1.
Introduction ^
It thus becomes obvious that the design of modeling methods in order to use them in the form of according IT-based tools is a challenging undertaking. At the Research Group Knowledge Engineering at the University of Vienna we currently investigate the underlying theoretical and technical foundations of these activities under the term meta modeling. Meta modeling thereby stands for all activities related to the conceptualization of modeling methods which includes their creation, design, formalization, development, and deployment1. The ultimate goal of meta modeling in our understanding is to provide usable modeling methods in the form of executable software tools. These tools may comprise functionalities such as visual model editors, simulation engines, transformation and analysis tools, etc. that are specifically adapted for a particular modeling method.
2.
Foundations ^
3.
Abstraction and Transparency as Functions in Meta Modeling ^
In an attempt to arrive at a more formal notation we suggest to define an abstraction function for modeling methods \(f^{abst}_{MM}\) that maps a combination from the set of formalisms FO and originals O to the space of modeling methods where each modeling method j is characterized by a combination of a set of modeling languages MLj, a set of modeling procedures MPj and a set of mechanisms and algorithms MAj. On the model level we can define a function \(f^{abst}_M\) as a map from a combination of the components of a modeling method j and the set of originals to the union of the sets of models that belong to the modeling method j.
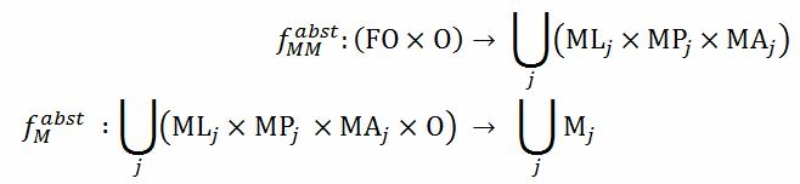
With these definitions there are several assumptions involved: first, it is assumed that the formalisms in FO provide all necessary constructs to define a valid map to modeling languages, procedures and mechanisms and algorithms. However, the formalisms that we have come across so far in meta modeling only target selected parts of modeling methods. Mostly, only the modeling language part is covered. Second, the combination of the components of modeling methods is not yet as well understood on a theoretical level as the shown relations may imply. Rather it is still being investigated in current research how for example formally described modeling procedures are combined with a modeling language and mechanisms and algorithms in a universally applicable fashion [Bork and Sinz (2014)]. Third, it needs to be pointed out that the application of the abstraction functions, in particular of \(f^{abst}_{MM}\), requires considerable human involvement and seems to be hardly automatable. Therefore, the contribution of these definitions is to establish a more concrete working hypothesis for characterizing abstraction in the context of meta modeling.
When focusing now on the role of transparency and the above mentioned characteristics of traceability, visibility, availability, and verifiability of information, we can also approach it from the viewpoint of meta modeling. Again, what draws our attention is the relation between models and originals and modeling methods and originals. However, in contrast to abstraction where we can clearly distinguish two levels and the focus seems to lie more on the meta modeling level by providing more freedom, transparency seems to be essentially dependent on a combination of both levels. For the properties of transparency it is important what kinds of inferences are possible from models to originals. These inferences are of course also determined by the modeling method that is used for the creation of the models. We can therefore propose a first idea of a transparency function \(f^{transp}\) that maps combinations of a modeling method and its models to originals O.

4.
Application Examples ^
Consider for example that the information contained in the Austrian RIS legal information system needs to be made accessible in a barrier-free manner, e.g. through special XML formats for processing by Braille devices [Bernier and Burger (2012)]. All texts in RIS are today stored in an XML format with a corresponding XML schema [Stöger and Weichsel (2008)]. The XML documents can thus be regarded as models whose modeling language is set by the XML schema. According to the abstraction function \(f^{abst}_{MM}\) we thus recognize that the used formalism is set to the XML definitions as specified by W3C and the regarded original that served as input for the abstraction are the legal texts that are to be stored in RIS. The modeling procedure that is used to populate the models is today based on forms for entering meta data and texts as well as algorithms that are able to extract the information from Word-Files [Weichsel (2013)]. Based on this definition of the modeling method, we can also analyze the abstraction function for models \(f^{abst}_{M}\). It is obvious that the resulting models, i.e. the XML documents in this case, depend on the characteristics of the XML schema, the modeling procedure and the used transformation algorithms. If we decided now to design an application that extracts legal information from the models, e.g. through according regular expressions [Palmirani et al., (2003)], we would have to take these aspects into account. For example, it could be beneficial to either slightly modify the used XML schema to better support the intended extraction. Another option could be to think about a modification of the modeling procedure and the underlying algorithms, e.g. to encode the original textual information with meta data that are targeted towards the later extraction but that do not need to be added to the RIS XML schema.
A second application example that we will discuss is based on the concept of obfuscation. Obfuscation relates to the hiding of some information parts while maintaining processability to some extent. It is typically used in software engineering for complicating reverse engineering or in data analysis for desensitizing data sets from personal information. Also in legal informatics obfuscation has been discussed, for example in the context of the Austrian transparency database [Kappl (2013)]. Also in the RIS database obfuscation occurs where personal information, e.g. from appellants who are mentioned in court decisions, needs to be removed due to data privacy so that persons cannot be directly identified. Based on the transparency function \(f^{transp}\) we can analyze the according relationships by viewing again the schema of the databases as the modeling language. Although the schema of the Austrian transparency database is – to the best of our knowledge – not publicly accessible in a technical format, the literature discussing its properties indicates that there are different views («Leistungsbereich») provided for different stakeholders [Kappl (2013)]. In addition, the actual obfuscation of personal information in the transparency database is based on specific algorithms that create encrypted, section specific identifiers («verschlüsseltes bereichsspezifisches Personenkennzeichen»). At IRIS 2012 the details as well as an enhancement of these algorithms have been presented by [Schartner (2012)]. Regarding the modeling procedure, i.e. how the data is actually entered in the database, it seems to be based on an automatic procedure that assembles the relevant information from various existing databases. Together with the interface for the transparency database as it is available for the public at https://transparenzportal.gv.at/, we can thus investigate which inferences are possible, i.e. which originals can be identified. Thereby, an interesting aspect is for example the comparison to the obfuscation used in RIS. In RIS, the names are not obfuscated using the above mentioned algorithms, but are replaced by XXX or the initials of the names – see e.g. the decisions in the judicature section of RIS at http://www.ris.bka.gv.at/Judikatur/. Therefore, a direct coupling based on personal identifiers with the information from the transparency database does not seem possible at the moment.
5.
Conclusion and Outlook ^
6.
References ^
Berbier, A., & Burger, D.,XML-Based Formats and Tools to Produce Braille Documents. In: Miesenberger, K. et al. (Eds.), ICCHP 2012, Springer, LNCS 7382, Berlin, p. 500–506 (2012).
Bork, D. & Sinz, E., Bridging the Gap from a Multi-View Modelling Method to the Design of a Multi-View Modelling Tool, to appear in: Enterprise Modeling and Information Systems Architectures (2014).
Brunschwig, C. R., Multisensory Law and Legal Informatics – A Comparison of How these Legal Disciplines Relate to Visual Law. In: Geist, A., Brunschwig, C.R., Lachmayer, F. & Schefbeck, G. (Eds.), Strukturierung der Juristischen Semantik – Structuring Legal Semantics, Festschrift für Erich Schweighofer, Editions Weblaw, Bern, p. 573–668 (2011).
Fiedler, H., Komplexitätsreduktion als Thema in Rechtstheorie und Rechtsinformatik. In: Schweighofer, E., Geist, A., Heindl, G., Szücs, C. (Eds.), Komplexitätsgrenzen der Rechtsinformatik, Boorberg Verlag, Stuttgart, p. 459–462 (2008).
Favre, J.-M., Foundations of Meta-Pyramids: Languages vs. Metamodels, In: Language Engineering for Model-driven Software Development, Dagstuhl Report, IBFI (2005).
Fill, H.-G. & Karagiannis, D., On the Conceptualisation of Modelling Methods Using the ADOxx Meta Modelling Platform. Enterprise Modelling and Information Systems Architectures, Vol. 8(1), p. 4–25 (2013).
Fill, H.-G., Redmond, T., Karagiannis, D., FDMM: A Formalism for Describing ADOxx Meta Models and Models. In: Maciaszek, L., Cuzzocrea, A., and Cordeiro, J. (Eds.), ICEIS 2012, Wroclaw, p. 133–144 (2012).
Frank, U., Some Guidelines for the Conception of Domain-Specific Modelling Languages. In: Nüttgens, M., Thomas, O., Weber, B. (Eds.), EMISA 2011, Vol. P-190, GI, p. 93–106 (2011).
Harel, D. and Rumpe B., Meaningful Modeling: What’s the Semantics of «Semantics»?, IEEE Computer, October, p. 64–72 (2004).
Kahlig, W., Visualisierungstypologie des Deutschen Privatrechts. In: Jusletter IT 24. Februar 2011, (2011).
Kappl, A., Die Österreichische Transparenzdatenbank – Die rechtlichen Rahmenbedingungen. In: Schweighofer, E., Kummer, F. & Hötzendorfer, W. (Eds.), Abstraktion und Applikation, book@ocg.at, Band 292, p. 207 (2013).
Kienreich, W., Schulze, G., Lex, E., Rapp, S., Eine Kombination von regelbasierten und statistischen Verfahren für die hierarchische Klassifikation von juristischen Dokumenten. In: Schweighofer, E., Kummer, F. & Hötzendorfer, W. (Eds.), Abstraktion und Applikation, book@ocg.at, Band 292, p. 73–77 (2013).
Karagiannis, D., Kühn, H., Metamodelling Platforms, Proceedings of the 3rd International Conference EC-Web 2002 – Dexa 2002 (2002), Full version: http://www.dke.at/fileadmin/DKEHP/publikationen/metamodell/FullVersion_MMP _DexaECWeb2002.pdf retrieved 10-01-2013.
Lachmayer, F., Schweighofer, E.,Abstraktion und Applikation. In: Schweighofer, E., Kummer, F. & Hötzendorfer, W. (Eds.), Abstraktion und Applikation, book@ocg.at, Band 292, p. 31–34 (2013).
Mylopoulos, J., Conceptual Modeling and Telos. In: Loucopoulos, P. and Zicari, R. (Eds.), Conceptual Modelling, Databases and CASE: An Integrated View of Information Systems Development, Wiley, p. 49–68 (1992).
Palmirani, M., Brighi, R., Massini, M., Automated Extraction of Normative References in Legal Texts, ICAIL’03, ACM, p. 105–106.
Schartner, P., Sicherheitsanalyse des (Wirtschafts-)Bereichsspezifischen Personenkennzeichens. In: Schweighofer, E., Kummer, F. & Hötzendorfer, W. (Eds.), Transformation juristischer Sprachen, book@ocg.at, Band 288, p. 523–528 (2012).
Stachowiak, H., Allgemeine Modelltheorie, Springer (1973).
Stöger, H., Weichsel, H., Das Redesign des Rechtsinformationssystems RIS. In: Schweighofer, E., Geist, A., Heindl, G., Szücs, C. (Eds.), Komplexitätsgrenzen der Rechtsinformatik, Boorberg Verlag, Stuttgart, p. 235–243 (2008).
Tscheliesnig, S. & Weinzettl, R., Die Österreichische Transparenzdatenbank – Ziele, Nutzen und Technische Umsetzung. In: Schweighofer, E., Kummer, F. & Hötzendorfer, W. (Eds.), Abstraktion und Applikation,book@ocg.at, Band 292, p. 203–206 (2013).
Wacker, R. & Peitz, P., Semantische Erweiterung von USDL zur Vorbereitung einer automatischen Subsumtion. In: Schweighofer, E., Kummer, F. & Hötzendorfer, W. (Eds.), Transformation juristischer Sprachen, book@ocg.at, Band 288, p. 125–130 (2012).
Weichsel, H., Rechtsinformationssystem RIS – Update 2013. In: Schweighofer, E., Kummer, F. & Hötzendorfer, W. (Eds.), Abstraktion und Applikation, book@ocg.at, Band 292, p. 53–55 (2013).
Hans-Georg Fill
Privatdozent, University of Vienna, Research Group Knowledge Engineering
Währingerstraße 29, 1090 Wien, AT
hans-georg.fill@univie.ac.at; http://homepage.dke.univie.ac.at/fill
- 1 For further information see the website of the Open Models Initiative Laboratory www.omilab.org.
- 2 See also the discussion of predicaments and subordination in Aristotle’s Categories.





