.html.
- 3 http://lucene.apache.org.
- 4 http://www.canoo.com – eine Version der deutschen Language Tools können unter http://canoo.net getestet werden.
- 5 Cappellano/Bühler, TDS und Jurivoc: die beiden Schweizer juristischen Thesauri https://www.bj.admin.ch/dam/data/bj/staat/rechtsinformatik/magglingen/2010/03_cappellano_buehler-d.pdf.
- 6 http://www.ejustice.ch.
- 7 Koernius/Laurikkala/Kalervo/Martti, Stemming and Lemmatization in the Clustering of Finnish Text Documents, S. 632.
- 8 Nasharuddin/Abdullah/Kadir/Azman, A Review on the Cross-lingual Information Retrieval, S. 353.
- 9 Eine umfangreiche Liste von falschen Freunden findet sich bei Wikipedia http://de.wikipedia.org/wiki/Liste_falscher_Freunde.
- 10 Eine solche Funktion hatte es in einer früheren Version von Swisslex schon einmal gegeben. Die aktuelle Funktion geht jedoch einiges darüber hinaus.





