1.
Einleitung ^
In Hinblick auf die Untersuchung parlamentarischer Reden und politischer Diskurse gibt es eine ganze Reihe von linguistischen Arbeiten, die sich mit verschiedenen Bereichen parlamentarisch-politischer Kommunikation auseinandersetzen, von der Sprache des Rechtsextremismus, über Zwischenrufe im Parlament bis hin zur Geschlechterkonstruktion, vgl. etwa [Dörner & Vogt 1995; Schuppener 2008]. Häufig stehen thematische Fragen z.B. zum Thema Einwanderung im Vordergrund, anhand derer Sprachgebrauch, Sprachwandel und Diskurswandel betrachtet werden, wobei insbesondere die Arbeiten von Schulte [2002] und Shrouf [2006] durch ihre quantitative Grundlage mit aus deutschen Bundestagsreden erstellten Diskurskorpora auffallen. Bei den letztgenannten Arbeiten stehen jedoch die angewandten Methoden korpuslinguistischer Datengewinnung nicht im Vordergrund und werden daher auch nicht hinreichend hinterfragt. Dies gilt insbesondere für die Arbeit von Shrouf [2006], in der ausschließlich auf Grundlage absoluter und relativer Worthäufigkeiten argumentiert wird. Wir streben daher an, ein möglichst breites Spektrum korpuslinguistischer Methoden einzusetzen, um eine bessere und vielfältigere Datengrundlage insbesondere für kontrastive Untersuchungen politisch-parlamentarischer Reden zu ermöglichen, da unserer Ansicht nach der Einsatz verschiedener Analyseverfahren neue Perspektiven auf die Daten eröffnet, die beim Gebrauch eines einzigen Methodenansatzes verborgen blieben.
2.
Methodische Grundlagen der korpusbasierten Diskursanalyse ^
2.1.
«Quantitativ informierte qualitative Diskursanalyse» ^
2.2.
Suche nach politischen Schlagwörtern ^
3.
Korpusaufbau ^
3.1.
Charakterisierung der Datengrundlage ^

In Abbildung 1 lässt sich außerdem erkennen, dass die protokollierten Reden zusätzliche Inhalte enthalten, beispielsweise Zwischenrufe und Beifallsbekundungen sowie darüber hinaus auch von den Rednern eingebrachte Anträge im Volltext. Zwischenrufe und Beifallsbekundungen wurden gelöscht.

3.2.
Datenaufbereitung ^

4.
Ergebnisse der korpuslinguistischen Analyse ^
4.1.
Korpusvergleich mit dem Log-Likelihood-Verfahren ^
4.1.1.
Ergebnisse für Einzelwörter / Substantive ^
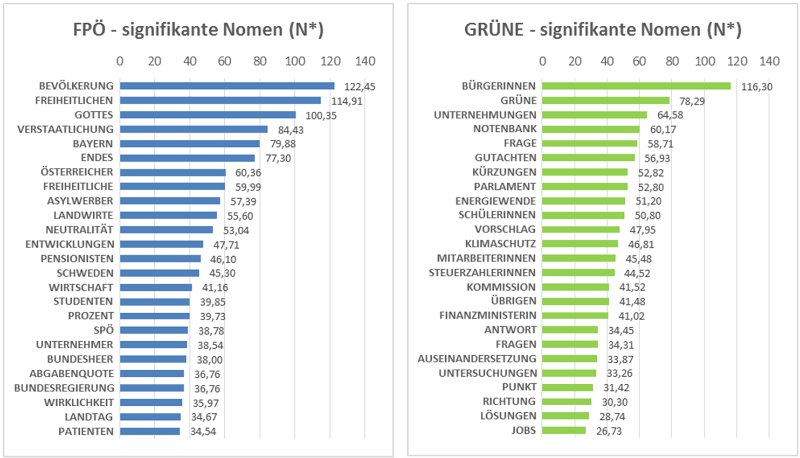
Abbildung 3a und Abbildung 3b zeigen die signifikanten Nomen, die mit dem Log-Likelihood-Test ermittelt werden konnten. Darunter sind u.a. politische Schlagwörter, die von der jeweiligen Partei häufig gebraucht werden und darüber hinaus im Zusammenhang mit der unmittelbaren politischen Ausrichtung oder mit aktuellen Ereignissen stehen. Die Wörter, die die politische Ausrichtung betreffen, könnten im Falle der FPÖ «Neutralität», «Bevölkerung», «Bundesheer» oder «Asylwerber» sein. Im Falle der GRÜNEN stechen die Schlagwörter «Energiewende» und «Klimaschutz» heraus, die ebenfalls für die politische Ausrichtung der GRÜNEN stehen, sowie ein konsequenter Gebrauch weiblicher Berufs- und Aufgabenbezeichnungen. Im Sinne Kleins Einteilung des politischen Wortschatzes lassen sich diese Schlagwörter dem Ideologievokabular zuordnen (Klein [1989], s.o. Kapitel 2.2.).

4.1.2.
Ergebnisse für Bigramme ^
Ideologische Ausrichtung der untersuchten Parteien und aktuelle Ereignisse schlagen sich auch in den signifikanten Wort-Bigrammen nieder, die anhand des von Rayson & Garside [2000] vorgeschlagenen Verfahrens berechnet worden sind (Abbildung 4a und Abbildung 4b). Im Vergleich zu den Nomen haben die Ergebnisse zugenommen, die mit dem Zusammenbruch der Hypo Alpe-Adria-Bank zusammenhängen dürften, beispielsweise «Verstaatlichung Not», «Kärntner Landtag» und «Jörg Haider» bei der FPÖ und «Hypo Alpe-Adria», «Steuerzahlerinnen Steuerzahler» oder «Bad Bank» bei den GRÜNEN. Hinzu kommt eine weitere Kategorie an Ergebnissen: Hierbei handelt es sich um wiederkehrende sprachliche Muster der eingebrachten Entschließungsanträge, z.B. bei der FPÖ «aufgefordert Regierungsvorlage», «Mitglieder Bundesregierung», «Regierungsvorlage zuzuleiten».
Da ein Vollformenkorpus ohne Lemmatisierung untersucht wurde, lassen sich auch idiomatische Wendungen oder Phraseologismen erkennen. Bei der FPÖ handelt es sich dabei z.B. um die Bigramme «leider Gottes», «letzten Endes», «ländlichen Raum», bei den GRÜNEN z.B. «humanitäre Hilfe». Überdies tauchen Teile von verbreiteten Redensarten in den Daten auf, wie «[zur] Kasse gebeten [werden]» und «Geld [aus der] Tasche [ziehen]».
4.2.
Anwendung statistischer Assoziationsmaße ^
4.2.1.
Trigramme / Poisson-Stirling ^
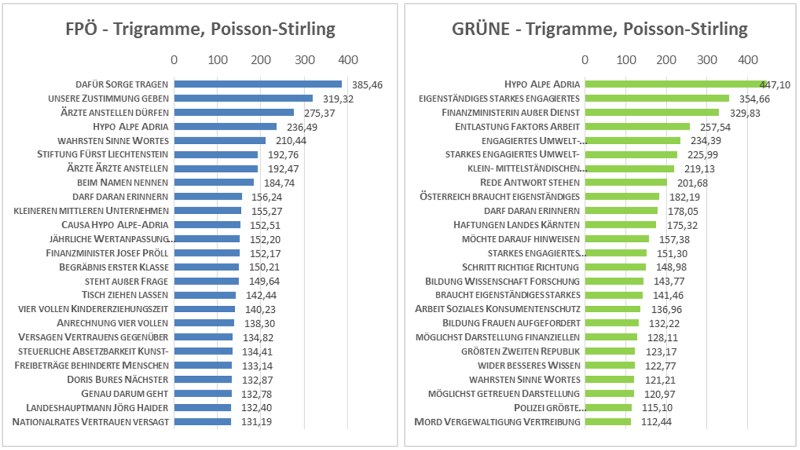
Das Poisson-Stirling-Assoziationsmaß ist eine von Quasthoff & Wolff [2002] vorgeschlagene, mit der Poisson-Verteilung verbundene Form der Berechnung von signifikanten Kollokationen eines Korpus, die mit dem von Bubenhofer [2009] verwendeten Log-Likelihood-Test vergleichbare Ergebnisse verspricht [Quasthoff & Wolff 2002]. Das entscheidende Kriterium bei der Berechnung ist das statistisch signifikante gemeinsame Auftreten von zwei Wörtern A und B in einem bestimmten Kontext (z.B. Analysefenster oder Satzebene). Die folgenden Ergebnisse (Abbildung 5a und Abbildung 5b)3 wurden unter Ausschluss der ermittelten Stoppwörter4 berechnet.
Während beim Korpusvergleich (s.o. Kapitel 4.1) verfahrensbedingt keine Gemeinsamkeiten in den Daten erscheinen, treten nun bei beiden Korpora Übereinstimmungen zu Tage, wie beispielsweise «Hypo Alpe Adria», «darf daran erinnern» oder «[im] wahrsten Sinne [des] Wortes». Weiterhin finden sich Beispiele für idiomatische Ausdrücke, wie «Rede [und] Antwort stehen» oder «wider besseres Wissen» bei den GRÜNEN und «[über den] Tisch ziehen lassen» oder «[die Dinge] beim Namen nennen».
4.2.2.
Trigramme Chi-Quadrat-Test ^

5.
Fazit und Ausblick ^
Die gewonnenen Datensätze eignen sich darüber hinaus gut für Visualisierungen, die sich (nicht nur) in den Digital Humanities zunehmender Beliebtheit erfreuen (dazu weitergehend Sippl [2015, Kapitel 8]). Da wir ein breites Methodenspektrum abdecken, bietet sich der gewonnene Datensatz im besonderen Maße dazu an, eine interaktive Plattform zu entwickeln, bei der der Nutzer über die Art der Informationsdarstellung und über den zu Grunde liegenden Datensatz und den untersuchten Zeitraum frei entscheiden kann. Ein Prototyp dieser Plattform mit unterschiedlichen Visualisierungs- und Interaktionsmöglichkeiten findet sich unter der URL http://homepages.uni-regensburg.de/~sic07430. Dort sind auch Korpusvergleiche nach weiteren Wortkategorien oder Eigennamen möglich.
6.
Literaturverzeichnis ^
Bird, Steven/Klein, Ewan/Loper, Edward, Natural Language Processing with Python, O’Reilly, Beijing 2009.
Bubenhofer, Noah, Sprachgebrauchsmuster, De Gruyter, Berlin, New York 2009.
Bubenhofer, Noah/Scharloth, Joachim, Korpuslinguistische Diskursanalyse. In: Meinhof, Ulrike Hanna (Hrsg.), Diskurslinguistik im Spannungsfeld von Deskription und Kritik, Akademie Verlag, Berlin 2013, S. 147–167.
Creswell, John W., Research Design. http://isites.harvard.edu/fs/docs/icb.topic1334586.files/2003_Creswell_A%20Framework%20for%20Design.pdf, 2003.
Dörner, Andreas/Vogt, Ludgera (Hrsg.), Sprache des Parlaments und Semiotik der Demokratie, De Gruyter, Berlin 1995.
Evert, Stefan, Association Measures. http://www.collocations.de/AM/contents.html, 2004.
Heyer, Gerhard et al., Wissensextraktion durch linguistisches Postprocessing bei der Corpusanalyse. In: Lobin, Henning (Hrsg.), Sprach- und Texttechnologie in digitalen Medien. Proceedings der GDLV-Frühjahrstagung, Gießen 2001, Norderstedt: Books on Demand 2001, S. 71–83.
Jung, Matthias, Linguistische Diskursgeschichte. In: Böle, Karin, Jung, Matthias, Wengeler, Martin (Hrsg.), Öffentlicher Sprachgebrauch, Westdeutscher Verlag, Opladen 1996, S. 453–472.
Kantardzic, Mehmed, Data Mining, IEEE Press, New Jersey 2011.
Klein, Josef, Politische Semantik, Westdeutscher Verlag, Opladen 1989.
Manning, Christopher et al., Stanford Tokenizer. http://nlp.stanford.edu/software/tokenizer.shtml, 2015.
Manning, Christopher/Schütze, Hinrich, Collocations. http://nlp.stanford.edu/fsnlp/promo/colloc.pdf, 1999.
Mehler, Alexander/Wolff, Christian, Einleitung: Perspektiven und Positionen des Text Mining [Einführung in das Themenheft Text Mining des LDV-Forum]. http://www.ldv-forum.org/2005_Heft1/1-18_MehlerWolff.pdf, 2005.
Quasthoff, Uwe/Wolff, Christian, The Poisson Collocation Measure and its Applications. In: Proc. Second International Workshop on Computational Approaches to Collocations, Wien, 2002, http://epub.uni-regensburg.de/6824/1/PoissonCollocationMeasureQuasthoffWolff_final.pdf, 2002.
Rayson, Paul/Garside, Roger, Comparing Corpora using Frequency Profiling. http://ucrel.lancs.ac.uk/people/paul/publications/rg_acl2000.pdf, 2000.
Schulte, Sandra Veronika, Sprachreflexivität im parlamentarischen Diskurs, Shaker Verlag, Aachen 2002.
Schuppener, Georg (Hrsg.), Sprache des Rechtsextremismus, Edition Hamouda, Příbram 2008.
Shrouf, A. Naser, Sprachwandel als Ausdruck des politischen Wandels, Peter Lang, Frankfurt am Main 2006.
Sippl, Colin, Eine kontrastive Diskursanalyse der Parlamentsreden von FPÖ und Grünen anhand textlinguistischer Datenverarbeitung, Universität Regensburg, Institut für Information und Medien, Sprache und Kultur, Bachelorarbeit im Fach Medieninformatik, Oktober 2015.
Toutanova, Kristina et al., Stanford Log-linear Part-Of-Speech Tagger. http://nlp.stanford.edu/software/tagger.shtml, 2015.
Wolff, Christian, Aspekte des Vergleichs von Fach- und Normcorpora am Beispiel eines Fachcorpus aus der Automobiltechnik, Arbeitsmaterialie, Universität Leipzig, Abteilung für automatische Sprachverarbeitung, Leipzig, https://www.researchgate.net/publication/43606643_Aspekte_des_Vergleichs_von_Fach-_und_Normcorpora_am_Beispiel_eines_Fachcorpus_aus_der_Automobiltechnik, 2002.
- 1 http://www.parlament.gv.at/PAKT/STPROT/; alle in diesem Beitrag angegebenen URLs wurden zuletzt am 8. Januar 2016 auf Erreichbarkeit geprüft.
- 2 Aus dem Zwischenformat lassen sich Korpora für alle Parteien des Nationalrats nach beliebigen Kriterien generieren.
- 3 Z.T. platzbedingt verkürzte Wiedergabe der Trigramme; vollständige Darstellung unter http://homepages.uni-regensburg.de/~sic07430.
- 4 Darunter fallen insbesondere Funktionswörter und ausgewählte Nomen wie «Damen», «Herren» oder «Abgeordnete» (vgl. http://www.ranks.nl/stopwords/german).





