1.
Introduction ^
2.
Related work ^
3.1.
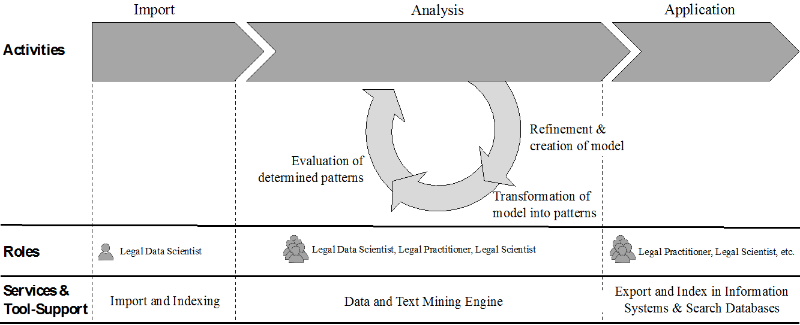
Data Science Environment ^

3.2.
Legal Document Corpus ^
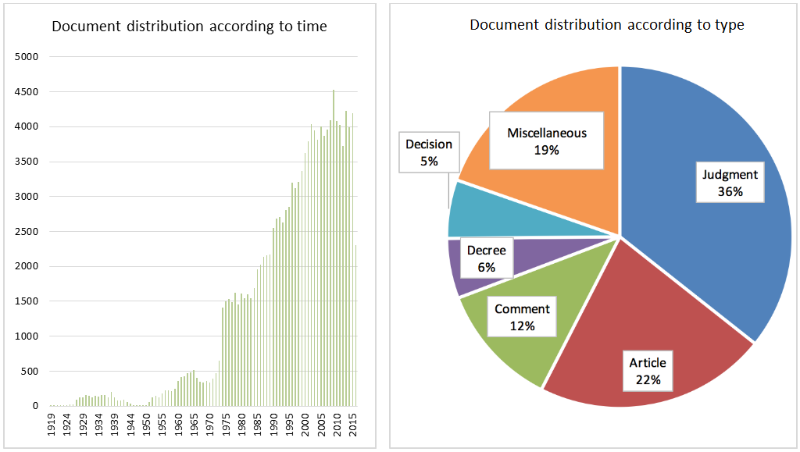
The document corpus provided by the DATEV eG1 consists of more than 130.000 different documents related to German tax law. The documents cover a time span of almost 100 years. The oldest documents indexed are from 1919, whereas the latest document in the corpus was published in July 2016. The corpus is fully digitized and available in XML but also in JSON format, in which each document is represented by a single file. Furthermore, the corpus consists of more than 40 different types, such as judgments (dt. Urteile), articles (dt. Aufsätze), laws (dt. Gesetze), etc. The corpus is a selection of the documents stored in the DATEV legal information database LEXinform.
4.1.
Rule-based text annotation as an interdisciplinary task ^
4.2.
Extracting (meta-)data from legal documents ^
4.2.1.
Approach ^
After the integration of zoning information, the following steps are performed to detect the year of dispute:
- Constrain search space to section «Tatbestand»
- Determine dates within the text
- Differentiate between specific dates, e.g., «21.10.2010» or «21. September 2010», dates referring to a whole year, e.g., «2010», and timespans «2000 bis 2009».
- Determine indicating sentences, such as [Antragssätze] (Der Kläger beantragt…)
- If those sentences contain whole years or timespans, mark those as year of disputes.
- Determine, based on particular linguistic patterns expressed in Apache Ruta, contexts that allow conclusions about the year of dispute.
- Pre-Indicators: Linguistic features, i.e. tokens, words, patterns, indicating that the following date is likely to be the year of dispute.
Examples: «auf die im Streitjahr 2006 zugeflossenen Erstattungszinsen», «den Einkommensteuerbescheid 2006 vom 11.12.2007», «die Kindergeldfestsetzung für den Zeitraum von Oktober 2003 bis Dezember 2004 und von Januar 2006 bis Juni 2006», etc.
- Post-Indicators: Linguistic features, i.e. tokens, words, patterns, indicating that the date mentioned before is likely to be the year of dispute.
Examples: «Erwerbsunfähigkeitsrente im Jahre 2005 (Streitjahr)»
- Clamp-Indicators: Linguistic features, i.e. tokens, words, patterns, indicating that the date mentioned between two features is likely to be the year of dispute.
Examples: «ab Januar 2008 Kindergeld zu bewilligen», «Bescheidfür 1997 und 1998 über Einkommensteuer»
- Pre-Indicators: Linguistic features, i.e. tokens, words, patterns, indicating that the following date is likely to be the year of dispute.
4.2.2.
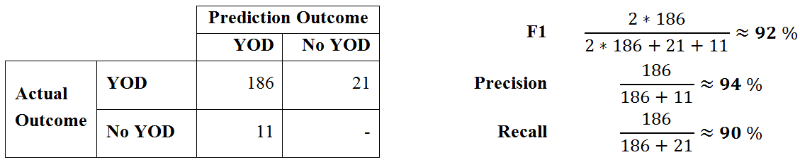
Evaluation ^
4.2.3.
Critical reflection ^
4.3.
Determining legal definitions and defining contexts ^
4.3.1.
Approach ^
Based on this two-dimensional differentiation, several examples, i.e. sentences, from laws and judgments can illustrate the overall approach:
- Law: legal definitions (narrow sense)
Examples: «Sachen im Sinne des Gesetzes sind nur körperliche Gegenstände.» (§ 90 BGB), «Die Anfechtung muss in den Fällen der §§ 119, 120 ohne schuldhaftes Zögern (unverzüglich) erfolgen, [...].» (§ 121 BGB), «Zum Inland im Sinne dieses Gesetzes gehört auch der der Bundesrepublik Deutschland zustehende Anteil am Festlandsockel, soweit [...].» (§ 1 Abs. 1 Satz 2 EStG), «Der Gesamtbetrag der Einkünfte, [...], ist dasEinkommen.» (§ 2 Abs. 4 EStG)
- Judgment: term declaration and defining contexts (with different sub-levels)
Examples: «Nach § 8 Abs. 1 EStG sind alle Güter, die in Geld oder Geldeswert bestehen und [...], Einnahmen.», «Dagegen liegt dann kein Arbeitslohn vor, wenn [...], nicht [...] gewährt wird.», «Der Aggregatszustand der Gegenstände ist unbeachtlich, so dass auch der elektrische Strom als Ware i.S.d. Vorschrift gilt.», «Hersteller sei demnach jeder, in dessen Organisationsbereich das Produkt entstanden ist.»
4.3.2.
Critical reflection ^
5.
Conclusion and Outlook ^
6.
References ^
Matthias Grabmair/Kevin D. Ashley/Ran Chen/Preethi Sureshkumar/Chen Wang/Eric Nyberg/Vern R. Walker, Introducing LUIMA: An Experiment in Legal Conceptual Retrieval of Vaccine Injury Decisions Using a UIMA Type System and Tools, ICAIL Proceedings, 2015.
Herbert Lionel Adolphus Hart, The concept of law, Oxford University Press, 1961.
Emile de Maat/RadboudWinkels, Automated Classification of Norms in Sources of Law, Semantic processing of legal texts, 2010.
Emile de Maat/RadboudWinkels/Tom van Engers, Automated detection of reference structures in law, JURIX, 2006.
Stephan Walter, Definition extraction from court decisions using computational linguistic technology, Formal Linguistics and Law, vol. 212, 2009.
Bernhard Waltl, Computer-gestützte Analyse des Bedeutungswandels rechtlicher Begriffe, Wien: OCG, 2016.
Meng Wang/Bingbing Ni/Xian-Sheng Hua/Tat-Seng Chua, Assistive Tagging: A Survey of Multimedia Tagging with Human-Computer Joint Exploration, ACM Comput. Surv., vol. 44, no. 4, 2012.
Bernhard Waltl/Florian Matthes/Tobias Waltl/Thomas Grass, LEXIA: A data science environment for Semantic analysis of german legal texts, in: Erich Schweighofer/Franz Kummer/Walter Hötzendorfer/Georg Borges (Hrsg.), Netzwerke / Networks –Tagungsband des 19. Internationalen Rechtsinformatik Symposions IRIS 2016, OCG, Wien/Bern 2016.
Adam Wyner/Raquel Mochales-Palau/Marie-Francine Moens/David Milward, Approaches to text mining arguments from legal cases, Semantic processing of legal texts, 2010.
- 1 https://www.datev.de/, accessed 29 December 2016.





