1.
Einleitung ^
Um die Kontextualisierung und Accessibility der existierenden Informationsressourcen zu verbessern und um in Folge redaktionelle Workflows zu optimieren und neue Verwertungskanäle zu erschließen, konzentriert sich der ÖGB-Verlag verstärkt auf die automatisierte Verarbeitung von Content (Content Curation) als auch die Adaption neuer Standards für die automatische Syndizierung und Integration von strukturierten Daten (Dynamic Semantic Publishing) für die interne und externe Informationslogistik. Dieses als Linked Data3 bekannte Prinzip hält sukzessiven Einzug in die Redaktionssysteme und Verwertungsstrategien content-verarbeitender Unternehmen wie aktuelle Untersuchungen (Graube et al. 2011; Pellegrini 2012) und Fallstudien von international agierenden Fachverlagen wie Reed Elsevier, Wolters Kluwer, Pearson Publishing, Springer Verlag u.a.m belegen.
2.
Die Linked Data Architektur des ÖGB-Verlages ^
2.1.
Information Preprocessing mit dem ONTEASY Framework ^
- Hierarchische Substantiv-/Instanz-/Teil-Von- Relationen (z.B. Institution => Unternehmen => Ges.m.b.H.)
- Synonym-Relationen zu den einzelnen Wortarten (z.B. Weihnachtsgeld – Weihnachtsremuneration)
- Antonym-Relationen zu den einzelnen Wortarten (z.B. Anstellung <=> Kündigung)
- Prädikats-Relationen (Subjekt, Prädikat, Objekt, Adverbialbestimmung, z.B. Belegschaft wählt Betriebsrat in geheimer Wahl.)
- Ereignis-Relationen (Handlungen, z.B. Arbeitgeber spricht Kündigung aus => Arbeitnehmer empfängt Kündigung => Kündigungsfrist beginnt zu laufen.)
- Zustands-Relationen (Ausgangs- und die Endsituation eines Ereignisses, z.B. Anstellung: arbeitsuchend => beschäftigt)

Abbildung 1: Schematische Darstellung des ONTEASY Frameworks
2.2.
Wissensorganisation & Linked Data Services mit dem Poolparty Framework ^
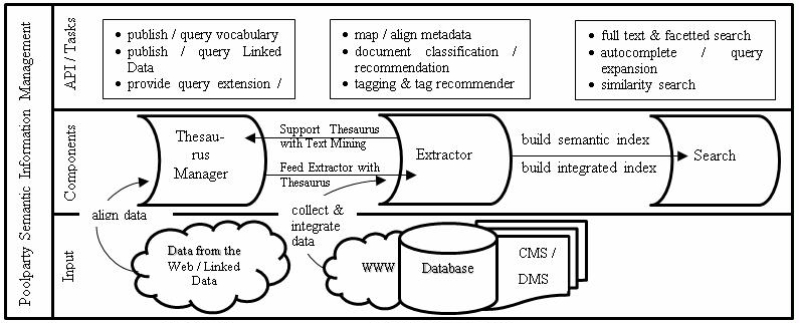
Abbildung 2: Schematische Darstellung des PoolParty Frameworks
3.
Anwendungsfelder von Linked Data im ÖGB-Verlag ^
3.1.
Content Augmentation ^
3.2.
Agile Datenintegration und integrierte Sichten auf Geschäftsobjekte ^
3.3.
Mitarbeiterportal ^
4.
Conclusio und Ausblick ^
5.
Literatur ^
Cranford, Steve (2009). Spinning a Data Web. In: Price Waterhouse Coopers (Ed.). Technology Forecast, Spring 2009. http://www.pwc.com/us/en/technology-forecast/spring2009/index.jhtml, accessed September 20, 2013.
Graube, Markus; Pfeffer, Johannes; Ziegler, Jens; Urbas, Leon (2011). Linked Data as integrating technology for industrial data. In: 2011 Int. Conference on Network-Based Information Systems, 7–9 September 2011, p. 162–167.
Mitchell, Ian; Wilson, Mark (2012). Linked Data. Connecting and exploiting big data. Fujitsu White Paper, March 2012. http://www.fujitsu.com/uk/Images/Linked-data-connecting-and-exploiting-big-data-%28v1.0%29.pdf, accessed September 12, 2013.
Pellegrini, Tassilo (2012). Semantic Metadata in the News Production Process. Achievements and Challenges. In: Lugmayr, Artur et al. (Eds). Proceeding of the 16th International Academic MindTrek Conference 2012. ACM SIGMM, p. 125–133.
Rayfield, Jem (2012). Sports Refresh: Dynamic Semantic Publishing. In: BBC Internet Blog, http://www.bbc.co.uk/blogs/bbcinternet/2012/04/sports_dynamic_semantic.html, visited May 5, 2012.
W3C (2004). RDF – Resource Description Framework. In: http://www.w3.org/RDF/, accessed December 10, 2013.
W3C (2008). SPARQL Query Language for RDF. In: http://www.w3.org/TR/rdf-sparql-query/, accessed December 20, 2013.
Tassilo Pellegrini
FH-Professor, Fachhochschule St. Pölten, Department Medienwirtschaft
Matthias Corvinus Strasse 15, 3100 St. Pölten, AT
Tassilo.pellegrini@fhstp.ac.at; http://www.fhstp.ac.at
Christian Wachter
Verlag des Österreichischen Gewerkschaftsbundes
Johann-Böhm-Platz 1., A-1020 Wien, AT
Christian.Wachter@oegbverlag.at; http://www.oegbverlag.at
Andreas Blumauer
Geschäftsführer, Semantic Web Company
Neubaugasse 1, 1070 Wien, AT
A.Blumauer@semantic-web.at; http://www.semantic-web.at
Jürgen Paulus
Compass Verlag
Matznergasse 17, 1140 Wien, AT
Juergen.Paulus@compass.at; http://www.compass.at/
- 1 Die Entwicklung findet im Rahmen des Projektes «NoLDE – Network of Linked Data Excellence» statt. Das Projekt wird durch die FFG-Programmlinie «COIN Kooperation und Netzwerke» gefördert (Projektnummer: 3592880).
- 2 Siehe z.B. die Kurzübersicht zum Kollektivvertrag der Arbeiter der Metallindustriehttp://www.kollektivvertrag.at/kv/eisen-metallerzeugende-und-verarbeitende-industrie-arb, aufgerufen am 4. Januar 2014.
- 3 Für eine detaillierte Beschreibung der «Linked Data» Methode siehe http://www.w3.org/standards/semanticweb/data, aufgerufen am 28. Oktober 2013. Eine Überblicksdarstellung der technologischen Grundlagen findet sich auch im Beitrag von Pellegrini (2014) in diesem Tagungsband.
- 4 Siehe http://www.w3.org/2004/02/skos/ (aufgerufen 20. Dezember 2013).
- 5 Inhalte werden um Tags angereichert, die als vernetzte Ressource aus der Linked Data Cloud wiederum selbst über weiterführende Kontextinformation verfügen können.
- 6 Auskoppelung von Dossiers entlang unterschiedlicher Darstellungsweisen z.B. als Tabelle, als Zeitreihe, als Geo-Visualisierung etc.
- 7 Zahlreiche Medien, wie z.B. BBC oder der Spiegel Online, machen von diesem Prinzip bereits Gebrauch, und fassen News, Medien und Fakten zu Personen, Themen oder Orte zusammen, z.B. in Form so genannter «Topic Pages» für Tiere. Siehe z.B. http://www.bbc.co.uk/nature/life/Red_Squirrel (aufgerufen 20. Dezember 2013). Für die technische Umsetzung siehe Rayfield (2012).





