1.
Introduction ^
2.
Big Open Legal Data (BOLD) ^
Legal data, narrowly conceived, consists of two types of BOLD objects:
- structured texts, hierarchically decomposable into chains of text fragments, and
- metadata about texts and text fragments;
- labeled links between texts fragments, and
- arbitrarily complex features of texts and text fragments.
- On the item level legal texts and text fragments can be dereferenced by identifier and copied, resulting in a new item;
- On the manifestation level any change to the data produces a new manifestation, including a change of data format, annotation of structure, or the embedding of metadata;
- On the expression level only a change of the text by its author produces a new expression;
- On the work level a text is identified by the details of its publication: as long as the title, author, and publication date remain the same, expressions are versions of the same work.
2.1.
Versioning ^
2.2.
Languages ^
2.3.
References ^
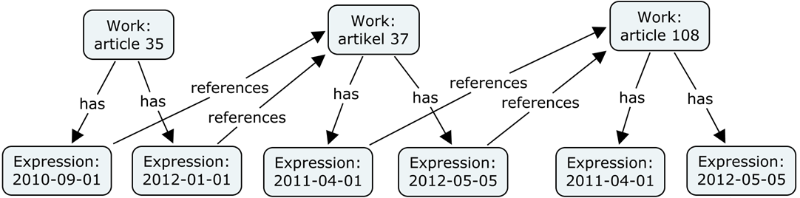
Figure 1: Example of dynamic references in regulatory text. The work ‹article 35› has two expressions; both refer to the work level of article 37. The actual references can only occur in a manifestation of an expression (e.g. an XML file) and be seen by a user in a physical item on for instance her computer.
2.4.
Mixed content and quoting ^
3.
Dutch Official Portals for Law ^
3.1.
Wetten.nl ^

Figure 2: Interface of Dutch legislative portal. The user is focussing on article 35 of immigration law.
3.2.
Rechtspraak.nl ^
- The date of the decision («Datum uitspraak»)
- The field(s) of law («Rechtsgebieden»)
- The court («Instantie»).
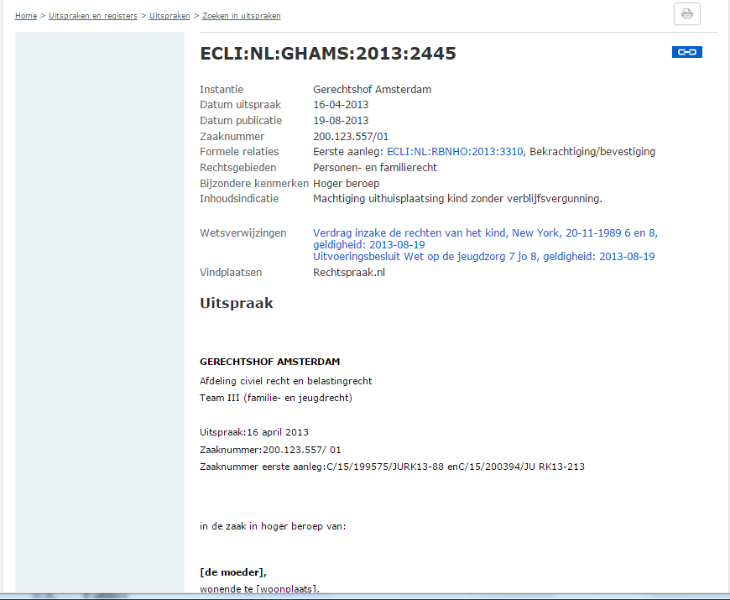
Figure 3: Interface of case law portal.
4.
Creating a Network of Legal Data ^
4.1.
User initiated linking ^
- Permitting user communities to freely organize themselves, to freely share information with the agents of their choice, excluding others, and to freely exclude information from view that they deem irrelevant or of low quality;
- On the other hand, providing incentives to share information that they produce as widely as possible, as implied by the open legal data concept;
- And finally, determining the relevance of information for specific agents, addressing both the general quality of information (or the confidence in the skills of its producer) and specific agent information needs.
4.1.1.
Folders, shopping carts, and shopping lists ^
4.2.
Automatic Linking of Sources of Law ^
Here we will describe how we find and resolve the references to legislation in case law and how we create an integrated network of Dutch sources of law and use this to suggest possibly interesting documents to users of a legislative portal. We chose to work with a subset of all case law to start with; those cases that were tagged as belonging to «immigration law». That gave us 13,311 documents to work with.
4.2.1.
Locating and resolving references ^
5.
A Prototype Legal Recommender System for Dutch Law ^
- The system checks whether the article appears in the case law network. If so, it creates a so-called ego graph, a local network containing all the nodes and edges within a certain weighted distance from the current node (Newman, 2010). We start searching with a weighted distance of 0.4 and gradually increase it up to 2.0 until we have a sufficiently large, but still manageable network.
- To find relevant legislation, the system also checks whether the current node is in the legislative network of the MetaLex document server. If so, it again creates an ego graph, this time for an unweighted network. To control the size of the graph, we use only references coming from the selected version (expression) of the current node.
- If we have two local networks, we want to combine them in order to (better) predict the importance of legislative nodes. To do this, we need to assign weights to the legislative graph. We chose the value 0.1 as it allows the legislative network to influence the result but not overrule the case law references.
- Finally, we use betweenness centrality on the combined network to determine the most relevant articles for the current focus. The betweenness centrality of a node is the sum of the fraction of all-pairs shortest paths that pass through that node. The results are shown to the user in the top of frame A of Figure 4.
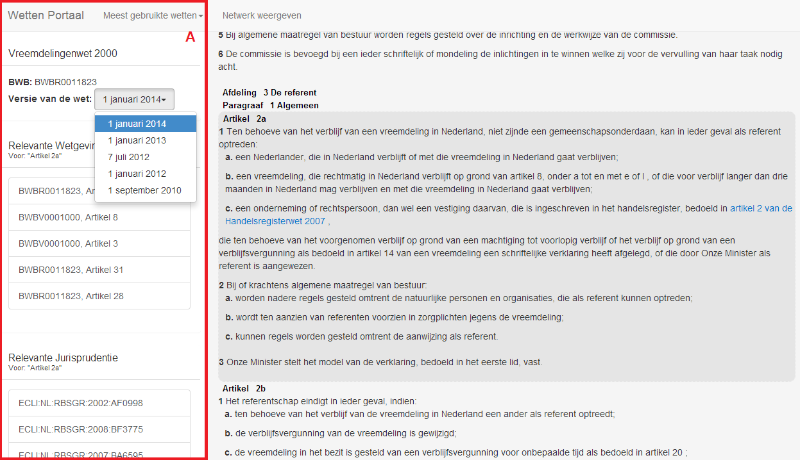
Figure 4: The prototype legal recommender system. The user has article 2a of the Immigration law in focus. Current version is January 2014 (see pull-down menu at left). Relevant other articles are presented in window A (red or dark border) on the left and below that relevant case law.
5.1.
A First Evaluation ^
6.
Conclusions ^
7.
Acknowledgements ^
8.
References ^
Hoekstra, R., The MetaLex Document Server – Legal Documents as Versioned Linked Data, pp. 128–143. Springer (2011).
Maat, E. de, Winkels, R., and Engers, T. van., Automated detection of reference structures in law. In T. van Engers (ed), JURIX 2006, IOS Press, Amsterdam, pp. 41–50 (2006).
Newman, M., Networks: An Introduction. Oxford, England: Oxford University Press (2010).
Saur, K.G., Functional requirements for bibliographic records. UBCIM Publications – IFLA Section on Cataloguing, 19 (1998).
Wass, C., Dini, P., Eiser, T., Heistracher, Th., Lampoltshammer, Th., Marcon, G., Sageder, C., Tsiavos, P. and Winkels, R., OpenLaws.eu. Proceedings of the 16th International Legal Informatics Symposium IRIS 2013, Salzburg, Austria (2013).
Winkels, R.G.F., Boer, A. and Plantevin, I., Creating Context Networks in Dutch Legislation. In K. Ashley (ed). Legal Knowledge and Information Systems. JURIX 2013. IOS Press, Amsterdam, pp. 155–164 (2013).
Winkels, R.G.F., de Ruyter, J. & Kroese, H., Determining Authority of Dutch Case Law. In K. Atkinson (ed). JURIX 2011: The Twenty-Fourth International Conference. Volume 235 of Frontiers in Artificial Intelligence and Applications, IOS Press, Amsterdam, pp. 103–112 (2011).
Radboud Winkels, Associate Professor, University of Amsterdam, Leibniz Center for Law, PO Box 1030, 1000 BA Amsterdam, NL, winkels@uva.nl; http://www.leibnizcenter.org/~winkels/
- 1 In a metadata element in the header of the document that contains the «main» article(s) for the decision, not in the running text.
- 2 http://doc.metalex.eu/.
- 3 The more recent cases contain more explicit links.
- 4 «European Case Law Identifier»; see Council conclusions on ECLI at: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:52011XG0429(01).





