1.
Introduction ^
2.
Research Method and Objectives ^
3.1.
Lexical Knowledge Databases ^
Lexical knowledge represents well-known information about words and relations between them (O’Hara, 2005). In the artificial intelligence approach, this is called «ontology» and pretends to construct a model that explains the relations of the entities (Pustejovsky & Bergler, 1992). As stated by Onyshkevich and Nirenburg (1995), an ontology is a model of the world, a body of knowledge of the world organized as a taxonomy. There exist many lexical relations between words; however, this research focuses only on a set of them (See Table 3.1).
| Relation | Description |
| Synonym | X and Y are interchangeable in some context without changing the truth value of the preposition in which they are embedded.E.g. a pistol is synonym of a handgun. |
| Hyponym | X is a hyponym of Y if X is a (kind of) Y. E.g. a pistol is a hyponym of weapon. |
| Hypernym | Y is a hypernym of X if X is a (kind of) Y. E.g. a weapon is a hypernym of pistol. |
| Meronym | Member of a constituent part of something. X is a meronym of Y if X is a part of Y. E.g. a trigger is a meronym of weapon. |
| Holonym | The name of the whole of which the meronym names a part. Y is a holonym of X if X is a part of Y. E.g. weapon is a holonym of trigger |
| Troponym | X is a troponym of Y if X is to Y in some manner, i.e. X is a particular way of Y.E.g. a loaded rifle is a weapon |
| Coordinate terms (siblings) | Nouns or verbs that have the same hypernym. E.g. a pistol is a coordinate term of rifle (both have the hypernym weapon) |
| Derivationally related forms | Terms in different syntactic categories that have the same root form and are semantically related. E.g. gunman is a derivationally related form of gun. |
3.2.
Ontologies as Search Support in Legal Databases ^
4.1.
Expert Interviews for Search in Legal Databases ^
The needs assessment involved six people, all experienced in the law domain and all use a computer to perform their job in more than 50% of their time (self-declared). During the interviews, they also mentioned that they review legal literature very often. All participants agreed that legal information databases will become more important in the future and that formulating the query in the search system is one of the most important procedures while searching. Answers were not so uniform when participants were asked whether they think that recommendations (offered by a system) of query reformulation could support the efficiency and effectiveness of their search: While three agreed completely, the other three were doubtful about the type of recommendations.
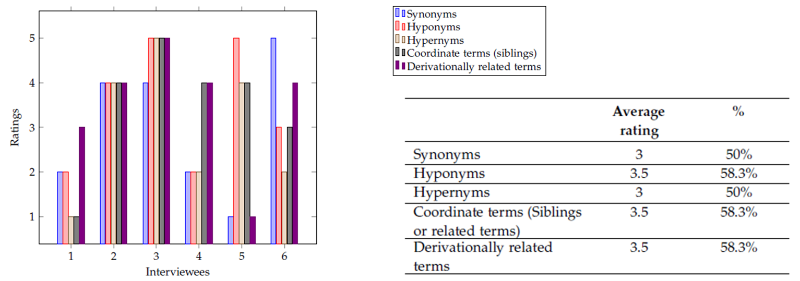

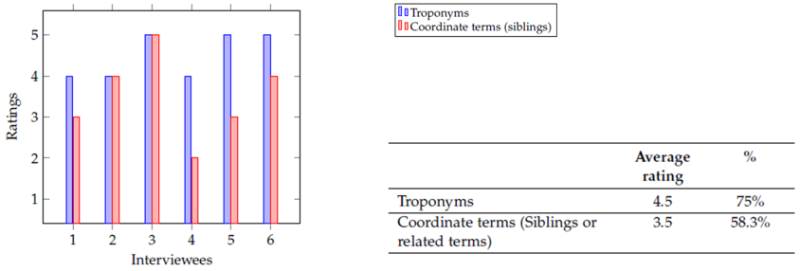
4.2.
Extending Search, Navigation and Exploration Mechanisms with GermaNet ^

5.1.
System Architecture ^
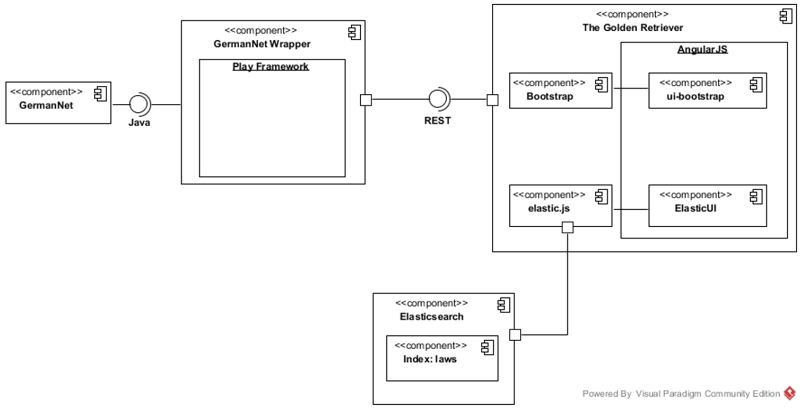
5.2.
Prototypical User Interface ^
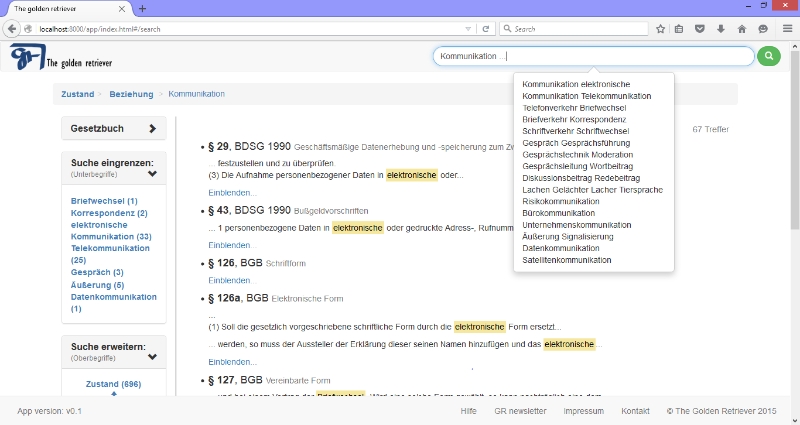
6.
Critical Reflection and Drawbacks ^
7.
Conclusion and Outlook ^
8.
References ^
Airio, E./Järvelin, K./Saatsi, P./Kekäläinen, J./Suomela, S., Ciri, An ontology-based query interface for text retrieval. In Web Intelligence: Proceedings of the 11th Finnish Artificial Intelligence Conference, 2004.
Altamirano Sainz, L., Applying lexical knowledge to improve search quality for a German legal information database. Master’s thesis at Technische Universität München, 2015.
Bast, H./Chitea, A./Suchanek, F./Weber, I., ESTER: Efficient Search in Text, Entities, and Relations. In C. Clarke, N. Fuhr, & N. Kando (Eds.), International Conference on Research and Development in Information Retrieval. ACM, 2007.
Dini, L./Peters, W./Liebwald, D./Schweighofer, E./Mommers, L./Voermans, W., Cross-lingual legal information retrieval using a WordNet architecture. In G. Sartor (Ed.), The 10th international conference on Artificial intelligence and law (p. 163), 2005.
Divoli, A./Hearst, M. A./Wooldridge, M. A., Evidence for showing gene/protein name suggestions in bioscience literature search interfaces. In Pacific Symposium on Biocomputing (Vol. 13, pp. 568–579), 2008.
Erbguth, J./Bloch, M. S., Neue Suche bei Swisslex. In: Erich Schweighofer, Franz Kummer und Walter Hötzendorf (Hg.): Tagungsband des 18. Internationalen Rechtsinformatik Symposions IRIS 2015, Bd. 2015: OCG – Österreichische Computer Gesellschaft, 2015.
Fellbaum, C., WordNet: An electronic lexical database. Cambridge, MIT Press, 1998.
Hamp, B./Feldweg, H., GermaNet – a Lexical-Semantic Net for German. In Proceedings of ACL workshop Automatic Information Extraction and Building of Lexical Semantic Resources for NLP Applications (pp. 9–15), 1997.
Henrich, V./Hinrichs, E., GernEdiT – The GermaNet Editing Tool. In N. Calzolari, K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, D. Tapias (Eds.), Proceedings of the Seventh International Conference on Language Resources and Evaluation, 2010.
Holtzblatt, K./Beyer, H., Contextual design. In A. Edwards & S. Pemberton (Eds.), Human-Computer Interaction extended abstracts (p. 184), 1997.
Joyent, Incorporation., Node.js. Retrieved from https://nodejs.org/ (accessed 2 January 2016), 2015.
Miller, G. A., WordNet: a lexical database for English. Communications of the ACM, 38(11), 1995.
O’Hara, T. P., Empirical Acquisition of Conceptual Distinctions via Dictionary Definitions (Ph. D. Thesis). New Mexico State University, New Mexico, 2005.
Onyshkevich, B./ Nirenburg, S., A lexicon for knowledge-based MT. Machine Translation, 10(1-2), 5–57, 1995.
Princeton University, WordNet 3.0 Reference Manual – Glossary of WordNet terms. Retrieved from https://wordnet.princeton.edu/ (accessed 2 January 2016), 2010.
Pustejovsky, J./Bergler, S., Lexical semantics and knowledge representation: Proceedings of the first SIGLEX Workshop, Berkeley, CA, USA, 1992.
Saravanan, M./Ravindran, B./Raman, S., Improving legal information retrieval using an ontological framework. Artificial Intelligence and Law, 17(2), 101–124, 2009.
Schweighofer, E./Geist, A., Legal Query Expansion using Ontologies and Relevance Feedback. In LOAIT (pp. 149–160), 2007.
Typesafe Incorporation, Typesafe: Activator. Retrieved from http://typesafe.com/activator (accessed 2 January 2016), 2015.
University of Tübingen, GermaNet – A German Wordnet: GermaNet – An Introduction. Retrieved from http://www.sfs.uni-tuebingen.de/GermaNet/ (accessed 2 January 2016), 2014.





