1.
Motivation ^
Zur Steigerung der Verständlichkeit von rechtlichen Sachverhalten für Rechtslaien existieren in der Rechtsinformatik vielfältige Visualisierungsansätze. Beispielsweise stellen Heddier & Knackstedt [2013] eine Möglichkeit zur Visualisierung der Sachverhalte in Handyverträgen vor. Diese und ähnliche Arbeiten beschäftigen sich jedoch häufig mit Sachverhalten, die durch statische Visualisierungen darstellbar sind.
Es existieren jedoch Situationen, in denen die Abfolge von Ereignissen von Bedeutung ist. Diese lassen sich nur schwer mit statischen Abbildungen darstellen. Die Verständlichkeit kann durch Hinzufügen von bewegten Animationen und Ton weiter gesteigert werden. Diese Tatsache wird unter anderem in Arbeiten von Brunschwig [2009/2010] unter dem Begriff multisensorisches Recht geprägt.
2.
Wissenschaftlicher Kontext ^
In den vergangenen Jahrzehnten wurden bereits einige Ansätze zur Visualisierung von textuell beschriebenen Sachverhalten vorgestellt. Ziel dieser Ansätze ist die vereinfachte Darstellung komplexer Situationen. Bereits in den 70er Jahren wurde eines der ersten Systeme vorgestellt, dass auf Basis einer textbasierten Beschreibung eine dreidimensionale Animation generiert [Kahn 1979].
Auch im Bereich der Rechtsinformatik wurde das Potential dieser Visualisierung untersucht. Beispielsweise schlagen Passera und Haapio [2011] Visualisierung in Form von Zeitstrahlen vor, um Klarheit über den zeitlichen Ablauf eines Vertrags verständlich und eindeutig zu beschreiben.
Es existieren weitere Forschungsarbeiten, die den Einsatz von grafischen Darstellungen im Bereich des Rechts für sinnvoll erachten [Ghanavati, Siena, Perini, Amyot, Peyton & Susi 2009, Tobler & Beglinger 2008, Brunschwig 2006]. Diese Ansätze gehen in den meisten Fällen von einer manuellen Erstellung der Darstellungen aus.
Die automatisierte Erzeugung von Visualisierung lässt sich zum Beispiel auf Grundlagen von Texten durchführen. Um den Text automatisiert grafisch darzustellen, muss dieser zunächst maschinell analysiert werden. In den 1940er Jahren legte Weaver [1949/1955] in den USA den Grundstein für Forschungen im Bereich der maschinellen Verarbeitung von Sprache, wobei der Fokus auf der maschinellen Übersetzung lag [Hutchins 1999].
Den aktuellen Stand der automatisierten Textanalyse stellen zum Beispiel die Applikationen der Natural Language Processing Group der Stanford Universität dar. Diese bieten beispielsweise einen Parser, der die grammatikalischen Strukturen aus Texten erkennen kann [Stanford Parser 2014].
Neben der Interpretation von Texten ist für die automatisierte Darstellung von Situationsbeschreibungen die Überführung in eine grafische Darstellungsform notwendig. Es existieren bereits Projekte, die aus textuellen Umgebungsbeschreibungen automatisiert eine dreidimensionale Darstellung generieren. Zur vereinfachten Modellierung einer dreidimensionalen Szene entwickelte AT&T Labs [Coyne & Sproat 2001] ein System, das textuelle Gegenstands- und Umgebungsbeschreibungen in eine dreidimensionale, statische Form transformiert.
Das CarSim-Projekt der Lund University [Johansson, Williams, Berglund & Nugues 2004] verfolgt einen ähnlichen Ansatz, der sich allerdings konkret auf Unfallbeschreibungen aus Zeitungsartikeln in schwedischer Sprache konzentriert. Zusätzlich zur statischen Darstellung sind hierbei auch Animationen möglich.
Diese Arbeit nutzt einen vergleichbaren Ansatz, der für textuelle Unfallbeschreibungen in englischer Sprache automatisiert eine 3D-Darstellung sowie Animation erstellt. Dabei stehen jedoch insbesondere die laiengerechte Benutzbarkeit sowie eine realistischere Simulation im Fokus. Letzteres wird durch die Verwendung einer 3D-Animationsumgebung aus der Spielebranche (vgl. u.a. [Unreal Engine 2014]), auch Spiel-Engine genannt, vereinfacht. Diese ermöglicht eine Simulation von physikalischen Gesetzmäßigkeiten sowie eine nachträgliche Bearbeitung der generierten Szenen. Der modulare Aufbau des hier vorgestellten Ansatzes erlaubt dabei auch eine Erweiterung um weitere Sprachen und Themengebiete.
3.
Generierung dreidimensionaler Darstellungen auf Grundlage textueller B ^
3.1.
Textinterpretation ^
Die Interpretation beginnt zunächst mit einer syntaktischen Analyse, die den Text in einzelne Sätze aufteilt. Anschließend wird jeder Satz wiederum in seine Satzbestandteile aufgeteilt und die Wortarten und deren grammatikalische Beziehungen zueinander durch einen sogenannten Natural Language Parser erkannt (vgl. u.a. [Stanford Parser 2014]). Zur weiteren Verarbeitung wird dessen Ausgabe zu Paaren zusammengefasst. Ein Paar besteht aus zwei Elementen, wobei ein Element entweder das Subjekt oder ein Objekt des Satzes darstellt. Einem Paar ist dabei ein Prädikat zugeordnet, welches eine Aktion zwischen beiden Elementen beschreibt.
Diese elementbasierte Betrachtung eines Textes ermöglicht anschließend eine inhaltliche Analyse. Hierbei kann auf eine Ontologie als kontextbezogene Wissensbasis zurückgegriffen werden, welche Informationen zu dem jeweiligen Thema – wie zum Beispiel Verkehrsunfälle – strukturiert speichert [Guarino, Oberle & Staab 2009]. Damit lässt sich Elementen und Beziehungen eine inhaltliche Bedeutung zuweisen.
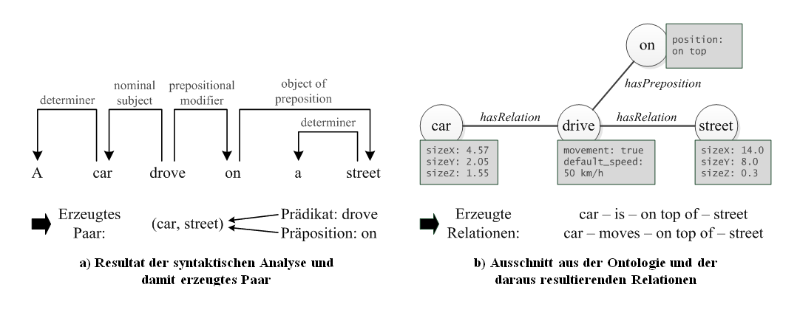
Die tabellarische Ausgabeform unterscheidet sich zum Beispiel von vorangegangenen Projekten wie CarSim, in denen die Extensible Markup Language (XML) zur Repräsentation der im Text erkannten Elemente und Aktionen verwendet wird [Johansson, Williams, Berglund & Nugues 2004].
Im zuvor erwähnten Beispielsatz initiiert die statische Relation zunächst eine zentrale Positionierung des ersten Elements, beispielsweise der Straße, im Koordinatensystem. Das nächste Element wird anhand der Relationen zum vorherigen Element ausgewählt und anschließend relativ dazu platziert. In dem genannten Beispiel wird hierdurch das Auto auf der Straße positioniert. Zusätzlich werden Wegpunkte aufgrund der Bewegungsrelation definiert. Indem das Auto später den Wegpunkten folgt, kann eine Fahrt des Autos auf der Straße dargestellt werden.

Abbildung 2 Ausschnitt aus der Erstellungs- und Nachbearbeitungsoberfläche
3.2.
Darstellung ^

Abbildung 3 Visualisierung des Eingabetextes: «A car drove on a street. There were five trees on the left side of the street. The car turned right at an intersection. There was a house on the right side of the street. The car crashed into the house.»
4.
Diskussion ^
5.
Danksagung ^
6.
Literatur ^
Brunschwig, Colette R., Visualising legal information: mind maps and e-government, In: Electronic Government, an International Journal, Band 3 – Heft 4, S. 386–403 (2006).
Brunschwig, Colette R., Rechtsvisualisierung – Skizze eines nahezu unbekannten Feldes, In: Zeitschrift für Informations-, Telekommunikations- und Medienrecht (Multimedia und Recht MMR), Heft 1, S. 9–12 (2009).
Brunschwig, Colette R., Beiträge zum Multisensorischen Recht (Multisensory Law) anlässlich des Internationalen Rechtsinformatik-Symposions 2010: ein Kommentar dazu, In: Schweighofer, Erich/Geist, Anton/Staufer, Ines (Hrsg.), Globale Sicherheit und proaktiver Staat: die Rolle der Rechtsinformatik – Tagungsband des 13. Internationalen Rechtsinformatik Symposions IRIS 2010, Österreichische Computer Gesellschaft, Wien, S. 541–548 (2010).
Coyne, Bob/Sproat, Richard, WordsEye: An Automatic Text-to-scene Conversion System, In: Pocock, Lynn (Hrsg.), Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, ACM Press, New York, S. 487–496 (2001).
Ghanavati, Sepideh/Siena, Alberto/Perini, Anna/Amyot, Daniel/Peyton, Liam/Susi, Angelo, A Legal Perspective on Business: Modeling the Impact of Law, In: Babin, Gilbert/Kropf, Peter/Weiss, Michael (Hrsg.), E-Technologies: Innovation in an Open World, Springer, Berlin, S. 267–278 (2009).
Guarino, Nicola/Oberle, Daniel/Staab, Steffen, What Is an Ontology?, In: Staab, Steffen/Studer, Rudi (Hrsg.), Handbook on Ontologies, Springer-Verlag, Berlin, S. 1–17 (2009).
Heddier, Heddier/Knackstedt, Ralf, Empirische Evaluation von Rechtsvisualisierungen am Beispiel von Handyverträgen, In: Schweighofer, Erich/Kummer, Franz/Hötzendorfer, Walter (Hrsg.), Abstraktion und Applikation – Tagungsband des 16. Internationalen Rechtsinformatik Symposions IRIS 2013, Österreichische Computer Gesellschaft, Wien, S. 413–420 (2013).
Hutchins, John, Retrospect and Prospect in Computer-Based Translation, In: Proceedings of MT Summit VII «MT in the great translation era», Singapore, S. 30–34 (1999).
Johansson, Richard/Williams, David/Berglund, Anders/Nugues, Pierre, Carsim: A System to Visualize Written Road Accident Reports as Animated 3D Scenes, In: Hirst, Graeme/Nirenburg, Sergei (Hrsg.), Proceedings of the 2nd Workshop on Text Meaning and Interpretation, Association for Computational Linguistics, Barcelona, S. 57–64 (2004).
Kahn, Kenneth Michael, Creation of Computer Animation from Story Descriptions, Massachusetts Institute of Technology. – Dept. of Electrical Engineering and Computer Science, 1979.
Passera, Stefania/Haapio, Helena, Facilitating Collaboration Through Contract Visualization and Modularization, In: Dittmar, Anke/Forbrig, Peter (Hrsg.), Proceedings of the 29th Annual European Conference on Cognitive Ergonomics, ECCE, Rostock, S. 57–60 (2011).
Tobler, Christa/Beglinger, Jacques, Das EUR-Charts-Projekt oder: The Making of «Essential EC Law in Charts»: Visualisierung eines Rechtsgebietes am Beispiel des Rechts der Europäischen Union, In: Schweighofer, Erich/Geist, Anton/Heindl, Gisela (Hrsg.), Komplexitätsgrenzen der Rechtsinformatik – Tagungsband des 11. Internationalen Rechtsinformatik Symposions IRIS 2008, Richard Boorberg Verlag, Stuttgart, S. 531–539 (2008).
Stanford Parser, http://nlp.stanford.edu/software/lex-parser.shtml, abgerufen am: 2. Januar 2014.
Unreal Engine, http://www.unrealengine.com/, abgerufen am: 2. Januar 2014.
Weaver, Warren, Translation, In: Locke, William Nash/Booth, Andrew Donald (Hrsg.), Machine translation of languages: fourteen essays, Technology Press of the Massachusetts Institute of Technology and Wiley, New York, S. 15–23 (1955).
Matthias Carnein
Studentische Hilfskraft
matthias.carnein@uni-muenster.de
Erwin Quiring
Wissenschaftliche Hilfskraft
Andreas Haack
Student
Andreas Möhring
Student
Jörg Becker
Professor am Lehrstuhl für Wirtschaftsinformatik und Informationsmanagement, Universität Münster, European Research Center for Information Systems (ERCIS), Institut für Wirtschaftsinformatik
Leonardo-Campus 3, 48149 Münster, DE
becker@ercis.uni-muenster.de





