1.
The functions of an information system ^
Any information system has to support three functions:
- A retrieval function
- A relevance function
- A source function
The relevance function is an auxiliary function, it is features of the document or the information system which make it easier – more efficient – for the user to determine the relevance4 of a document. In the document, relevance functions are typically enabled by the inclusion of an abstract, and user research has demonstrated that this is rather efficient, especially for excluding non-relevant documents.5 Occasionally, elements of the authentic form have been designed to assist relevance assessment, typically headings. A system function assisting relevance assessment is what often is known as a focus-function,6 the system let the user read a document by homing in on the specified search terms identified in the document, as this makes it easier for the user to determine whether the term occurs in a context relevant for his or her problem. The relevance of a document can finally only be determined by referring to the authentic form, and it should be emphasised that the relevance assessment is not objective, but will be relative both to user and context.7
2.
Hyperlink and indexes ^
| [indexing term1] * [page in the book1] [indexing term2] * [page in the book2] [indexing term3] * [page in the book3] |
[indexing term1] * [page in the book1], [page in the book 2] | >/tr>
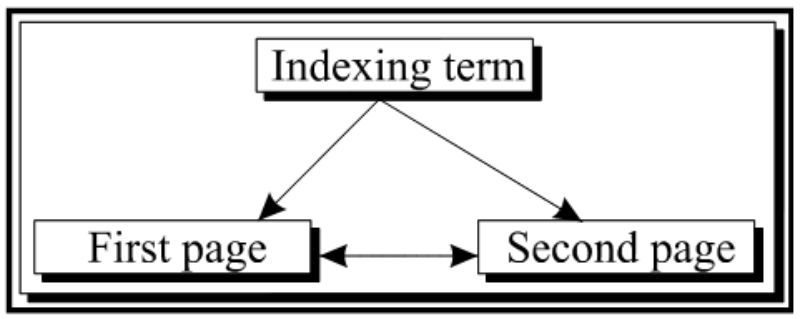
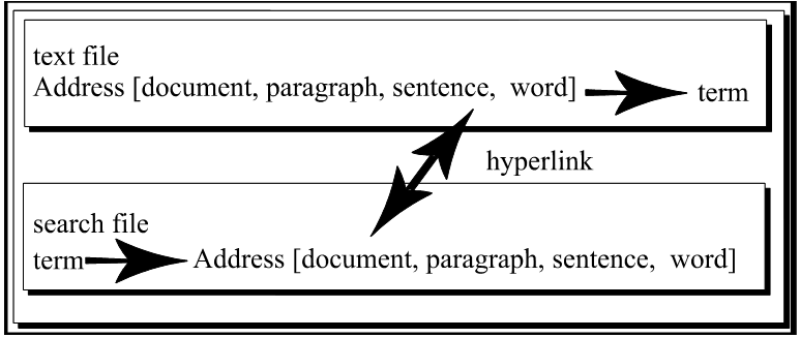
3.1.
Introduction ^
- Alphabetical indexes
- Systematic indexes
- Citation indexes
One should also make the distinction between indexes using a pre-defined set of indexing terms, generally known as a thesaurus.10
3.2.
Alphabetical indexes ^
Even using a controlled indexing vocabulary, consistency remains a problem.12 Also, the thesaurus need to be maintained in order to reflect new knowledge, new trends and re-evaluation of relations between terms. The resources necessary for maintaining the thesaurus should not be underestimated. Also, the process of intellectual indexing itself requires high competence by the indexers, and is time-consuming, even when computer aided.
This can in the legal domain be exemplified by the competition between Mead Data Central and West Publishing Company. Mead’s system, Lexis, did include little or none intellectual indexing, while West relied heavily on its Key Number System to the extent that when Westlaw first was introduced in 1975, it was based on headnotes and the numbers, leaving the user to look up the authentic text in one of the case reporters. This actually both reduced retrieval performance, and impaired the source function compared to the competitor, Lexis, and lead to West changing its policy in 1978, also including the authentic text of the case.
One way of utilising the vocabulary to create a type of hyper-structure, is systems based on connectionism or neural networks.16 In this approach, a document is represented as a weighted graph. The identification of the document is one node, the different words of the documents in the database is a dimension of other nodes, and other dimensions may be the authors, statutory citations, etc.

The method is related with other strategies for enhancing performance (especially recall) is that of relevance feedback, perhaps especially the «local metrical feedback» suggested by Attar and Fraenkel.17 Using an initial traditional search request, a part of the text of the retrieved documents (this part being words within a certain distance form the search terms, explaining the «metrical» element in the method) was examined by statistical means, and terms occurring with a certain significance in the identified parts would be included in a new search request, retrieving additional documents. This could also go on for several cycles, and might be represented in a hyper-structure similar to the one suggested above.
Norway is basically divided into territories (mainland, continental shelf, Spitzbergen, and a few other odd islands in the Arctic and Antarctic regions). The mainland is divided into counties, the counties into municipalities.18 Towns, railway stations, lakes etc may be related to municipalities. Regrettably, the administrative division of the country is not this simple, for different purposes, more than 20 ways of dividing the country prevail – harbour districts, parishes, court jurisdictions, midwife districts, environmental zones along watercourses, natural parks, etc. The mapping of different features onto this rather complex structure is not trivial, and would certainly be even more complex for countries with a more sophisticated administrative structure, for instance a federal structure.
An early example of trying to define such a micro vocabulary, were the attempts to find an algorithm which would qualify statutory definitions. If such a definition was identified, it would then be possible to set up – at least within the statute (or regulation) – intra-documentary links to those provisions using the defined term.20 A major example is the early work of Niblett and Nunn-Price on the British STATUS21 project, where a DEFINE function was included of the following structure:
| [defined term] AND (mean OR means OR meaning OR include OR includes OR defined OR definitions OR deemed OR construed)(+12, –12). |
A special use of this possibility is demonstrated by one of the (rather few) systems for conceptual text retrieval, RUBRIC.24 In this system, a semantic representation of the domain25 is constructed in the tradition of conventional knowledge based systems. A link is determined between the knowledge based structure and the authentic text of the document by using «evidence rules». For instance, one of the concepts in the semantic structure is the concept of an offer being «friendly». For this there is constructed a evidence rule determining whether a certain document should be considered to fulfil this requirement:
| (Evidence friendly
|
3.3.
Systematic indexes ^
|
3.4.
Citation indexes ^
Citation indexes are also well known outside the legal domain. Using a standard work within the domain addressing a certain issue, the index will list subsequent works citing this work, and in this way provide a perspective on the domain.30 A well-published system is the Science Citation Index (SCI).31 Within law, Shephard’s is perhaps the best known citation index, having given rise to the verb shepardizing (which also is a trade mark) for use of the index.
Frank Shepard32 was a young salseperson working for the legal publisher EB Meyer & Co in Chicago. He was not a lawyer himself, but in his work, be became familiar with the problems lawyers encountered in legal research. He noted the importance of precedents within US law, and observed that many lawyers would jot citations to subsequent decisions in the margin of their case reporters. He started by examining decisions from Illinois, and noted the precedents cited, which he printed on labels which could be pasted into the margins of the case reporters, in this way replacing the hand-written notes. Shephard’s Adhesive Annotations were first published in 1873, and was at once successful. Shephard soon worked full time on his project, expanding the system to other states. He lived to see his system becoming indispensable for lawyers, his files have bountiful evidence of how useful lawyers found his system, Oliver Wendell Holmes, jr wrote for instance to him and stated that he found the system the greatest simplification of lawyers work ever. He died at his desk 28 September 1900, and was followed by his brother in law, Reid A Kathan, who replaced the labels by a book publication – a red leather bound book with one single word on the cover: Shepard. Kathan was followed by William Gutherie Packard («Pack») in 1929, and though there now were competitors in the market, Shepard remained leader.
When a factory for bomb sights was extended during the Second World War, the company had to move. During two years, the operation was moved to Colorado Springs, it is maintained that this not only was due to the central location within the country, but because Packard wanted to locate the company as far from the coast as possible to reduce the peril of enemy air attacks, and because he was a dedicated outdoor person. The removal load was 23 railway carriages, and the property of 40 families filled another 20. The weight of the lead type was 250 tons, and the type was moved without a single line being misplaced – or a single edition delayed.
In 1966, Shephard became a wholly owned subsidiary of McGraw Hill, and in 1990 the company moved to new facilities specially designed for an information technology infrastructure with some 100 kilometres of fibre optic cable and a database of 64 billion bytes, holding the citations of 5 million cases. Today, Shepard is integrated with legal on-line services – citations are updated with a maximum delay of 48 hours counting from the time the decision is handed down.
The more extensive study of case citations as a hyperstructure is made by Tapper.34 The objective of the study was by taking a current case, to find other «relevant» cases. The method proposed was an version of a vector system. In the vector systems generally applied to legal research, each document is represented in n-dimesjonal space, «n» being the number of different words in the database, and each element of the vector (representing a word) is assigned a value, either «0» for a word not occurring in the document, or a value, typically the frequency of the word in that document. «Similarity» between documents is then measured by the angle between the vectors, typically using a cosine function.
In Tapper’s study, the vectors was made up of the case citations occurring in the cases. Also, different methods for comparing similarity were explored. In this, and pertinent to our discussion, is the semantic interpretation made of citations. In assigning values to the vector elements, consideration was made of several aspects of the case:35
- Age: The older the case, the higher the value (the year of the cited cases was subtracted from the year of the experimental data – 1974 – and rounded down to the nearest whole number).
- Jurisdiction: The more remote the jurisdiction, the higher the value. For the American material,36 the jurisdictional value was nil if the cited case was decided by the Supreme Court or the same Circuit Court, ten if it was decided by a court of a different circuit, and twenty if it was decided by a state court. In the English material,37 the value was nil for any English or Welsh cases, ten for any other jurisdiction.
- Hierarchical value: In the American material, this was ten for the Supreme Court, twenty for the Court of Appeals, and thirty for Federal District courts with broadly similar rules for the state court. In the English material, decisions by the House of Lords was assigned the value ten, the Court of Appeal the value twenty and the High Court the value thirty.
- Frequency: The number of occurrences of the citation in the current case.
The experiment has demonstrated that this approach is promising. As Tapper concludes:38
«It is possible to summarise the position by asserting that the research described in this paper has elaborated and vindicated the technique of using citation vectors. It still remains to be perfected.»
- Authentic citations are those which are embedded in the text of the legal source itself. They have the same legal authority as the text, a statutory citation in the text of one statutory provisions incorporate the cited provision in the citing provision, and may be an alternative to statutory definitions. Editorial citations are those added by the editor of a compilation of statues in force or other publication, they are a special example of legal literature, representing the opinion of the editor that there is a certain relation between the two provisions – often the editorial citation is just a mirror of the authentic citation in another provision: Section A includes an authentic citation to Section B, but Section B does not cite Section A – this is then made explicit by the editor including an editorial citation from Section B to Section A. Taken as a whole, one will find that statutory citation structures tend to be symmetric.
- Intra- and inter-regulatory citations. There will be citations between provisions within the regulation, while others will be between different regulations. The intra-regulatory citations are only one of several important structural elements in a regulation, another important structure is the sequence of provisions, as there often are implied links between adjoining provisions.39
4.
Memex ^
«Consider a future device for individual use, which is a sort of mechanized private file and library. It needs a name, and to coin one at random, «memex’» will do. A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.
It consists of a desk, and while it can presumably be operated from a distance, it is primarily the piece of furniture at which he works. On the top are slanting translucent screens, on which material can be projected for convenient reading. There is a keyboard, and sets of buttons and levers. Otherwise it looks like an ordinary desk.
In one end is the stored material. The matter of bulk is well taken care of by improved microfilm. Only a small part of the interior of the memex is devoted to storage, the rest to mechanism. Yet if the user inserted 5000 pages of material a day it would take him hundreds of years to fill the repository, so he can be profligate and enter material freely.
Most of the memex contents are purchased on microfilm ready for insertion. Books of all sorts, pictures, current periodicals, newspapers, are thus obtained and dropped into place. Business correspondence takes the same path. And there is provision for direct entry. On the top of the memex is a transparent platen. On this are placed longhand notes, photographs, memoranda, all sort of things. When one is in place, the depression of a lever causes it to be photographed onto the next blank space in a section of the memex film, dry photography being employed.
There is, of course, provision for consultation of the record by the usual scheme of indexing. If the user wishes to consult a certain book, he taps its code on the keyboard, and the title page of the book promptly appears before him, projected onto one of his viewing positions. Frequently-used codes are mnemonic, so that he seldom consults his code book; but when he does, a single tap of a key projects it for his use. Moreover, he has supplemental levers. On deflecting one of these levers to the right he runs through the book before him, each page in turn being projected at a speed which just allows a recognizing glance at each. If he deflects it further to the right, he steps through the book 10 pages at a time; still further at 100 pages at a time. Deflection to the left gives him the same control backwards.
A special button transfers him immediately to the first page of the index. Any given book of his library can thus be called up and consulted with far greater facility than if it were taken from a shelf. As he has several projection positions, he can leave one item in position while he calls up another. He can add marginal notes and comments, taking advantage of one possible type of dry photography, and it could even be arranged so that he can do this by a stylus scheme, such as is now employed in the telautograph seen in railroad waiting rooms, just as though he had the physical page before him.»
When text retrieval systems came along, many hailed these as the realisation of the memex devices envisioned by Bush.42 The same happened when hyperlinks became popular within the context of World-Wide Web.43 In this paper, an attempt has been made to indicate that both approaches basically rely on the same considerations – either relying on intellectual indexing or using syntactic features of the document to establish a link which can be given a semantic interpretation. Hyperlinks assigned on the basis of an intellectual effort on behalf of the person designing a web-page has the same advantages and disadvantages as traditional intellectual indexing: They may be based on an expert opinion, and therefor of great value to the user, but the reason for the link to be established may not be self-evident, and based on a gut feeling rather than any principles which has been, or easily may be made explicit – the relation will often be described by the two documents being «important» or «interesting» or even «relevant» (whatever that may be taken to mean) with respect to each other. The hyper-links also are messy to maintain.
Jon Bing
Norwegian Research Center for Computers and Law
Faculty of Law, University of Oslo
PO Box 6702 St Olavs plass, N-0130 OSLO, Norway
- 1 But one should bear in mind that the functions may be implemented by separate systems interacting to create one complete information system. Typically, the library has a card catalogue with brief entries for each document in its files, computerised or manual. This will enable the user to retrieve documents, and make a preliminary relevance assessment based on the title and, perhaps, a brief abstract of the document. But in order to satisfy the source function, the user has to leave the catalogue and walk along the shelves in order to find the physical publication – or, the user may have to make an inter-library loan in order to satisfy the source function. In such a composite information system, the retrieval and relevance functions may be rather efficient, while the source function is somewhat more cumbersome and costly.
- 2 This paper will restrict itself to examples from the legal domain.
- 3 With some qualifications, most jurisdictions will allow the user to base arguments on consolidated versions of legislation, where amending statutes or regulations have been edited into the amended statute or regulation.
- 4 «Relevance» is a concept used in many different meanings in the literature of information systems, often in a rather informal way. In this paper, an attempt is made to restrict the use of «relevance» to the situation where an argument derived from a document contributes towards the legal decision. It is a binary concept, a document either is or is not relevant in this terminology. Grading is reserved from the derived argument, which will have a relative weight with respect to other arguments available in the decision process. The weight is determined by several factors, two major factors will be the rank of the type of legal sources (typically statutes ranked above regulations), and the proximity of the facts of the argument to the facts of the issue which is to be decided. How to consolidate a decisions with conflicting arguments will not be discussed in this paper.
- 5 Cf Jon Bing Handbook of Legal Information Retrieval, North-Holland, Amsterdam 1984:93–96 with references.
- 6 It really is similar to the even more traditional KWIC-format (key words in context).
- 7 Not only the context of the problem, but also the context of the other documents appreciated by the user.
- 8 But it may refer to an element of the page, typically a footnote or a figure.
- 9 In principle the user reads sequentially, but typically the experienced user has acquired reading skills which allow him or her just to «glance» at the page to determine the relevant passage.
- 10 «Thesaurus» is a term used with slightly different meanings. Often it refers to a dictionary that when the user looks up a certain term, it will specify synonyms or related terms in the natural language – as the thesaurus tool for English in a word processing program like MS Word. In information retrieval, it is also often used for a list that takes words of the search request as input, and expands these words by what is defined as synonyms or near synonyms – in this way, thesaurus is used in important examples of legal information retrieval systems, like the former and quite famous function of the ITAGIURE system. Such «search theauri» provides a post co-ordination of the search request, and is in principle rather different from the thesauri discussed here, which provided ante co-ordination of indexing the documents themselves. Obviously, such thesauri also may be useful to consult when specifying a search request, but that is nearly just a side-effect of their use.
- 11 This would allow the user to move up or along such links for retrieval, actually providing intra-hyperlinks within the index, cf below.
- 12 A detailed example is the MEDLARS evaluation (1966–1967), cf Jon Bing Handbook of Legal Information Retrieval, North-Holland, Amsterdam 1984:214–216.
- 13 Often called «full text retrieval». The «full text» usually indicated the form of the document to be indexed, indicated that this is the authentic text (as formulated by the original author, court or regulator) in contrast to an abbreviated form of the text (like an abstract). In this paper, the term «text retrieval» is used for the method, while the type of document indexed will be specified (or implied).
- 14 Jon Bing Handbook of Legal Information Retrieval, North-Holland, Amsterdam 1984:246.
- 15 Jon Bing and Trygve Harvold Rettskildebruk og informasjonssystemer, Papers on Computers and Law 2a, Oslo 1973:192–195.
- 16 The example is based on Adaptive Information Retrieval, a system described by Richard K Belew «A Connectionist Approach to Conceptual Information Retrieval», Proceedings of the first iternational conference on artificial intelligence in law, ACM Press, New York 1987:116–126. The most comprehensive discussion may be found in Daniel E Rose A Symbolic and Connectionist Approach to Legal Information Retrieval, Lawrence Erlbaum Associates, Publishers. Hillsdale NJ (1994). The simple example in the text should be sufficient to illustrate the possibilities.
- 17 Jon Bing Handbook of Legal Information Retrieval, North-Holland, Amsterdam 1984:232 with references.
- 18 «Fylker» and «kommuner».
- 19 This would not be difficult, as the structure of a decision generally will have a paragraph containing the names of the parties which can be identified, even if this paragraph is not explicitly tagged.
- 20 Cf for instance GBF Niblett and NH Price The STATUS Project: Searching Atomic Energy Law by Computer, Culham Laboratories, 1969 and «Mechanized searching of Acts of Parliament», Information Storage and Retrieval 1970:269.
- 21 STATUS was probably the first portable text retrieval system, written in FORTRAN.
- 22 The total length of this legislation was 138,661 words.
- 23 Jon Bing and Trygve Harvold Rettskildebruk og informasjonssystemer, Papers on Computers and Law 2a, Oslo 1973:178.
- 24 Cf Jon Bing Conceptual Text Retrieval, CompLex 9/88, Tano, Oslo 1988:20–24 with references.
- 25 The domain in question was that of corporate mergers and acquisitions.
- 26 The structure is imbedded in the bibliographical program BibJure developed by Pål A Bertnes and marketed by DIAGNOSTICA. In the original, the slots 1-3 and 6 are open (certainly for good reasons, but not obvious to the author), therefore the last category in the original is numbered 30.
- 27 In the original, the titles are organised alphabetically, by translation into English, this is obviously corrupted, it has been re-organised for the benefit of the example, but the numbers do for this reason not correspond to those of the original.
- 28 And the author should hasten to add that the cause may be inadequate translations of the brief captions in the structure.
- 29 Often used to produce manual or back-in-the-book indexes for the material in addition to the use in the computerised system.
- 30 Cf for instance Th P Loosjes On Documentation of Scientific Literature, Butterworths, London 1967.
- 31 SCI is founded by Eugene Garfield, who discusses his approach for instance in The Foundation to Access to Knowledge, Sycaruse University 1968:169–196.
- 32 This anecdotal material is mainly based on material made available by Shepard at http://www.lawtown.com/ccentral/ccentral.html.
- 33 The author acknowledges that this strategy has been brought to his attention by the Norwegian national legal information service provider, Lovdata, which have implemented this in their system based on the text retrieval program SIFT and the user interface SIR. It is not only implemented for case citations, as the discussion in the text may imply, but also for citations of and between statutes and regulations.
- 34 Cf Colin Tapper An Experiment in the Use of Citation Vectors in the Area of legal Data, CompLex 9/82, Scandinavian University Press, Oslo 1982. The work reported in this publication follows work completed at Stanford University in 1976.
- 35 Cf Colin Tapper An Experiment in the Use of Citation Vectors in the Area of legal Data, CompLex 9/82, Scandinavian University Press, Oslo 1982:3.
- 36 Volume 500 of the Federal Reporter (Second series), covering part of 1974, totalling 248 cases on 1.397 pages.
- 37 Queen Bench Reports for 1974, 67 cases on 837 pages.
- 38 Cf Colin Tapper An Experiment in the Use of Citation Vectors in the Area of legal Data, CompLex 9/82, Scandinavian University Press, Oslo 1982:101.
- 39 In text retrieval systems, a provision is generally qualified as a document. If a provision is retrieved, it is necessary for the system to support some method for being able to jump to the preceding or following provisions, which typically will not be part of the answer set. Surprisingly many text retrieval systems do not offer this control structure, which in principle is a hyper-structure in the regulatory material.
- 40 Vannevar Bush was president of the Carneigie Institution of Washington from 1939–1955.
- 41 Atlantic Monthly July 1945, cf also http://www.isg.sfu.ca/~duchier/misc/vbush.
- 42 Lewis O Kelso may be the first to suggest creating an automatic retrieval system to assist legal research in «Does the Law need a technical Revolution?», Rocky Mountain Law Review, cf Reed C Lawlor «Information technology and law», Advances in Computers 1962:310. Kelso was inspired by Bush’s suggestion.
- 43 Cf Tor Nørretranders Stedet som ikke er, Aschehoug, Copenhagen 1997:75.





